 云计算服务
云计算服务
 服务器租用
服务器租用
 DDOS 防护
DDOS 防护
 虚拟主机
虚拟主机
 域名服务
域名服务
 基础设施
基础设施
 关于我们
关于我们
在最新一届国际数据库顶级会议 ACM SIGMOD 2022 上,来自清华大学的李国良和张超两位老师发表了一篇论文:《HTAP Database: What is New and What is Next》,并做了 《HTAP Database:A Tutorial》 的专项报告。
本篇文章,我们将系统地梳理一下两位老师的报告,带读者了解 HTAP 的发展现状和未来趋势。
这个报告主体上分为5个章节,分别是:
背景介绍。HTAP Databases:分享最新的 HTAP 数据库技术,总结它们主要的应用场景与优缺点,并根据存储架构对它们进行分类。HTAP Tecniques:介绍主流的 HTAP 数据库关键技术,包括事务处理技术、查询分析技术、数据组织技术、数据同步技术、查询优化技术以及资源调度技术等。HTAP Benchmarks:介绍目前现有的主流 HTAP 基准测试。Challenges and Open Problems:讨论 HTAP 技术未来的研究方向与挑战。本文仅作精选分享,会省略一些非必要内容,如想了解更多,请阅读原报告。
背景介绍Motivation开头还是一个老生常谈的 HTAP 起源动机问题,这个其实大家看过我们之前的文章《什么是真正的HTAP?背景篇》,也就很清楚了:HTAP(Hybrid Transactional/Analytical Processing)的概念和定义是 Gartner 在 2014 年第一次给出的,注意,这里特别提到了in-memory技术,在其定义中,HTAP 是通过内存计算技术在同一份内存数据上同时支持事务和分析的处理。
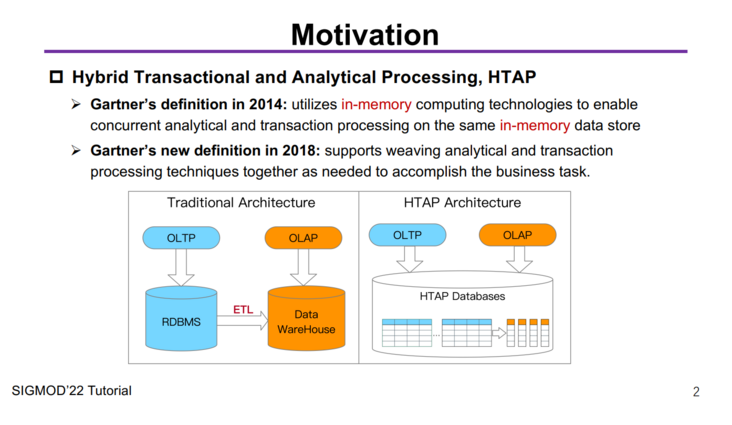
