 云计算服务
云计算服务
 服务器租用
服务器租用
 DDOS 防护
DDOS 防护
 虚拟主机
虚拟主机
 域名服务
域名服务
 基础设施
基础设施
 关于我们
关于我们
用 2 个题来应用 left join, inner join, group by + having, case when 的用法等.
继续 sql 搞起来, 面向过程来弄, 重点是分析的思路, 涉及的的 left join, inner join, group by +_ having, case when ... 等场景, 也是比较详细地记录整个分析的过程, 虽然实现并不难.
数据关系这个是都次都要重复提及的. 只有熟练知晓表结构, 才能做各种查询呀.

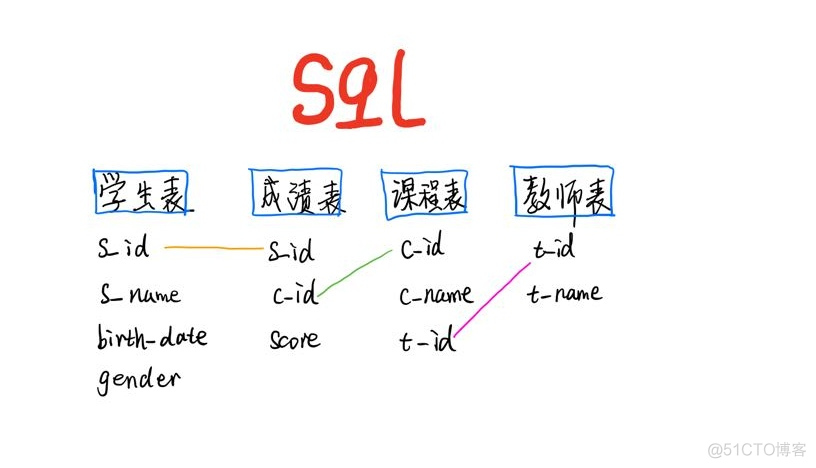
查询平均成绩大于80分的学生的学号和平均成绩.
分析
只用使用一个 score 表就搞定了.
mysql> select * from score;
+------+------+-------+
| s_id | c_id | score |
+------+------+-------+
| 0001 | 0001 | 80 |
| 0001 | 0002 | 90 |
| 0001 | 0003 | 99 |
| 0002 | 0002 | 60 |
| 0002 | 0003 | 80 |
| 0003 | 0001 | 80 |
| 0003 | 0002 | 80 |
| 0003 | 0003 | 80 |
+------+------+-------+
8 rows in set (0.00 sec)
直接对 score 表 对 s_id 做 group by 然后对 avg(score), 再组内过滤 (haing) 即可.
-- 先弄分组聚合, 注意要先写 s_id
select
s_id,
avg(score)
from score
group by
s_id;
+------+------------+
| s_id | avg(score) |
+------+------------+
| 0001 | 89.6667 |
| 0002 | 70.0000 |
| 0003 | 80.0000 |
+------+------------+
3 rows in set (0.00 sec)
这样, 学号和平均成绩都有了, 然后还要一个, 平均成绩大于 80, 这就是 对 group by 后的一个筛选, 用 having.
select
s_id as "学号",
avg(score) as "平均成绩"
from score
group by s_id
having avg(score) > 80;
这上面没过滤之前就能看出, 大于80的, 就只有1号老铁这个学霸.
+--------+--------------+
| 学号 | 平均成绩 |
+--------+--------------+
| 0001 | 89.6667 |
+--------+--------------+
1 row in set (0.00 sec)
补充
-- 增加对 group by 中没有用到的字段是没啥意义的
select
s_id as "学号",
avg(score) as "平均成绩",
c_id -- add
from score
group by s_id
having avg(score) > 80;
+--------+--------------+------+
| 学号 | 平均成绩 | c_id |
+--------+--------------+------+
| 0001 | 89.6667 | 0001 |
+--------+--------------+------+
1 row in set (0.00 sec)
这个 c_id 是没有任何意义的, 因为是平均成绩嘛, 因此, **最好不要将 group by 无关的字段给放在 select 中去哦.
其实 pandas 也是一样的处理方式, df.groupby("s_id").agg({"score": "mean"}) . 当然可能是习惯问题, 我总感觉 Python 这种写法会更加直观些, 先分组, 再聚合 , 说的是写法上哈.
本题的核心点: group by + having.
第 03 题查询所有学生的学号, 姓名, 选课数, 总成绩.
分析
分析: 其实就是以学生表, 我主表, 然后左连接成绩表, 然后再按 s_id group by 再聚合即可.
首先用 学生表为主表, left join 成绩表即可.
select *
from student as a
left join score as b
on a.s_id = b.s_id;
先连接上看看.
+------+-----------+------------+--------+------+------+-------+
| s_id | s_name | birth_date | gender | s_id | c_id | score |
+------+-----------+------------+--------+------+------+-------+
| 0001 | 王二 | 1989-01-01 | 男 | 0001 | 0001 | 80 |
| 0001 | 王二 | 1989-01-01 | 男 | 0001 | 0002 | 90 |
| 0001 | 王二 | 1989-01-01 | 男 | 0001 | 0003 | 99 |
| 0002 | 星落 | 1990-12-21 | 女 | 0002 | 0002 | 60 |
| 0002 | 星落 | 1990-12-21 | 女 | 0002 | 0003 | 80 |
| 0003 | 胡小适 | 1991-12-21 | 男 | 0003 | 0001 | 80 |
| 0003 | 胡小适 | 1991-12-21 | 男 | 0003 | 0002 | 80 |
| 0003 | 胡小适 | 1991-12-21 | 男 | 0003 | 0003 | 80 |
