 云计算服务
云计算服务
 服务器租用
服务器租用
 DDOS 防护
DDOS 防护
 虚拟主机
虚拟主机
 域名服务
域名服务
 基础设施
基础设施
 关于我们
关于我们
云服务器运行速度变慢或云服务器突然出现网络断开,可能是云服务器的带宽和 CPU 利用率过高导致。恒创科技服务器控制台已内置 CPU 和流量监控图供您查看。您可以参考如下步骤排查占用过高问题:
问题定位
定位影响云服务器带宽和CPU利用率高的进程。
Windows 操作系统本身提供较多工具可以定位问题,包括任务管理器、性能监视器(Performance Monitor)、资源监视器(Resource Monitor)、Process Explorer、Xperf (Windows server 2008 以后)和抓取系统 Full Memory Dump检查。在流量大的情况下,您还可以使用 Wireshark 抓取一段时间的网络包,分析流量使用情况。
问题排查步骤
常用命令
本文相关操作命令以 CentOS 7.2 64 位操作系统为例。其它版本的 Linux 操作系统命令可能有所差异,具体情况请参阅相应操作系统的官方文档。
Linux 云服务器查看 CPU 使用率等性能相关问题时的常用命令如下:
○ ps -aux
○ ps -ef
○ top
CPU 占用率高的问题定位
1. 使用 VNC 远程登录云服务器。
2. 执行如下命令查看当前系统的运行状态:
top
系统回显:
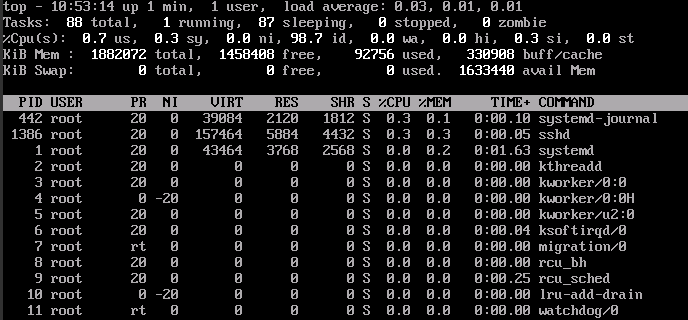
3. 查看显示结果。
● 命令回显第一行:10:53:14 up 1 min,1 user, load average: 0.03, 0.01, 0.01 的字段含义如下:系统当前时间为 10:53:14,该云服务器已运行 1 分钟,当前共有 1 个用户登录, 最近 1 分钟、最近 5 分钟和最近15 分钟的 CPU 平均负载。
● 命令回显第三行:CPU 资源总体使用情况。
● 命令回显第四行:内存资源总体使用情况。
● 回显最下方显示各进程的资源占用情况。说明:
● 在 top 页面,可以直接输入小写“q”或者在键盘上按“Ctrl+C”退出。
● 在top运行中常用的内容命令如下:
○ s:改变画面更新频率。
○ l:关闭或开启第一部分第一行 top 信息的表示。
○ t:关闭或开启第一部分第二行 Tasks 和第三行 Cpus 信息的表示。
○ m:关闭或开启第一部分第四行 Mem 和 第五行 Swap 信息的表示。
○ N:以 PID 的大小的顺序排列进程列表。
○ P:以 CPU 占用率大小的顺序排列进程列表。
○ M:以内存占用率大小的顺序排列进程列表。
○ h:显示命令帮助。
○ n:设置在进程列表所显示进程的数量。
4. 通过 /proc/PID/exe 命令可以查看每个进程 ID 对应的程序文件。