如上图所示,左边是传统架构,要做OLAP必须先得把OLTP的数据通过ETL导过去,很麻烦,复杂度高、延迟高、运维难度大,总之一系列水深问题,一般人把握不住。
但是右边的HTAP架构就很酷了,我一个数据库采用行列共存的方式,同时进行事务和分析的处理,So easy,老板再也不用担心我做个BI报表需要“T+1”甚至“T+N”了,数据一进来就能做到实时地分析,没错,这就是我们常说的 Real-Time。

Gartner 预计 HTAP 这个技术将会在 2024 年被需要实时分析的商业应用广泛采用,因为它在很多行业都有应用场景,包括电商、财务、银行和风控等等。这里举两个栗子:
在购物节这种高并发的情形下,如果电商卖家能够实时地分析用户行为数据,并根据分析结果针对性地投放品类广告,这无疑会给卖家带来更多的收益。银行在线上处理用户事务时还能实时地分析数据,从而检测判断该用户及其行为是否异常或者存在风险,这会让风控系统更加智能化。实现上述的应用,HTAP 技术就是不可或缺的基础设施底座。
可以看到,过去10年里,HTAP数据库不断涌现,本篇报告作者这里根据 HTAP 数据库发展时间线梳理成三个阶段:

PS:StoneDB 属于第三阶段,是具有分布式架构、内存计算和行列混存的HTAP数据库。
在数据库领域,有两个公认的经验法则:
行存(Row Store):比较适合OLTP。
Row-wise,update-heavy(重更新),short-lived transactions(短时延事务)列存(Column Store):比较适合OLAP。
column-wise,read-heavy,bandwidth-intensive queries(带宽敏感查询)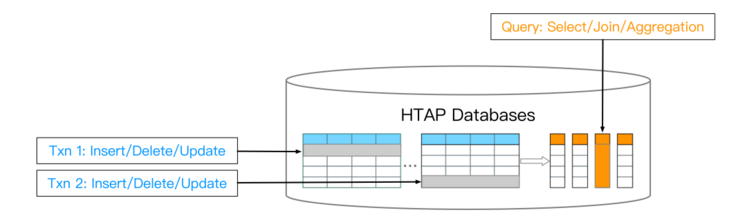
在本篇报告主要研究采用行列共存的HTAP数据库。
