 云计算服务
云计算服务
 服务器租用
服务器租用
 DDOS 防护
DDOS 防护
 虚拟主机
虚拟主机
 域名服务
域名服务
 基础设施
基础设施
 关于我们
关于我们
title: 详解MySQL数据库之索引 author: 玄鸟轩墨 date: 2022-06-21 14:09:34 categories: MySQL tags: 数据库
写在前面前面我们都是学习MySQL的操作,很少涉及到理论,有些sql语法前面我都没有谈,主要是工作中不常用,一般就是增删查改.要是实际工作中遇到了可以自己稍微查一下,都是很简单的.今天我们谈一下MySQL中被面试官常问的两个部分,都是理论知识,需要我们有自己的理解.
索引我们先来解释一下什么是索引,这是我们的重点,它是属于MySQL数据库原理层面的知识,如果我们要是自己实现一个数据库,这里我们就要学习的很精通,要是我们岗位只是普通的程序猿,那么了解一下就可以了,至于如何用就不是我们现在这个层次考虑的了.
为何出现索引索引(index),就像是我们书的目录,我们根据目录可以快速的找到我们要看的章节,MySQL也是如此,索引在一定程度上可以加快我们查找数据的速率.
索引的缺点我们到工作的时候就会发现,你修改数据的次数是远远低于查找数据的次数的,比如我们现在写的博客,一般而言,我写完之后,就很少更改它了,除非是有朋友指出这里存在巨大的错误,我一般都是再重温博客的时候看到有哪里不合适或者错误才会修改,一般都是用来复习和观看的.
同理MySQL也是如此.我们查看是很频繁的.这里就会出现一个问题,对于数据比较少的,我们查早还是很不错的,但是对于公司的服务器而言,这个数据可以实千万级的,那么这个时候我们还是按照老方法查找数据,那么一个命令就要等较长的时间.这时候我们就出现索引,至于索引的原理是什么,这里我们不讨论,知道到这里就可以了.
前面我们只谈了索引可以提高效率,那么是索引难道就不存在缺点吗?我们想一下,书的目录是不是存在缺点,是的,最直观的一点就是废纸,同理索引是费空间.这就是索引最大的缺点.
索引的使用随着我们数据量的增大,索引消耗的空间也会越来越大,这还是不是最关键的,对于书来说,我们每一次修改书的内容,那么目录随之也要进行校准,确保可以指定的位置是是准确的,同理MySQL也是如此.不过看起来索引有很大缺点,但是和优点相比较很微小的,瑕不掩瑜.我们在公司里面推荐用索引.
注意,这里的使用只是一点皮毛,甚至连皮毛都算不上,我们不学习使用索引.这里还要和大家谈一个东西,索引的创建最好在创表的时候就出现,要是你在数据比较的多的表来创建索引,那么有极大概率这个数据库会崩,所以要创就在开始的时候创建.
我们先来创建一个数据库,用来查看一下索引.
create table student (
id int primary key,
name varchar(50),
score decimal(3,1)
);
这里我们就可以查看这个数据表的索引了.
-- 格式 show index from 表民;
show index from student;

这里我们就会疑惑了,我们好象是没有添加索引的那么这里为何会出现一个索引,准确来说,我们一个字段被主键或者唯一来约束,这一列就看做一个索引.我们的id就是一个索引.也就是说我们使用主键约束的时候还加快的查早的速率.
同理这里我们也可以给某一列添加索引.
-- create index 索引名字 on 表名(列名);
create index name_index on student(name);

同理这里我们也可以删除索引,这里只做简单的演示.注意这里容易把数据库给搞挂.
drop index name_index on student;
这里才是我们索引的重点,也是面试官比较喜欢问的.这里我们要好好的解释下.我们之前学了一点简单的数据结构,有顺序表,链表,二叉搜索树,哈希表等等,那么我们在想索引的底层是什么?
这里我们首先先排除三个,至于后面的二叉搜索树,可以不可以,这就是我们要讨论的了.

我们感觉二叉搜索树还是挺不错的,不过这里有个问题,我们好象查找数据的时候每一次都要比较,那么如果数据多了,树就高了,对于数据库每一次都意味着文件IO.这里还是不要太行.那么索引的底层究竟是什么?这里我们就要谈一个新的数据结构B+树.不过在谈这个树前,我们先来谈一下B树.注意,我们谈的数据库是MySQL,我这里只知道MySQL的索引是B+树,至于其他的是什么这里就不太清楚了.
B/B-树我们先来解释一下这个名称,B树又叫B-树,记者B-树可不是念B建树,它是B树的另一个名称,从来没有什么B减树.这里算是解决一下我们的疑惑.
