 云计算服务
云计算服务
 服务器租用
服务器租用
 DDOS 防护
DDOS 防护
 虚拟主机
虚拟主机
 域名服务
域名服务
 基础设施
基础设施
 关于我们
关于我们
源码安装完MySQL之后,使用Debug模式启动
mysqld --debug --console &后,
mysql> create database wxb;
Query OK, 1 row affected (0.01 sec)
mysql> use wxb;
Database changed
mysql> create table t(a int);
Query OK, 0 rows affected (0.01 sec)
mysql> select * from t where k=1;
ERROR 1054 (42S22): Unknown column 'k' in 'where clause'
T@4: | | | | | | | | | error: error: 1054 message: 'Unknown column 'k' in 'where clause''
Complete optimizer trace:

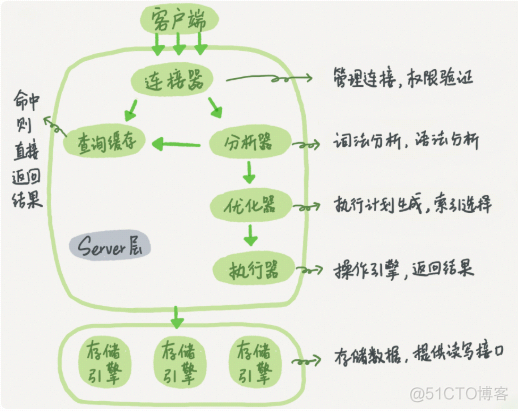
入手比较晚,说下个人对为什么是分析器的看法。
连接器:门卫,想进请出示准入凭证(工牌、邀请证明一类)。“你好,你是普通员工,只能进入办公大厅,不能到高管区域”此为权限查询。
分析器:“您需要在公司里面找一张头发是黑色的桌子?桌子没有头发啊!臣妾做不到”
优化器:“要我在A B两个办公室找张三和李四啊?那我应该先去B办公室找李四,然后请李四帮我去A办公室找张三,因为B办公室比较近且李四知道张三具体工位在哪”
执行器:“好了,找人的计划方案定了,开始行动吧,走你!糟糕,刚门卫大哥说了,我没有权限进B办公室”
连接完成后,如果你没有后续的动作,这个连接就处于空闲状态,你可以在 show processlist 命令中看到它。
文本中这个图是 show processlist 的结果,其中的 Command 列显示为“Sleep”的这一行,就表示现在系统里面有一个空闲连接。

