 云计算服务
云计算服务
 服务器租用
服务器租用
 DDOS 防护
DDOS 防护
 虚拟主机
虚拟主机
 域名服务
域名服务
 基础设施
基础设施
 关于我们
关于我们
Apache Bookkeeper 是基于日志的一个持久化系统,所有的数据会以日志的形式存储到 Ledger 磁盘的 Entry Log 文件中,之后通过后台异步回收的形式来将 EntryLog 文件回收掉。但是在我们实际的使用场景中,发现很久之前的 EntryLog 文件无法被删除掉,对 Entry Log 文件存在的时间进行监控,具体如下:
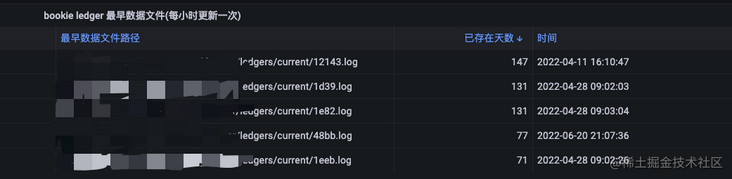
我们可以看到,假设从 Broker 侧设置的 Retention 策略最大为 5 天,即很久之前的 EntryLog 文件依然存在于对应的 Ledger 数据盘中,导致磁盘的占用率较高。虽然Bookie 的 GC 回收机制是后台异步回收的,当 Broker 侧认为某条消息可以删除时,Bookie 并不会立即从磁盘中将该数据删除掉,而是利用 Bookie 的 GC 线程周期性的触发回收的逻辑。但是数据的删除操作竟然滞后了半年多,于是萌生了搞懂 Bookie GC 回收机制的想法,究竟是什么原因导致了该现象的发生。

在 Apache Bookkeeper 中,数据的写入,读取以及回收(压缩)操作是相互隔离的。为了避免过多碎片文件的产生,在 Bookies 中不同 Ledgers 中的 Entrys 会聚合存储到一个 EntryLog 文件中。Bookie 可以通过运行 GC 线程(GarbageCollectorThread)来删除未关联的 Entry 条目来达到回收磁盘空间的目的。在当前的 EntryLog 文件中,如果某一个 Ledger 中包含无法删除的 Entry,那么这个 EntryLog 文件将一直保留在数据盘(Ledger 盘)中无法被删除。由于业务场景的限定,我们没办法要求一个 EntryLog 文件中所有 Ledgers 的 Entries 都能在近乎相同的时间内满足可删除的条件。为了避免该现象,Bookie 引入了数据压缩的概念,即通过扫描 EntryLog 文件判定哪些 Entry 是可以删除的,可以删除的 Entry 继续保留在原始的 EntryLog 文件中,不可删除的 Entry 写入新的 EntryLog 文件中,扫描完成之后将原始的 EntryLog 文件删除掉。
Bookie 压缩类型Bookie 的 GC 回收线程并不是一直执行的,而是基于特定的阈值,Bookie 按照一个 EntryLog 文件中有用数据的占比以及数据压缩被触发的时间将数据压缩的操作分为如下两种类型:
Minor GC:默认触发的时间为每 1 小时触发一次,可以通过 minorCompactionInterval 来自定义每一次 minor GC 触发的时间间隔。当到达 Minor GC 触发的时间阈值之后,会继续检查当前 EntryLog 中有用数据的占比是否超过默认配置的 20%。如果没有超过,则 Minor GC 生效,开始回收并压缩 EntryLog 中的数据。如果超过阈值,那么 Minor GC 不会被触发。可以通过 minorCompactionThreshold 来自定义 Minor GC 中有用数据的占比达到多少之后不会继续触发 Minor GC。为了避免 Minor GC 执行占用太多的时间,也可以通过 minorCompactionMaxTimeMillis 的参数来控制当前 Minor GC 最大允许执行的时间是多少。当 minorCompactionMaxTimeMillis <= 0 时,垃圾回收线程会一直执行直到扫描完成当前 Ledger 目录下所有的 Entry Log 文件。