| 0004 | 油哥 | 1996-10-01 | 男 | NULL | NULL | NULL |
+------+-----------+------------+--------+------+------+-------+
9 rows in set (0.06 sec)
然后, 对 s_id 进行 group by, 对 c_id 进行 count, 对 score 进行 sum.
select
a.s_id as "学号",
a.s_name as "姓名",
count(b.c_id) as "选课数",
sum(b.score) as "总成绩"
from student as a
left join score as b
on a.s_id = b.s_id
group by a.s_id;
阅读顺序跟写的顺序是, 先写表连接的部分, 然后再 group by, 最后再 写最终要查询的字段 (包含聚合)
+--------+-----------+-----------+-----------+
| 学号 | 姓名 | 选课数 | 总成绩 |
+--------+-----------+-----------+-----------+
| 0001 | 王二 | 3 | 269 |
| 0002 | 星落 | 2 | 140 |
| 0003 | 胡小适 | 3 | 240 |
| 0004 | 油哥 | 0 | NULL |
+--------+-----------+-----------+-----------+
4 rows in set (0.04 sec)
在这里看上去是没啥问题的, 对于这句 a.s_id as "学号", a.s_name as "姓名", 在本例, 学号跟姓名是 1:1 的关系, 是ok 的. 但假如说, 不是 1: 1 就可能产生很大的问题. 当然我用 pandas 时写也是这样类似的:
# 假设这里的 df 已经是 merge 好了的哈, 直接group by
df.groupby("s_id").agg({"s_id":" count"},
{"score": "sum"}
)
其实套路都是一样的, 重点是理解这个 , apply -> group by -> aggregation 的通用套路. 就连大数据的 mapReduce 也是差不多的思想呀.
严格来讲, 这里的 a.s_name z 字段跟 group by 后的聚合字段, 是没啥关系的, 理应不能出现在此处 1:n 反而造成误解.
更严谨的写法能, 就是将这 a.s_name 也放在 s_id 后面 group by. (熟悉Excel透视表的小伙伴就很清楚啦).
select
a.s_id as "学号",
a.s_name as "姓名",
count(b.c_id) as "选课数",
sum(b.score) as "总成绩"
from student as a
left join score as b
on a.s_id = b.s_id
group by a.s_id, a.s_name;
得到的结果是一样的.嗯, 这个操作, 我以前在用 excel 的时候, 会很频繁使用到, 透视字段这块.
+--------+-----------+-----------+-----------+
| 学号 | 姓名 | 选课数 | 总成绩 |
+--------+-----------+-----------+-----------+
| 0001 | 王二 | 3 | 269 |
| 0002 | 星落 | 2 | 140 |
| 0003 | 胡小适 | 3 | 240 |
| 0004 | 油哥 | 0 | NULL |
+--------+-----------+-----------+-----------+
4 rows in set (0.00 sec)
对于 Null 这里需要处理一下, 比较合理的方式呢, 是填充为 0. 也就是需要在 sum 那的时候, 加上一个判断
case 语法: case when then xxx else xxx end
select
a.s_id as "学号",
a.s_name as "姓名",
count(b.c_id) as "选课数",
sum(case when b.score is Null
then 0
else b.score end
) as "总成绩"
from student as a
left join score as b
on a.s_id = b.s_id
group by a.s_id, a.s_name;
+--------+-----------+-----------+-----------+
| 学号 | 姓名 | 选课数 | 总成绩 |
+--------+-----------+-----------+-----------+
| 0001 | 王二 | 3 | 269 |
| 0002 | 星落 | 2 | 140 |
| 0003 | 胡小适 | 3 | 240 |
| 0004 | 油哥 | 0 | 0 |
+--------+-----------+-----------+-----------+
4 rows in set (0.07 sec)
这样 Null 的问题也解决了. 这种 case when xxx then xxx else xxx end 还是挺常用的.
小结group by + having 的用法 (严谨写法是, 跟 group by 无关的字段, 不要放 select)left join 和 inner join 等的不同场景用法 (我感觉工作中用的最多的是 left join 更多一点)深刻理解apply -> group by -> aggregation, 不论是 sql 还是编程, 数据分析必须迈过的坎字段值判断 case when xx then xxx else xxx end 的这种写法, 跟 if 的区别在于, if 用在函数, case 用在查询.case 与 if 的区别
if 是条件判断语句 不能在 查询语句中出现; case 是条件检索 可以再查询中出现
耐心和恒心, 总会获得回报的.






.png)

.png)