B树是一个N叉树,这个N叉比较特殊.对于树的每一个节点存在若干个数据把这个节点分为若干个区域.我们这里直接看树的的结构.
一个节点里面存在N个数据,把这个节点分为N+1个区域,每一个区域有指向一个新的节点,这就是B树.
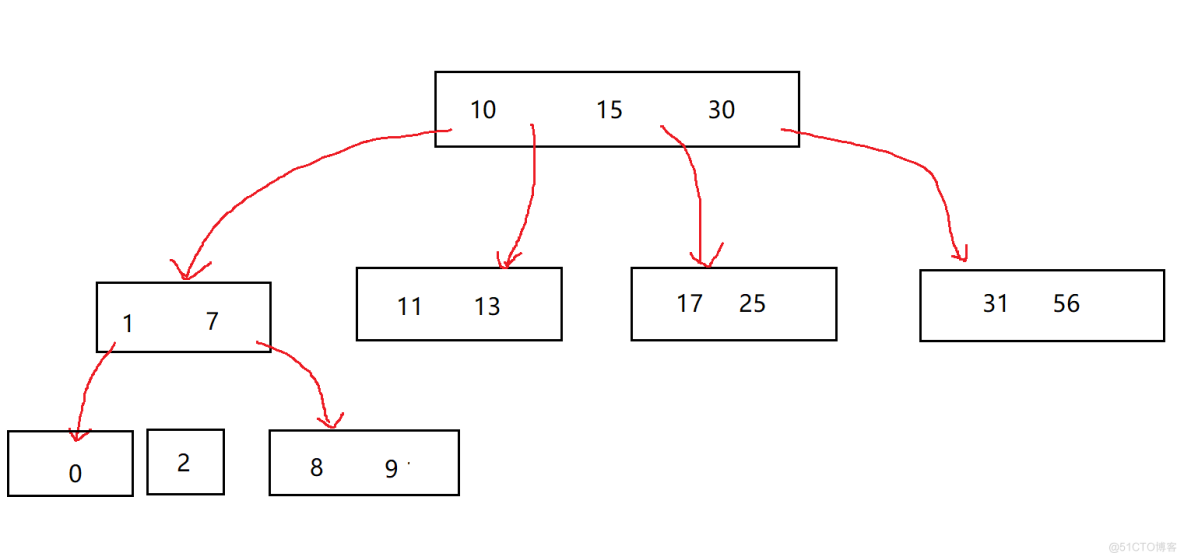
B+树这里我们简单的说一下B树的查找规则,这个和二叉搜索树是一样的,我们先来从根节点出发,根据比较来确定一个一个区域,这里逐渐寻找我们的数据.这里我们就疑惑了,这也是比较,而且比较的次数好象没有变少,那么这里就出现问题了,B树为何会提高索引的效率.这里由于我们还没有分享过文件IO,我先来说下,B树是不是高度变短了,这就就意味着以节点为基础比较变得少了,而磁盘IO也是根据节点的次数来计算的,所以这里提高效率了.
B+树是在B树的基础上再次衍生出来的,基于索引而言,B+树是更加优秀的.我们现来看一下B+树的结构.
B+树中每一个父节点的值会作为子节点的最大或者最小值,叶子节节点中会体现出来,而且对于叶子节点而言,我们使用指针把它给串联出来.