Major GC:默认触发的时间为每 24 小时触发一次,可以通过 majorCompactionInterval 来自定义每一次 major GC 触发的时间间隔。当到达 Major GC 触发的时间阈值之后,会继续检查当前 EntryLog 中有用数据的占比是否超过默认配置的 80%。如果没有超过,则 Major GC 生效,开始回收并压缩 EntryLog 中的数据。如果超过阈值,那么 Major GC 不会被触发。可以通过 majorCompactionThreshold 来自定义 Major GC 中有用数据的占比达到多少之后不会继续触发 Major GC。为了避免 Minor GC 执行占用太多的时间,也可以通过 majorCompactionMaxTimeMillis 的参数来控制当前 Major GC 最大允许执行的时间是多少。当 majorCompactionMaxTimeMillis <= 0 时,垃圾回收线程会一直执行直到扫描完成当前 Ledger 目录下所有的 Entry Log 文件。
注意: minorCompactionThreshold 和 majorCompactionThreshold 的最大值不可以超过 100%,当 minorGC 和 majorGC 同时配置时,MinorGC 的 minorCompactionInterval 和 minorCompactionThreshold 要求必须小于 MajorGC 中指定的阈值。
为什么需要引入压缩有用占比阈值?当做数据压缩回收时,我们默认分别为 Minor GC 和 Major GC 引入了数据有用占比的阈值,这样做的目的是为了避免每次垃圾回收线程运行时,都会去频繁的扫描所有的 EntryLog 文件。当一个 EntryLog 文件中有用数据的占比超过 Major GC 指定的阈值,那么可以认为当前 EntryLog 中绝大部分数据仍然为有效的数据。这种情况下我们无需继续为了回收剩下的那一点无效数据,然后将该 EntryLog 中的数据从原始的 EntryLog 文件中再写入新的 EntryLog 文件中,这样可以大幅度的节省磁盘 I/O。
Bookie 压缩方式当前,Bookie 提供了如下两种数据压缩的方式:
按照 Entries 的数量默认情况下,Bookie 是通过 Entries 的数量进行压缩,默认值为 1000,即每次最大压缩 1000 条 Entry。可以通过 compactionRateByEntries 自定义每次压缩 Entries 的数量。
按照 Entries 大小Bookie 按照 Entries 的大小进行压缩,可以通过 compactionRateByBytes 自定义每次回收最大允许被回收 Entries 的大小。当想要使用该压缩方式时,需要在 Bookie 的配置文件中同时打开如下配置:isThrottleByBytes=true。
注意:生产环境中建议使用按照 Entries 大小压缩的方式,这个取决于 Entry 被打包的方式。对于 Pulsar 来说,普通消息和 Batch 消息都会被当作一条 Entry 来看待,这就可能会导致每一条 Entry 的大小都不一样。如果按照 Entries 的数量来回收,即每次回收的数据大小是不一致的,如果单个 Entry 过大,有可能导致回收期间占用较大的磁盘 IO,影响正常数据的读写IO,造成抖动的现象发生。
Bookie GC 触发的方式当前 Bookie 的 GC 操作支持如下两种触发方式:
自动触发Bookie 的 GC 回收线程按照 Bookie 压缩类型小节中介绍的方式,按照特定的时间间隔及阈值周期性的执行数据压缩回收的操作。
手动触发Bookie 支持了 REST API 的 HTTP 服务,允许用户通过手动的方式触发 GC,使用方式如下:
curl -X PUT http://127.0.0.1:8000/api/v1/...
IP: 即为当前 Bookie 的 IP 地址Port:示例中的 8000 端口为 Bookie 配置文件中 httpServerPort 指定的端口,默认为 8000。执行完成之后,也可以通过如下请求检查 GC 的状态等信息:
curl http://127.0.0.1:8000/api/v1/...