A trade-off for HTAP databasesHTAP 数据库也有需要解决的问题,正所谓鱼和熊掌不可兼得,很多时候我们需要找到一个权衡点,既然是权衡,就有天平的两端,在HTAP数据库领域里,主要讨论的是工作负载隔离(Workload isolation) 和 数据新鲜度(Data freshness) 这两个重要特性的权衡。
工作负载隔离,就是指OLTP和OLAP之间的负载隔离程度;数据新鲜度,就是指OLAP到底能读到多新的事务性数据。
从现有的观测数据来看:
高的工作负载隔离会导致较低的数据新鲜度低的工作负载隔离会获得较高的数据新鲜度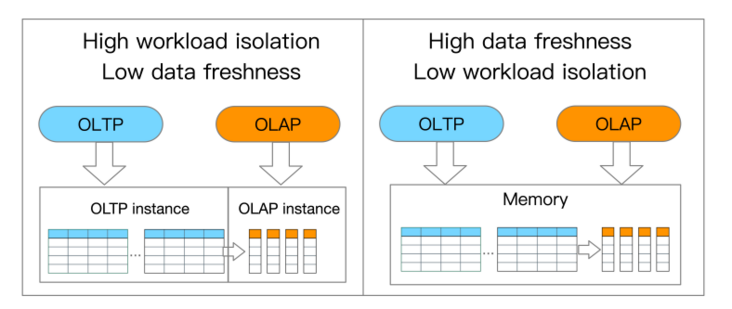
这里关于Trade-off的相关思考我们之前在对外的分享会上也屡次提及,感兴趣的同学可以前往B站观看我们最近一期的线上Meetup视频:

作者这里提出了HTAP数据库面临的四大挑战,这里也和我们的第二篇文章《什么是真正的HTAP?挑战篇》里的观点不谋而合,可以说完全在我们提出的8点挑战范围之内:
挑战一:数据组织(Data Organization)挑战二:数据同步(Data Synchronization)挑战三:查询优化(Query Optimization)挑战四:资源调度(Resource Scheduling)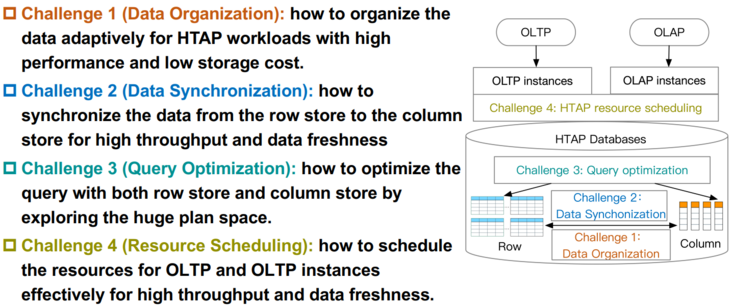
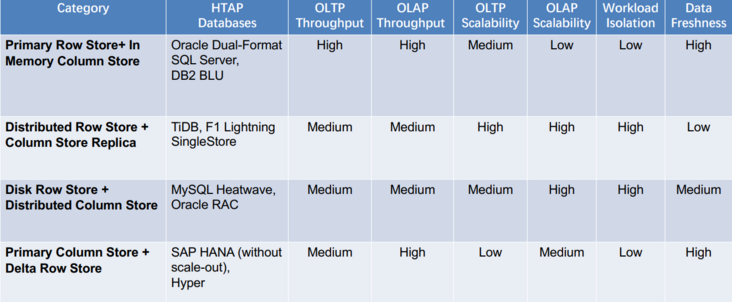
这一章节主要调研现有 HTAP 数据库的主要架构,作者这里分成了四大架构:
主行存储+内存中列存储(Primary Row Store + InMemory Column Store)分布式行存储+列存储副本(Distributed Row Store + Column Store Replica)磁盘行存储+分布式列存储(Disk Row Store + Distributed Column Store)主列存储+增量行存储(Primary Column Store + Delta Row Store)a.