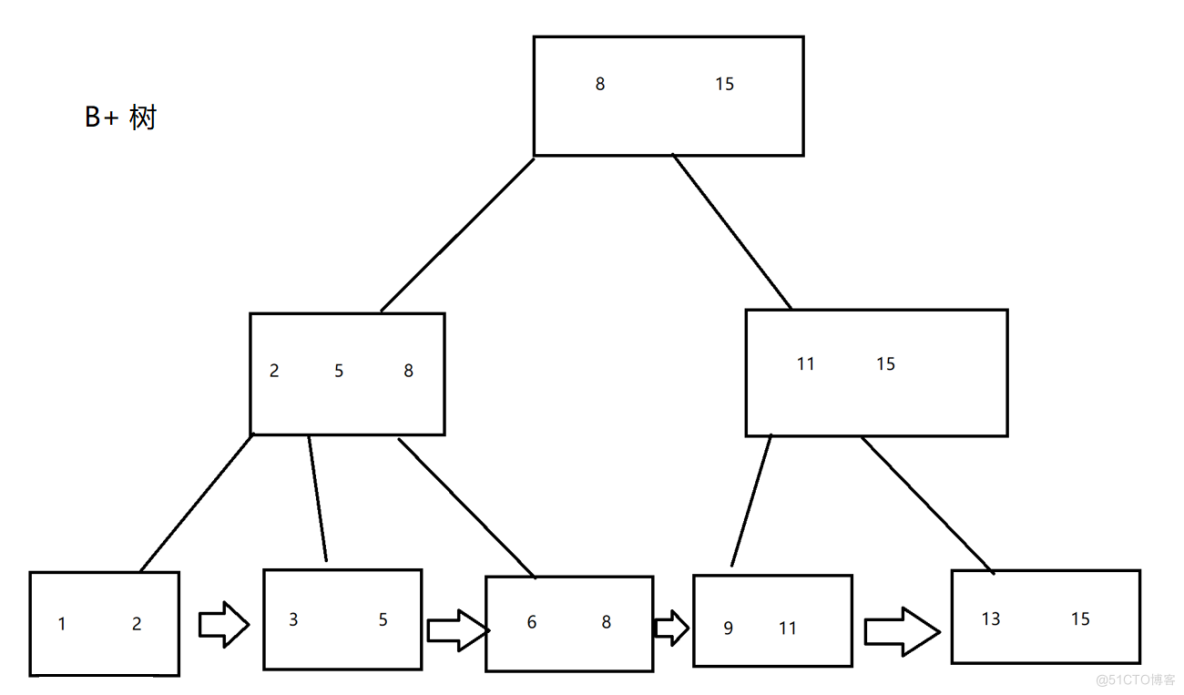
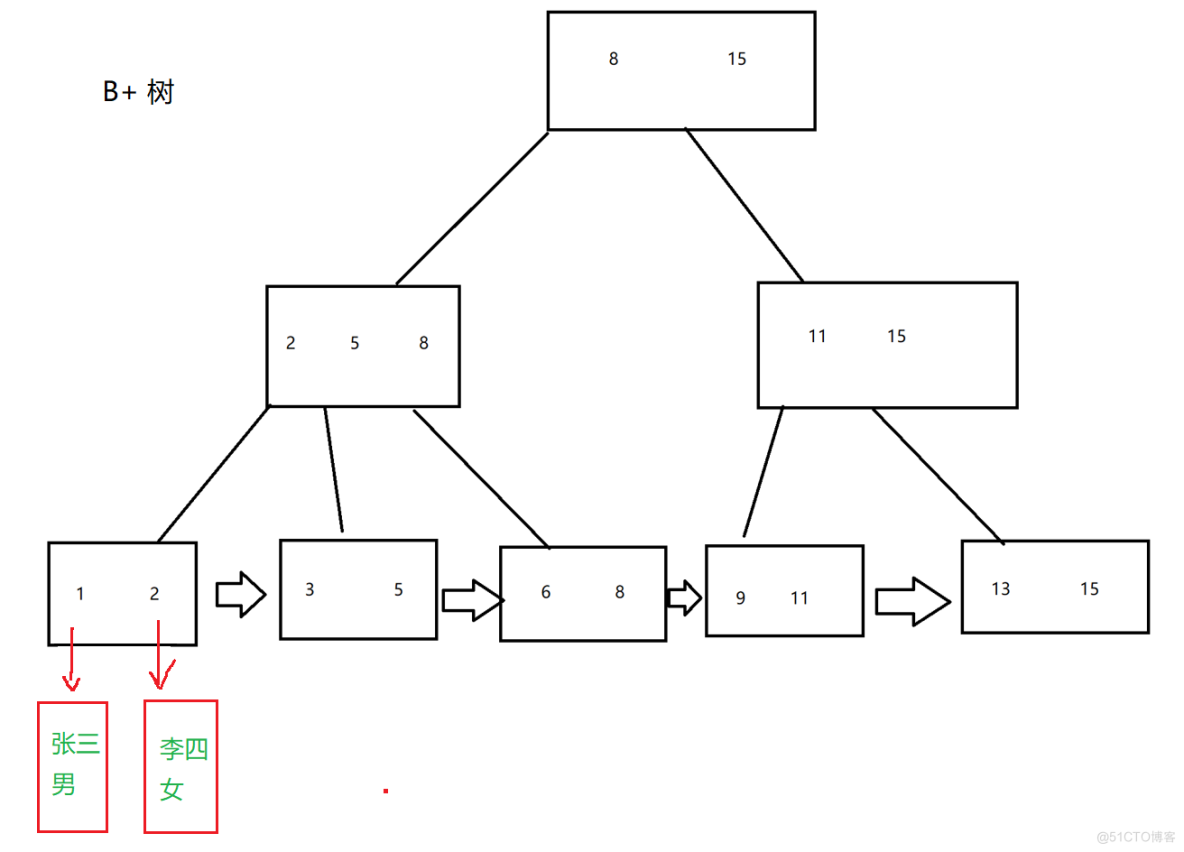
树变短了,总体的IO次数变少了所有的查询终究会落在叶子节点上,查询速度稳定叶子节点通过链表链接出来后,很适合范围查找所有的载荷都是放在叶子节点上的,非叶子节点只保存key值.这里我们就要下一个结论了,B+树可以说是完美的给MySQL索引设计的,我们看一下它的优点.