客户端如果太长时间没动静,连接器就会自动将它断开。这个时间是由参数 wait_timeout 控制的,默认值是 8 小时。
如果在连接被断开之后,客户端再次发送请求的话,就会收到一个错误提醒: Lost connection to MySQL server during query。
这时候如果你要继续,就需要重连,然后再执行请求了。
数据库里面,长连接是指连接成功后,如果客户端持续有请求,则一直使用同一个连接。
短连接则是指每次执行完很少的几次查询就断开连接,下次查询再重新建立一个。
建立连接的过程通常是比较复杂的,所以我建议你在使用中要尽量减少建立连接的动作,也就是尽量使用长连接。
但是全部使用长连接后,你可能会发现,有些时候 MySQL 占用内存涨得特别快,这是因为 MySQL 在执行过程中临时使用的内存是管理在连接对象里面的。这些资源会在连接断开的时候才释放。
所以如果长连接累积下来,可能导致内存占用太大,被系统强行杀掉(OOM),从现象看就是 MySQL 异常重启了。
怎么解决这个问题呢?你可以考虑以下两种方案。
定期断开长连接。使用一段时间,或者程序里面判断执行过一个占用内存的大查询后,断开连接,之后要查询再重连。
如果你用的是 MySQL 5.7 或更新版本,可以在每次执行一个比较大的操作后,通过执行 mysql_reset_connection 来重新初始化连接资源。这个过程不需要重连和重新做权限验证,但是会将连接恢复到刚刚创建完时的状态。
MySQL 整体来看,其实就有两块:
一块是 Server 层,它主要做的是 MySQL 功能层面的事情;
还有一块是引擎层,负责存储相关的具体事宜。
MySQL 里面最重要的两个日志,即物理日志 redo log 和逻辑日志 binlog。
redo log 用于保证 crash-safe 能力。
现在由于redo是属于InnoDB引擎,所以必须要有binlog,因为你可以使用别的引擎
binlog还不能去掉。
一个原因是,redolog只有InnoDB有,别的引擎没有。
另一个原因是,redolog是循环写的,不持久保存,binlog的“归档”这个功能,redolog是不具备的。
Redo log不是记录数据页“更新之后的状态”,而是记录这个页 “做了什么改动”。
Binlog有两种模式,statement 格式的话是记sql语句, row格式会记录行的内容,记两条,更新前和更新后都有。
redo log 是 InnoDB 引擎特有的日志,而 Server 层也有自己的日志,称为 binlog(归档日志)。
我想你肯定会问,为什么会有两份日志呢?
因为最开始 MySQL 里并没有 InnoDB 引擎。MySQL 自带的引擎是 MyISAM,但是 MyISAM 没有 crash-safe 的能力,binlog 日志只能用于归档。
而 InnoDB 是另一个公司以插件形式引入 MySQL 的,既然只依靠 binlog 是没有 crash-safe 能力的,所以 InnoDB 使用另外一套日志系统——也就是 redo log 来实现 crash-safe 能力。
这两种日志有以下三点不同。
redo log 是 InnoDB 引擎特有的;
binlog 是 MySQL 的 Server 层实现的,所有引擎都可以使用。
redo log 是物理日志,记录的是“在某个数据页上做了什么修改”;
binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如“给 ID=2 这一行的 c 字段加 1 ”。
redo log 是循环写的,空间固定会用完;
binlog 是可以追加写入的。“追加写”是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
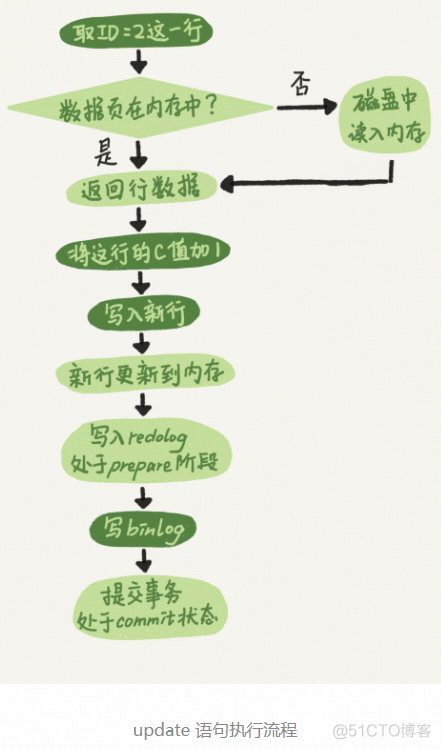
你可能注意到了,最后三步看上去有点“绕”,将 redo log 的写入拆成了两个步骤:prepare 和 commit,这就是"两阶段提交"。
两阶段提交为什么必须有“两阶段提交”呢?
这是为了让两份日志之间的逻辑一致。
要说明这个问题,我们得从文章开头的那个问题说起:怎样让数据库恢复到半个月内任意一秒的状态?
前面我们说过了,binlog 会记录所有的逻辑操作,并且是采用“追加写”的形式。
如果你的 DBA 承诺说半个月内可以恢复,那么备份系统中一定会保存最近半个月的所有 binlog,同时系统会定期做整库备份。这里的“定期”取决于系统的重要性,可以是一天一备,也可以是一周一备。
由于 redo log 和 binlog 是两个独立的逻辑,如果不用两阶段提交,要么就是先写完 redo log 再写 binlog,或者采用反过来的顺序。我们看看这两种方式会有什么问题。
“binlog没有被用来做崩溃恢复”,
历史上的原因是,这个是一开始就这么设计的,所以不能只依赖binlog。
操作上的原因是,binlog是可以关的,你如果有权限,可以set sql_log_bin=0关掉本线程的binlog日志。 所以只依赖binlog来恢复就靠不住。
1.首先客户端通过tcp/ip发送一条sql语句到server层的SQL interface
2.SQL interface接到该请求后,先对该条语句进行解析,验证权限是否匹配
3.验证通过以后,分析器会对该语句分析,是否语法有错误等
4.接下来是优化器器生成相应的执行计划,选择最优的执行计划
5.之后会是执行器根据执行计划执行这条语句。在这一步会去open table,如果该table上有MDL,则等待。
如果没有,则加在该表上加短暂的MDL(S)
(如果opend_table太大,表明open_table_cache太小。需要不停的去打开frm文件)
6.进入到引擎层,首先会去innodb_buffer_pool里的data dictionary(元数据信息)得到表信息
7.通过元数据信息,去lock info里查出是否会有相关的锁信息,并把这条update语句需要的
锁信息写入到lock info里(锁这里还有待补充)
8.然后涉及到的老数据通过快照的方式存储到innodb_buffer_pool里的undo page里,并且记录undo log修改的redo
(如果data page里有就直接载入到undo page里,如果没有,则需要去磁盘里取出相应page的数据,载入到undo page里)
9.在innodb_buffer_pool的data page做update操作。并把操作的物理数据页修改记录到redo log buffer里
由于update这个事务会涉及到多个页面的修改,所以redo log buffer里会记录多条页面的修改信息。
因为group commit的原因,这次事务所产生的redo log buffer可能会跟随其它事务一同flush并且sync到磁盘上
10.同时修改的信息,会按照event的格式,记录到binlog_cache中。(这里注意binlog_cache_size是transaction级别的,不是session级别的参数,
一旦commit之后,dump线程会从binlog_cache里把event主动发送给slave的I/O线程)
11.之后把这条sql,需要在二级索引上做的修改,写入到change buffer page,等到下次有其他sql需要读取该二级索引时,再去与二级索引做merge
(随机I/O变为顺序I/O,但是由于现在的磁盘都是SSD,所以对于寻址来说,随机I/O和顺序I/O差距不大)
12.此时update语句已经完成,需要commit或者rollback。这里讨论commit的情况,并且双1
13.commit操作,由于存储引擎层与server层之间采用的是内部XA(保证两个事务的一致性,这里主要保证redo log和binlog的原子性),
所以提交分为prepare阶段与commit阶段
14.prepare阶段,将事务的xid写入,将binlog_cache里的进行flush以及sync操作(大事务的话这步非常耗时)
15.commit阶段,由于之前该事务产生的redo log已经sync到磁盘了。所以这步只是在redo log里标记commit
16.当binlog和redo log都已经落盘以后,如果触发了刷新脏页的操作,先把该脏页复制到doublewrite buffer里,把doublewrite buffer里的刷新到共享表空间,然后才是通过page cleaner线程把脏页写入到磁盘中
老师,你看我的步骤中有什么问题嘛?我感觉第6步那里有点问题,因为第5步已经去open table了,第6步还有没有必要去buffer里查找元数据呢?这元数据是表示的系统的元数据嘛,还是所有表的?
作者回复: 其实在实现上5是调用了6的过程了的,所以是一回事。MySQL server 层和InnoDB层都保存了表结构,所以有书上描述时会拆开说。






.png)

.png)