主行存储+内存中列存储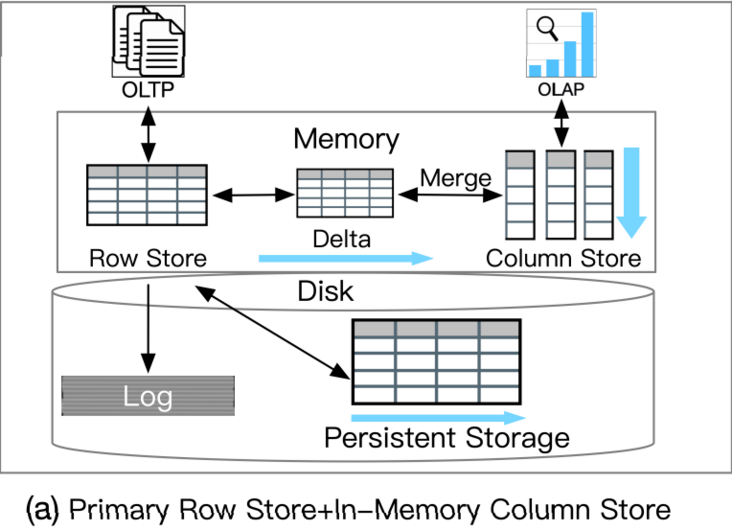
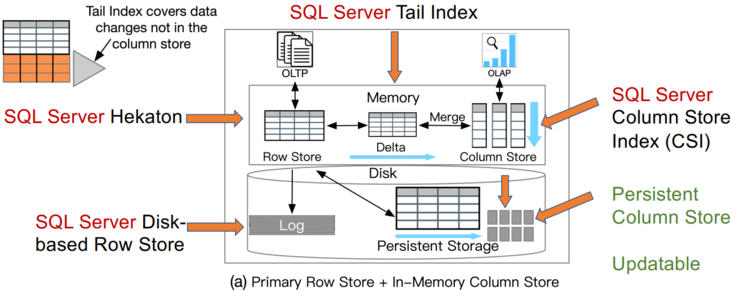
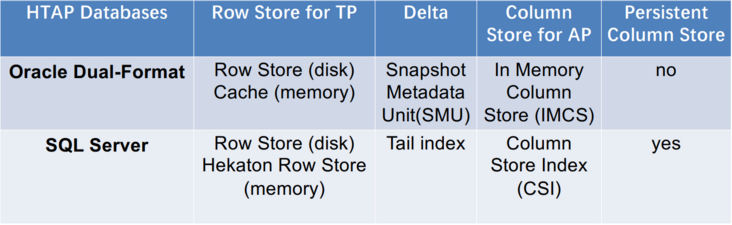
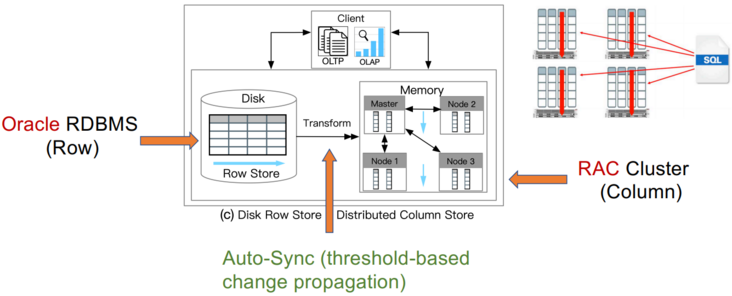
这类 HTAP 数据库利用主行存储作为 OLTP 工作负载的基础,并使用内存列存储处理 OLAP 工作负载。所有数据都保存在主行存储中。行存储也是内存优化的,因此可以有效地处理数据更新。更新也会附加到增量存储中,增量存储将合并到列存储中。例如,Oracle 内存双格式数据库结合了基于行的缓冲区和基于列的内存压缩单元 (IMCU) 来一起处理 OLTP 和 OLAP 工作负载。文件和更改缓存在快照元数据单元 (SMU) 中。另一个例子是 SQL Server,它在 Hekaton 行引擎中的内存表上开发了列存储索引 (CSI),以实现实时分析处理。这种类型的 HTAP 数据库具有高吞吐量,因为所有工作负载都在内存中处理。
优势:
TP 吞吐量高AP 吞吐量高数据新鲜度高劣势:
AP 扩展能力低负载隔离性低应用:
高吞吐、低扩展(比如需要实时分析的银行系统)
案例研究1:Oracle Dual-Format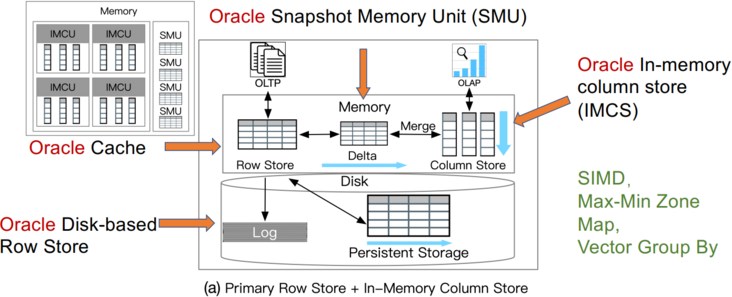
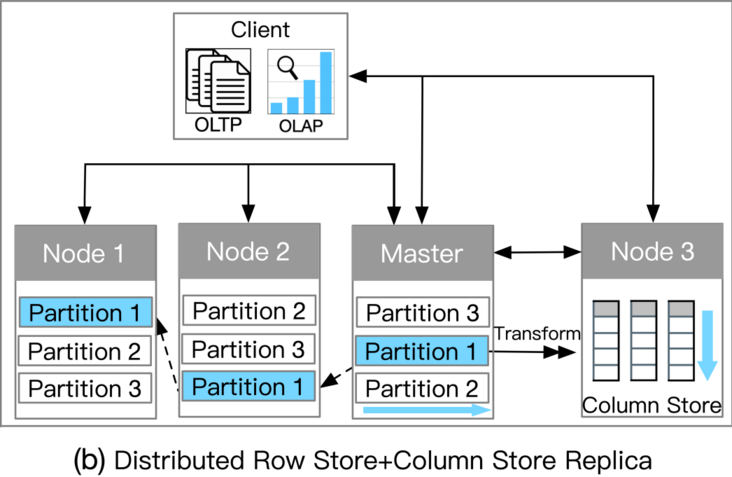
此类别依赖于分布式架构来支持 HTAP。主节点在处理事务请求时将日志异步复制到从节点。主存储为行存储,选择一些从节点作为列存储服务器进行查询加速。事务以分布式方式处理以实现高可扩展性;复杂查询在具有列存储的服务器节点中执行。