问题处理
判断造成 CPU 或带宽占用率高的进程属于正常进程还是异常进程,并分类进行处理。
● 正常进程:优化程序,或 变更云服务器规格。
● 异常进程:建议手动关闭进程,您也可以借助第三方工具关闭进程。
CPU 使用率高的问题处理
对于导致 CPU 使用率高的具体进程,如果确认是异常进程,可以直接通过 top 命令终止进程。对于 kswapd0 进程导致的 CPU 使用率高的问题,则需要对应用程序进行优化,或者通过增加内存进行云服务器规格的升级。
注:kswapd0 是系统的虚拟内存管理程序,如果物理内存不够用,系统就会唤醒 kswapd0 进程,由 kswapd0 分配磁盘交换空间用作缓存,因而占用大量的 CPU 资源。
您可以直接在 top 运行界面快速终止相应的异常进程。操作步骤如下:
1. 在 top 命令运行的同时,按下小写的【k】键。
2. 输入要终止进程的 PID。进程的 PID 为 top 命令回显的第一列数值。例如,要终止 PID 为 108 的进程,直接输入【108】后回车。
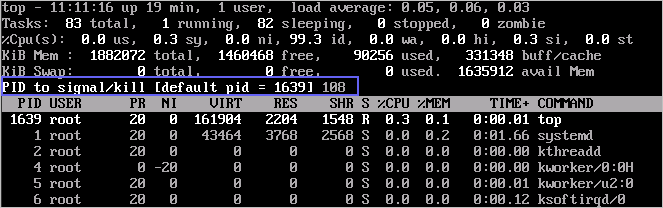
3. 操作成功后,会出现如下图所示类似信息,按回车确认。
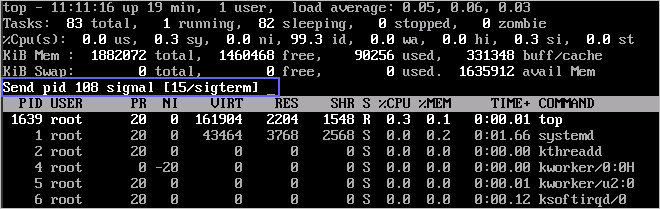
kswapd0 进程占用导致 CPU 使用率高,可以通过以下步骤排查进程的内存占用情况。
1. 通过 top 命令查看 kswapd0 进程的资源使用。
2. 如果 kswapd0 进程持续处于非睡眠状态,且运行时间较长,可以初步判定系统在持续的进行换页操作,可以将问题转向内存不足的原因来排查。
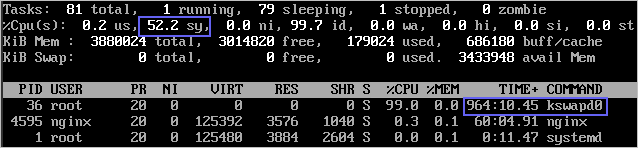
3. 通过 vmstat 命令进一步查看系统虚拟内存的使用情况。如果 si 和 so 的值也比较高,说明系统存在频繁的换页操作,系统物理内存不足。
● si:每秒从交换区写到内存的大小,由磁盘调入内存。
● so:每秒写入交换区的内存大小,由内存调入磁盘。
4. 对于内存不足问题,可以通过 free、ps 等命令进一步查询系统及系统内进程的内存占用情况,做进一步排查分析。
5. 临时可通过在业务空闲期重启应用或者系统释放内存。如果要从根本上解决内存不足的问题,需要对服务器内存进行扩容,扩大内存空间。如果不具备扩容的条件,可通过优化应用程序,以及配置使用大页内存来进行缓解。
带宽使用率高的问题定位和处理
如果是正常业务访问以及正常应用进程导致的带宽使用率高,需要升级服务器的带宽进行解决。如果是非正常访问,如某些特定 IP 的恶意访问,或者服务器遭受到了 CC 攻击。或者异常进程导致的带宽使用率高。可以通过流量监控工具 nethogs 来实时监测统计各进程的带宽使用情况,并进行问题进程的定位。
● 使用 nethogs 工具进行排查
1. 执行以下命令,安装 nethogs 工具:
yum install nethogs -y
安装成功后可以通过 netgos 命令查看网络带宽的使用情况。nethogs 命令常用参数说明如下:
○ -d:设置刷新的时间间隔,默认为 1s。
○ -t:开启跟踪模式。
○ -c:设置更新次数。
○ device:设置要监测的网卡,默认是 eth0。
2. 运行时可以输入以下参数完成相应的操作:
○ q:退出 nethogs 工具。
○ s:按发送流量大小的顺序排列进程列表。
○ r:按接收流量大小的顺序排列进程列表。
○ m:切换显示计量单位,切换顺序依次为 KB/s、KB、B、MB。
3. 执行以下命令,查看指定的网络端口每个进程的网络带宽使用情况:nethogs eth1。
回显参数说明如下:
○ PID:进程 ID。
○ USER:运行该进程的用户。
○ PROGRAM:进程或连接双方的IP地址和端口,前面是服务器的IP和端口,后面是客户端的IP和端口。
○ DEV:流量要去往的网络端口。
○ SENT:进程每秒发送的数据量。
○ RECEIVED:进程每秒接收的数据量。
4. 终止恶意程序或者屏蔽恶意访问 IP。如果确认大量占用网络带宽的进程是恶意进程,可以使用 kill PID 命令终止恶意进程。
如果是某个 IP 恶意访问,可以使用 iptables 服务来对指定 IP 地址进行处理,如屏蔽 IP 地址或限速。
● 若服务遭受 CC 攻击,请采取相应的 CC 防护措施。
如果通过上述排查,云服务器仍然卡顿,请 提交工单,获取恒创科技金牌技术支持。





.png)

.png)