这里我先来解释一下最后一条,说人话就是我们把所有的数目只保留在在叶子节节点.这样我们的非叶子节点占据的空间很少,甚至可以在在内存中跑,这样也能大大减少磁盘IO,提高速率.
上面总算是把索引谈的差不多了,这里还要接触这个知识点.事物还是一个比较好理解的知识点.我们先来看一下什么是事物.
事物,可以理解成打包,就是把几个工作一起做了,也就是要做都做,要不做都不做.
我们举一个例子,假设我要和自己的女朋哟去约会,首先第一点我要去ATM机中取钱,取完钱之后,我发现我女朋友鸽了我,这时候就是是一个很悲伤的故事.但是如果我们把这两个步骤打包成一个事物,也就是不会存在第一个步骤执行完了第二个步骤不会执行的情况.
原子性那么我们就有问题了,事物是通过什么来保证的,这就要涉及到原子性了,这个算是线程里面的内容.我先来解释,在过去,人们认为原子是物质的最小单位,这里就用这个来命名了,没有其他的含义.我们再来举一个例子.假设存在一张账户表.

现在我们要做的就是A要给B转500元,就会执行下面的操作.假设第二步的时候出现了问题,也就是A的钱被扣了,但是B没有收到钱,至于造成这样的原因有很多种,比如服务器不小心断电了,数据库崩了等等.显然我们的原子性就是为何避免这种情况的发生.

事务的保证就是下面的两条规则
要么都执行要么都不执行现在我们就疑惑了,我们该如何保证事务,要知道我们执行的结果成不成功是需要执行过之后才发现的,你这个规则好象把路给堵死了,这里的要不都不执行是需要带引号的,所谓的要不都不执行,是我们确实执行,如果成功了,万事大吉,错误了就把他给恢复回去,这种模式叫做回滚.至于如何恢复才是我们重点讨论的.还按照上面的例子来讨论,假设我们执行了第一个步骤,也就是A减去500,执行第二步出现了问题,导致无法执行,我们好象没有给B加上500.
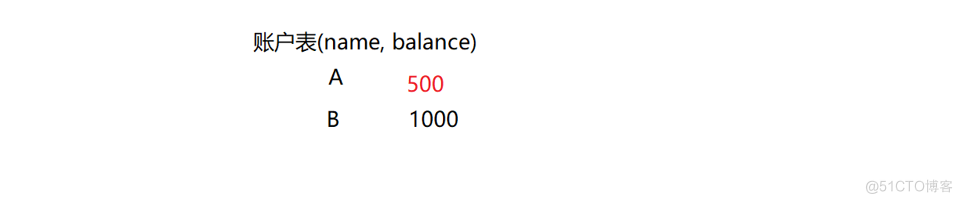
这个时候数据库就会进行回滚,上一个步骤我们给A减去500,回滚的时候给A加上500,让它变回原来的样子.那么请问数据库是如何知道要给A加上500这个正确的操作的,这就又涉及到另外一个东西了.数据库会拿出一个小本本,把过去一段时间的操作记录下来,这就是我们传说中的日志.
事务的使用我们好象还是没有谈过事务的使用,这里简单看一下就行了,也不是面试官主要的考点.
开启事务:start transaction; 2)执行多条SQL语句回滚或提交:rollback/commit说明:rollback即是全部失败,commit即是全部成功.
start transaction;事务的特性
-- 阿里巴巴账户减少2000
update accout set mnotallow=money-2000 where name = '阿里巴巴';
-- 四十大盗账户增加2000
update accout set mnotallow=money+2000 where name = '四十大盗';
commit;
面试官最喜欢问的问题就是事务的几个特性,这里我先总结下,后面还有好好谈谈.
原子性一致性持久性隔离行原子性前面我们已经分析过了,这里我先来谈一下一致性,事务一旦执行,执行的结果必须是合理合法的,也就是说余额不能出现为负数的情况.持久性也就是数据一旦正确存入,就会保存到硬盘中,被持久化存储起了.