优势:
负载隔离性高扩展性高劣势:
数据新鲜度低应用:
对TP和AP扩展性要求比较高,同时能够容忍相对较低的数据新鲜度(比如需要实时分析的大规模电商系统)
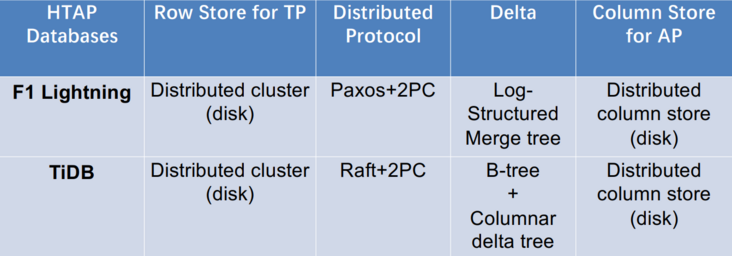
案例研究:F1 Lightning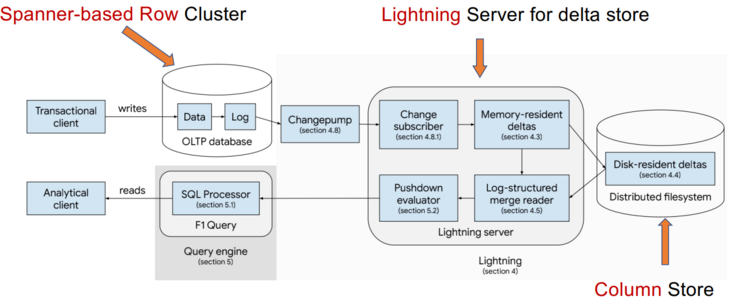
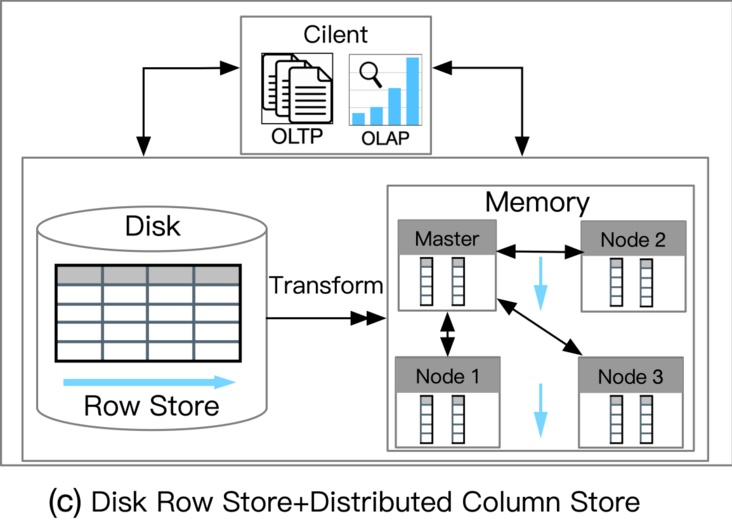
这种数据库利用基于磁盘的 RDBMS 和分布式内存列存储 (IMCS) 来支持 HTAP。 RDBMS 保留了 OLTP 工作负载的全部容量,并且深度集成了 IMCS 集群以加速查询处理。列数据从行存储中提取,热数据驻留在 IMCS 中,冷数据将被驱逐到磁盘。例如,MySQL Heatwave将 MySQL 数据库与称为 Heatwave 的分布式 IMCS 集群相结合,以实现实时分析。事务在 MySQL 数据库中完全执行。经常访问的列将被加载到 Heatwave。当复杂查询进来时,可以下推到IMCS引擎进行查询加速。
优势:
负载隔离性高AP吞吐量和扩展性高劣势:
数据新鲜度不高
Medium(On-premise):部署在本地,在不同机器上会有数据新鲜度的牺牲Low(Cloud-based):部署在云端,网络延迟会影响数据新鲜度应用:
对AP扩展性要求比较高,同时能够容忍相对较低的数据新鲜度(比如需要实时分析的IoT应用)
案例研究1:MySQL Heatwave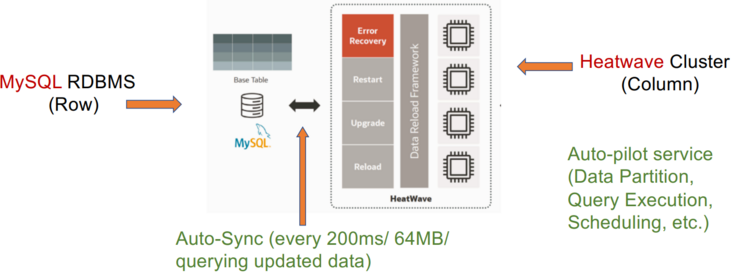
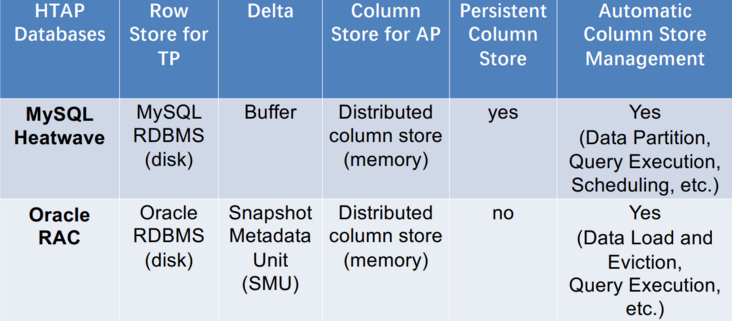
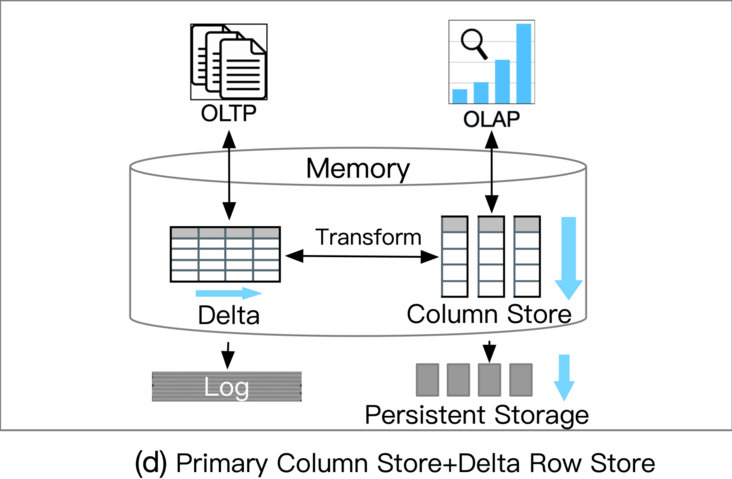
