 云计算服务
云计算服务
 服务器租用
服务器租用
 DDOS 防护
DDOS 防护
 虚拟主机
虚拟主机
 域名服务
域名服务
 基础设施
基础设施
 关于我们
关于我们
记录 hive 三类函数:取整函数、随机抽样(rand()函数)、数组包含函数(array_contains)、later view explode函数取整函数
round(A,B) :
四舍五入,A是整型或者浮点型参数,B是要保留的小数位数,B是可选参数,不写的话默认对浮点数保留一位小数
select round(-1.23,1)
> -1.2
select round(2.546,2)
> 2.55
select round(2.34)
> 2.3floor(A):取坐标轴上的左值
select floor(-1.3)
> -2
select floor(1.3)
> 1ceil(A) :取坐标轴上的右值 ,select floor(-1.3)
select ceil(-1.3)
> -1
select ceil(1.3)
> 2在大规模数据量的数据集上有两种使用方式,可以随机抽取小数据量的数据进行数据分析和建模:
order by rand() 是对全局的数据做排序,会把所有数据放进一个reducer中处理,如果数据量非常大,可能会比较耗时:
select * from table_name where col=xxx order by rand() limit num;在rand() 前指定 distribute 和 sort 关键字可以保证数据在mapper和reduce阶段都是随机的,distribute by是控制在map端如何拆分数据给reduce端的,sort by是局部排序,会在每个reduce端做排序,适用于数据量较大的情况:
select * from table_name where col=xxx distribute by rand() sort by rand() limit num;array_contains(数组,值),返回布尔类型值
select *
from dulux_dataset_101 where array_contains(mark,' 10')
limit 10explode() 是UDTF 函数的一种,可以将一行数据按照分隔符变成多行,但是不能和其它列一起查出,例如dulux_dataset_101中mark字段是个数组
select
explode(mark) as mark_explode
from dulux_dataset_101
limit 10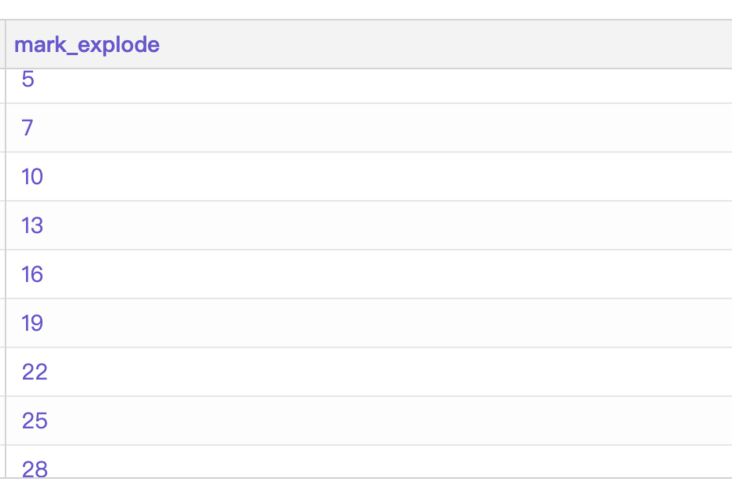
这样就会直接报错,因为mainid能返回的行数和mark_explode不一致
select mianid,explode(mark) as mark_explode
from dulux_dataset_101
limit 10于是要和 lateral view 搭配使用,temptable为虚拟表的别名,mark_explode为切分后的字段名
select mainid,mark_explode
from dulux_dataset_101
lateral view explode(mark) temptable as mark_explode
where array_contains(mark,' 10')
limit 10





.png)

.png)