隔离性事务的隔离性在是在并发执行时体现的,并发是我们现在计算机常用的方法.
并发这里我先来解释一下什么是并发执行.在我们使用计算机的时候,你会发现很多程序都在跑,不过CPU的个数远远要小于程序的个数,这个时候就会出现不够用的问题,并发在一定的程度上解决了这个问题,就是一般一个程序只占据CPU一段时间,然后换下一个.
脏读不可以重复读这个是我们要重点谈的,可以说是它太重要的.我们先来假设一个场景,我的老师正在那里写代码,准备给我们布置作业,我偷偷的看了一眼,看到一个student类,那时候我就明白了,我们的作业和student类有关.我回去准备相关的知识了,到是在我走后,老师把题目给改了,这就是脏读问题.
我吃了脏读的亏,这个时候我就比较小心了,我等到老师把代码写完,然后把他给上传到GitHub上,我在GitHub上读代码.这个模式算是老师写的时候我不能读,等到老师写完我读的代码就正确了.但是这里又出现了问题,我们没说毒的时候不能写啊,我在读第二遍的时候,老师把代码给改了.这个时候就是不可以重复的问题.

我们这个时候和老师在约定一下,我们读的时候你也不能写,这个在一定程度上解决了一不可重复读问题,但是这个真的很完美吗?这个时候老师的等的很无聊,既让我们不能修改原来的代码,那么我这里写另外一个代码总可以了吧.
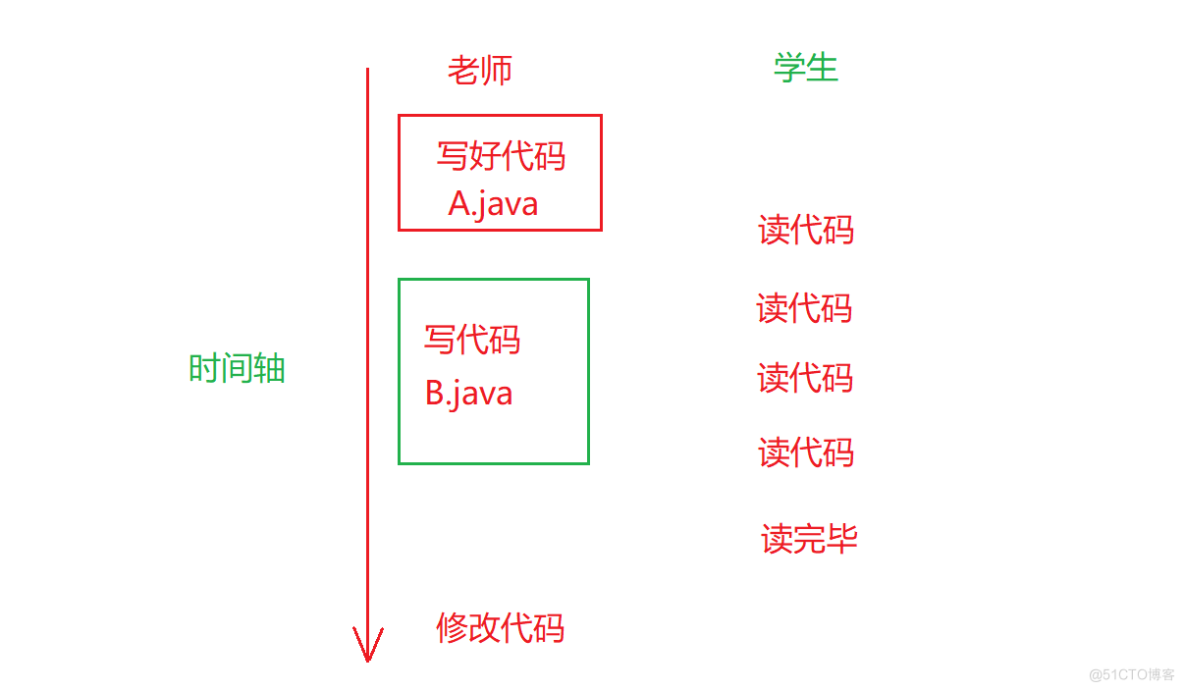
这个时候又会出现另外一个问题,我们每一次刷新GitHub,有的代码一会有,一会没有,感觉是幻觉一样,这个就是幻读,算是一种特殊的不可重复读问题,要解决这个问题要彻底串行化执行.也就是老师写好了之后,可以直接去摸鱼了,我在这里观看就可以了.






.png)

.png)