Output:
[ {
"forceCompacting" : false,
"majorCompacting" : false,
"minorCompacting" : false,
"lastMajorCompactionTime" : 1662436000016,
"lastMinorCompactionTime" : 1662456700007,
"majorCompactionCounter" : 11,
"minorCompactionCounter" : 99
}]Bookie 回收的代码逻辑主要在 org.apache.bookkeeper.bookie.GarbageCollectorThread 类中的 runWithFlags() 方法, 主要的回收逻辑包含如下三个函数:
doGcLedgers()doGcEntryLogs()doCompactEntryLogs()在理解 Bookie GC 的回收逻辑中,我们首先需要介绍几个关键的集合:
LedgerRangeIterator: 该接口为一个 LedgerRange 的迭代器,用来存储从 Meta Store (zookeeper)中存储的所有 Ledgers 的信息。ledgerIndex:是 LedgerStorage (RocksDB)中所有 Ledger 扫描出来的一个集合。ledgersMap:每一个 EntryLog 对应一个 ledgersMap,表示当前 EntryLog 中存储的所有 Ledgers 的集合。entryLogMetaMap:每一个 Ledger 盘拥有一个 entryLogMetaMap 对象,是当前 Ledger 数据盘下所有 EntryLogID -> EntryLogMeta 的一个缓存。当前,Bookie 的索引存储支持了多种方式,默认使用的是 SortedLedgerStorage,可以在 Bookie 的配置文件中通过 ledgerStorageClass 来指定具体需要使用的索引存储方式,一般推荐使用的配置如下:
ledgerStorageClass=org.apache.bookkeeper.bookie.storage.ldb.DbLedgerStorage
所以在下面的代码详解中,我们以 DbLedgerStorage 为例。
doGcLedgers()在 doGcLedgers() 中,代码逻辑主要如下:
首先从 RocksDB 中获取当前数据盘目录下所有的 Ledgers 数据,并使用 NavigableSet 集合暂存当前活跃的 Ledgers 列表。
NavigableSet bkActiveLedgers = Sets.newTreeSet(ledgerStorage.getActiveLedgersInRange(0, Long.MAX_VALUE));
LedgerRangeIterator ledgerRangeIterator = ledgerManager
.getLedgerRanges(zkOpTimeoutMs);
if (ledgerRangeIterator.hasNext()) {
LedgerRange lRange = ledgerRangeIterator.next();
ledgersInMetadata = lRange.getLedgers();
// 当第一次进来以后,就可以获取到当前批次中最大的那个 Ledgers 的索引是多少
end = lRange.end();
} else {
// 如果从 zk 中获取到的 Ledgers 迭代器是空的或者已经迭代完所有的 Ledgers,则重置 done 标记,退出循环。
ledgersInMetadata = new TreeSet<>();
end = Long.MAX_VALUE;
done = true;
}
这里将 LedgerRangeIterator 的迭代器转化为 ledgersInMetadata 的 Set 集合主要是为了第四步可以做 subSet 的操作。
以 RocksDB 中获取到的 Ledgers 集合为标准,对从 zookeeper 中获取的 Ledgers 列表做 subSet 的操作
Iterable subBkActiveLedgers = bkActiveLedgers.subSet(start, true, end, true);
其中 start 位置为 0,end 的位置为 LedgerRangeIterator 迭代器最后的一个位置。因为上述两个 Set 在预先都是做过排序操作的,所以在这里可以直接进行 subSet 的操作。
拿第四步获取到的 subBkActiveLedgers 与 zookeeper 中的 ledgersInMetadata 集合比较,判断 zookeeper 中是否还包含当前 LedgerID,如果不包含代表可以从 Bookie 的 RocksDB 索引中删除当前 LedgerID 的信息。
// 迭代 subBkActiveLedgers 的集合
for (Long bkLid : subBkActiveLedgers) {
// 以 zk 为标准
if (!ledgersInMetadata.contains(bkLid)) {
....