此类数据库利用主列存储作为 OLAP 的基础,并使用增量行存储处理 OLTP。内存中的 delta-main HTAP 数据库将整个数据存储在主列存储中。数据更新附加到基于行的增量存储。OLAP 性能很高,因为列存储是高度读取优化的。但是,由于 OLTP 工作负载只有一个增量行存储,因此 OLTP 的可伸缩性很低。一个代表是 SAPHANA 。它将内存中的数据存储分为三层:L1-delta、L2-delta 和 Main。 L1-delta以逐行格式保持数据更新。当达到阈值时,将 L1-delta 中的数据附加到 L2-delta。 L2-delta 将数据转换为列数据,然后将数据合并到主列存储中。最后,将列数据持久化到磁盘存储。
优势:
数据新鲜度高AP吞吐量高劣势:
TP可扩展性不高负载隔离性不高应用:
高AP吞吐量、高数据新鲜度(比如需要实时分析的风控系统)
案例1:SAP HANA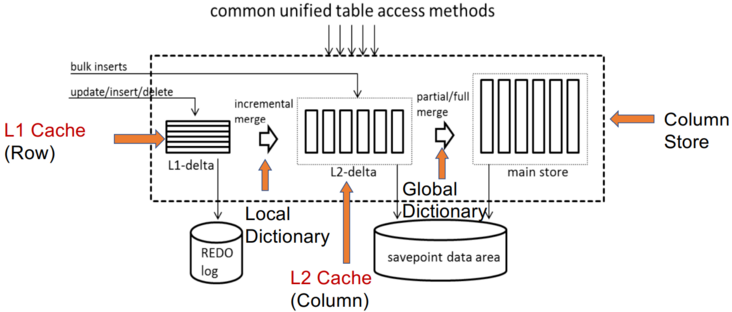
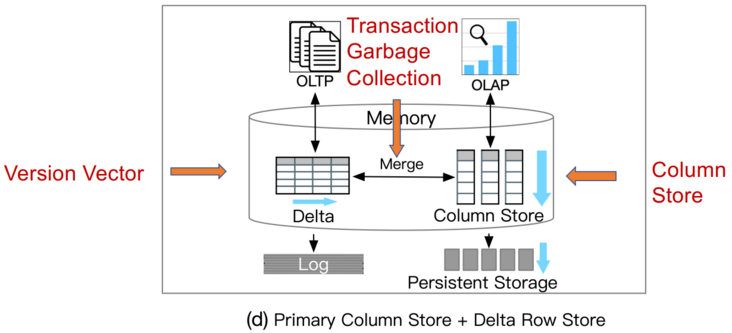
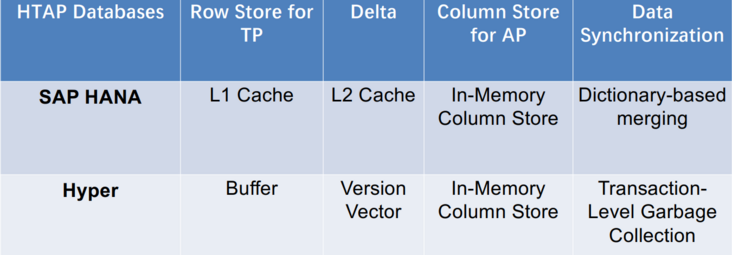
HTAP的相关技术包括(1)事务处理; (2)分析处理; (3) 数据同步;(4) 查询优化; (5)资源调度。这些关键技术被最先进的 HTAP 数据库采用。然而,它们在各种指标上各有利弊,例如效率、可扩展性和新鲜度等等。
这个部分我们留到下一篇文章再做讨论,欢迎大家关注StoneDB。
StoneDB 已经正式开源,欢迎关注我们
官网:https://stonedb.io/
Github: https://github.com/stoneatom/...
Slack: https://stonedb.slack.com/ssb...






.png)

.png)