// 清理指定的 Ledger ID
// 这个Ledger在 Bookie 中有,在 zk上没有,则删除。
garbageCleaner.clean(bkLid);
}
}
这里以 zookeeper 中获取到的 ledgersInMetadata 为基准是因为,在 Pulsar 中当数据写入的时候是先去 zookeeper 节点注册一个临时的 zk-node 来存储当前 LedgerID 的相关元数据信息,然后再去 RocksDB 中写入 LedgerID 的存储索引信息,然后将 LedgerID 的 Entry 数据写入到 EntryLog 中。删除操作也是同样的道理,当用户在 Pulsar 中使用的 Topic 中,有 Ledger 符合删除条件时,会去调用 ManagedLedger 的接口去 zookeeper 中删除 LedgerID 的 zk-node。可以看到,无论是读写,对于 Bookie 的 Client 来说,都是优先操作 Bookie-Zk 中的 Ledgers 信息。所以对于删除操作而言我们也是以 zookeeper 中的 Ledgers Set 集合为基准,来检查 RocksDB 的索引存储中有哪些 LedgerID 是可以删除的。
调用 GarbageCleaner 的接口去 RocksDB 的 ledgerIndex 中删除指定的 LedgerID初始化 garbageCleaner 接口并实现 clean 方法,在 clean 方法中调用 DbLedgerStorage 的 deleteLedger 接口
this.garbageCleaner = ledgerId -> {
try {
if (LOG.isDebugEnabled()) {
LOG.debug("delete ledger : " + ledgerId);
}
gcStats.getDeletedLedgerCounter().inc();
// 调用 DbLedgerStorage 去删除接口
ledgerStorage.deleteLedger(ledgerId);
} catch (IOException e) {
LOG.error("Exception when deleting the ledger index file on the Bookie: ", e);
}
};
去 ledgerIndex 的缓存中删除当前的 LedgerID
@Override
public void deleteLedger(long ledgerId) throws IOException {
...
entryLocationIndex.delete(ledgerId);
ledgerIndex.delete(ledgerId);
....
}
可以看到 doGcLedgers() 函数主要是以 zookeeper 的 Ledgers 集合为基准,去对比 RocksDB 的 ledgerIndex 索引存储中删除待删除的 Ledgers。
doGcEntryLogs()在 doGcEntryLogs() 中,代码逻辑主要如下:
迭代 entryLogMetaMap 获取当前数据盘目录下所有的 EntryLog 信息
entryLogMetaMap.forEach((entryLogId, meta) -> {
...
});
removeIfLedgerNotExists(meta);
EntryLogMetadata 中的 removeLedgerIf() 方法的参数为 LongPredicate ,本质是通过 ledgerIndex 中是否存在当前 LedgerID,如果不存在则 LongPredicate 的 test() 方法为true,该 Ledger 可以删除。
private void removeIfLedgerNotExists(EntryLogMetadata meta) {
// 这个 ledger 是否可以删除,取决于当前这个 Ledger 是否在 ledgerIndex 的集合中存在
meta.removeLedgerIf((entryLogLedger) -> {
// Remove the entry log ledger from the set if it isn't active.
try {
// ledgerStorage为专门为压缩定制的 CompactableLedgerStorage,继承了 LedgerStorage 接口
return !ledgerStorage.ledgerExists(entryLogLedger);
} catch (IOException e) {
LOG.error("Error reading from ledger storage", e);
return false;
}
});
}
而 removeLedgerIf() 方法本身操作的是 EntryLogMeta 中 ledgersMap 的这个集合,删除操作也是基于 ledgerIndex 判断是否可以从 ledgersMap 中删除 LedgerID。
public void removeLedgerIf(LongPredicate predicate) {
ledgersMap.removeIf((ledgerId, size) -> {
boolean shouldRemove = predicate.test(ledgerId);
if (shouldRemove) {
remainingSize -= size;
}
return shouldRemove;
});
}
// 判断 EntryLog Meta 中的 ledgersMap 对象是否还有元素。
if (meta.isEmpty()) {
// This means the entry log is not associated with any active ledgers anymore.
// We can remove this entry log file now.
LOG.info("Deleting entryLogId " + entryLogId + " as it has no active ledgers!");
// 当当前的 EntryLog 中没有任何 Ledgers 对象时,直接调用删除 EntryLog 的接口进行删除操作。
removeEntryLog(entryLogId);
gcStats.getReclaimedSpaceViaDeletes().add(meta.getTotalSize());
}
可以看到,在doGcEntryLogs 函数中,主要是以 ledgerIndex 为基准,操作每一个 EntryLog 中的 ledgesMap 对象,判断 Ledger 是否可以删除。如果当前 EntryLog 的所有 Ledger 都可以删除,则直接删除 EntryLog 文件。如果有一部分 Ledger 可以删除,一部分 Ledger 无法删除,则进入 doCompactEntryLogs() 函数的处理逻辑中。
doCompactEntryLogs在 doCompactEntryLogs() 中,代码主要逻辑如下:
构造 entryLogMetaMap 的临时对象 logsToCompact,并按照使用率对其排序:
List logsToCompact = new ArrayList();
// 开始之前首先把本地缓存的 entryLogMetaMap 都添加进来
logsToCompact.addAll(entryLogMetaMap.values());
// 按照使用率做一个排序
logsToCompact.sort(Comparator.comparing(EntryLogMetadata::getUsage));
for (EntryLogMetadata meta : logsToCompact) {
...
// 真正触发回收的核心逻辑
compactEntryLog(meta);
}
// 扫描指定的 EntryLog 文件
entryLogger.scanEntryLog(entryLogMeta.getEntryLogId(), scannerFactory.newScanner(entryLogMeta));
扫描 EntryLog 文件中可以简单梳理为如下三个逻辑:
3.1 如何扫描 EntryLog 文件
要理解 EntryLog 文件是如何被扫描出来的,我们首先要去看 Entry 是如何被写入 EntryLog 文件中的。首先每一个 EntryLog 都有 1024 个字节 EntryLog Header 信息,主要包含如下内容:
Fingerprint(指纹信息): 4 bytes "BKLO"在预分配 EntryLog 的时候,就固定的将4字节的签名信息写入
Log file HeaderVersion: 4 bytes有两个版本:HEADER_V0 和 HEADER_V1,当前 EntryLog 的版本为 HEADER_V1。
Ledger map offset: 8 bytesLedgers Count: 4 bytes所以在扫描 EntryLog 文件时,我们首先跳过当前 EntryLog 的 Header 信息:
// Start the read position in the current entry log file to be after
// the header where all of the ledger entries are.
long pos = LOGFILE_HEADER_SIZE;
之后会继续写入 4 字节的 entrySize 以及 8 字节的 LedgerID,所以扫描的时候也需要按照这种格式将 entrySize 和 LedgerID 分别读取出来,然后依据 entrySize 的大小,继续向后读取出 Entry 真正的内容。
// Buffer where to read the entrySize (4 bytes) and the ledgerId (8 bytes)
ByteBuf headerBuffer = Unpooled.buffer(4 + 8);
while (true) {
...
long offset = pos;
pos += 4;
int entrySize = headerBuffer.readInt();
long ledgerId = headerBuffer.readLong();
headerBuffer.clear();
// 调用 scanner 的 accept() 方法
if (ledgerId == INVALID_LID || !scanner.accept(ledgerId)) {
// skip this entry
pos += entrySize;
continue;
}
// read the entry
data.clear();
if (entrySize <= 0) {
LOG.warn("bad read for ledger entry from entryLog {}@{} (entry size {})",
entryLogId, pos, entrySize);
return;
}
data.capacity(entrySize);
// process the entry
// 调用 scanner 的 process() 方法,将 entry 写入新的 EntryLog 中
scanner.process(ledgerId, offset, data);
// Advance position to the next entry
pos += entrySize;
}
如此往复,不断的将 EntryLog 中的每一条 Entry 依次读取出来。
3.2 accept 接口
accept 接口主要用来判断当前的 LedgerID 是否还在 EntryLog 文件中,即是否还在 ledgersMap 中存在。
@Override
public boolean accept(long ledgerId) {
return meta.containsLedger(ledgerId);
}
3.3 process 接口
process 接口主要用来将无法删除的 Entry 写入到新的 EntryLog 文件中,并记录 Entry 对应的 offset 信息。
@Override
public void process(final long ledgerId, long offset, ByteBuf entry) throws IOException {
...
long newoffset = entryLogger.addEntry(ledgerId, entry);
offsets.add(new EntryLocation(ledgerId, entryId, newoffset));
}
// 强制把写入的数据刷新到磁盘上去,刷新的时候会同时更新索引信息,以便 broker 下次读取消息的时候,可以去新的 EntryLog 中去读取。
scannerFactory.flush();
flush() 方法主要是将上述无法删除的 Entry 写入新 EntryLog 中的位点信息调用 DbLedgerStorage 的接口更新到 RocksDB 中去。
void flush() throws IOException {
if (offsets.isEmpty()) {
if (LOG.isDebugEnabled()) {
LOG.debug("Skipping entry log flushing, as there are no offset!");
}
return;
}
// Before updating the index, we want to wait until all the compacted entries are flushed into the
// entryLog
try {
entryLogger.flush();
// 更新新 EntryLog 文件中 offsets 的信息。
ledgerStorage.updateEntriesLocations(offsets);
ledgerStorage.flushEntriesLocationsIndex();
} finally {
offsets.clear();
}
}
// 移除掉原先旧的EntryLog文件
logRemovalListener.removeEntryLog(entryLogMeta.getEntryLogId());
上述的代码逻辑描述了对于单个数据盘目录下 EntryLog 完整的回收逻辑。对于多个数据盘目录的场景,每一个数据盘目录都会创建一个单独的 GarbageCollectorThread 的线程来运行上述的逻辑。
EntryLog 文件的大小如何控制在 Ledger 的数据盘目录中可以看到,每一个 EntryLog 文件的大小都固定为 1GB 左右,当达到这个大小时,EntryLog 文件就会滚动创建新的 EntryLog 文件来写入。这是因为默认设置的 EntryLog 大小为 1GB,具体如下:
/**
* Set the max log size limit to 1GB. It makes extra room for entry log file before
* hitting hard limit '2GB'. So we don't need to force roll entry log file when flushing
* memtable (for performance consideration)
*/
public static final long MAX_LOG_SIZE_LIMIT = 1 * 1024 * 1024 * 1024;
reachEntryLogLimit() 方法用来检查是否 EntryLog 文件达到指定的大小:
boolean reachEntryLogLimit(BufferedLogChannel logChannel, long size) {
if (logChannel == null) {
return false;
}
return logChannel.position() + size > logSizeLimit;
}
用户也可以通过如下参数自定义 EntryLog 文件的大小:
logSizeLimit
在 doCompactEntryLogs 章节中可以看到,在迭代 entryLogMetaMap 时,依据 EntryLog 的使用率对 EntryLog 进行了排序。EntryLog 的使用率主要通过 EntryLog Metadata 中的如下两个字段进行计算的:
private long totalSize; // 总大小private long remainingSize; // 剩余大小在数据写入 EntryLog (ledgersMap) 的过程中会同时增加 totalSize 和 remainingSize 这两个字段:
// 往 ledgersMap 中新增元素
public void addLedgerSize(long ledgerId, long size) {
totalSize += size;
remainingSize += size;
ledgersMap.addAndGet(ledgerId, size);
}
当在做数据压缩时,如果判断某一个 LedgerID 可以从 ledgersMap 中删除时,会从 remainingSize 中减去当前 Ledger 的 size:
public void removeLedgerIf(LongPredicate predicate) {
ledgersMap.removeIf((ledgerId, size) -> {
boolean shouldRemove = predicate.test(ledgerId);
if (shouldRemove) {
remainingSize -= size; // 减去当前 ledger 的大小
}
return shouldRemove;
});
}
所以在计算 EntryLog 的使用率时,拿当前 remainingSize/totalSize 即可计算出 EntryLog 文件中当前剩余的有效数据的比率是多少:
public double getUsage() {
if (totalSize == 0L) {
return 0.0f;
}
return (double) remainingSize / totalSize;
}
minor GC 与 major GC 执行数据回收的逻辑是完全一致的,EntryLog 中有效数据的使用率也是用来区分是否为 minor GC 或者 major GC 的关键点。






.png)

.png)

