 云计算服务
云计算服务
 服务器租用
服务器租用
 DDOS 防护
DDOS 防护
 虚拟主机
虚拟主机
 域名服务
域名服务
 基础设施
基础设施
 关于我们
关于我们
在数据分析中,我们一般不会像前几篇文章那样自己创造数据,而是需要利用外部数据。本篇要解决两个问题:
如何将外部数据导入,并转换为 DataFrame?如何将 DataFrame 导出为常用的文件格式?4.1 读取文本数据本篇文章用到的数据,可以从 GitHub 上下载:https://github.com/wesm/pydat...
4.1.1 csv 数据:处理标题行我们可以从 csv 数据入手,看看如何将 csv 数据导入为 DataFrame:

in: df = pd.read_csv('examples\ex1.csv')
df
out: a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo如果你用的是 PyCharm IDE 的话,看看 Console 中的变量部分,变量 “df” 的右边会有一个 “view as DataFrame” 的按钮。点击它,你可以看到这样的视图:
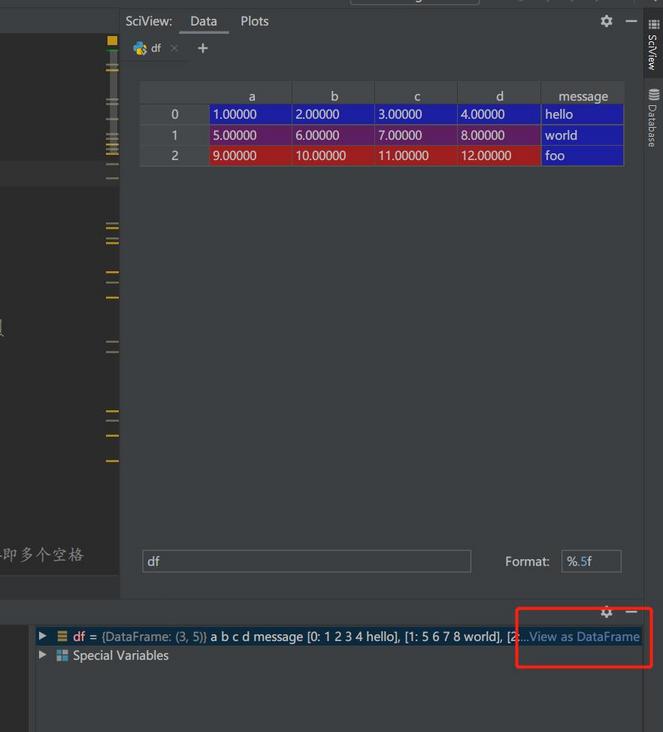
这个视图在数据量很大的时候很有用,能帮你粗略地检视数据。
除了 pd.read_csv() 外,pandas 还提供了读取其他形式数据的方法,如 pd.read_table(), pd. read_json(), pd.read_excel() 等。
pd.read_table('examples\ex1.csv', sep=',') # 由于 pd.read_table() 的默认分隔符是 tab,我们需要手动指定一下,以打开我们的文件如果文件没有标题行(字段名/列名),该怎么做?
in: pd.read_csv('examples\ex2.csv')
out: 1 2 3 4 hello # 可以看到,pandas 默认认为第一行是标题行,这和我们想要的结果不符
0 5 6 7 8 world
1 9 10 11 12 foo
in: pd.read_csv('examples\ex2.csv', header=None) # 这样就可以让 pandas 不把第一行视为标题行
out: 0 1 2 3 4 # pandas 默认生成了一行连续数作为标题行
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
in: pd.read_csv('examples\ex2.csv', names=['a','b','c','d','message']) # 可以像这样给每列取个名字
out: a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
in: pd.read_csv('examples\ex2.csv', names=['a','b','c','d','message'],index_col='message') # 还可以把 message 这列作为 DataFrame 的行索引
out: a b c d
message
hello 1 2 3 4
world 5 6 7 8
foo 9 10 11 12csv 数据相对来说更规则,那么如何读取 txt 数据呢?
我们来看个 txt 数据的例子:
in: with open('examples\ex3.txt','r') as f: # 这样可以用普通的 python 方法打开一个 txt 文件
print(f.read())
out: A B C
aaa -0.264438 -1.026059 -0.619500
bbb 0.927272 0.302904 -0.032399
ccc -0.264273 -0.386314 -0.217601
ddd -0.871858 -0.348382 1.100491 # 看上去十分整洁
in: list(open('examples\ex3.txt')) # 换种方式看看
out: [' A B C\n', 'aaa -0.264438 -1.026059 -0.619500\n', 'bbb 0.927272 0.302904 -0.032399\n', 'ccc -0.264273 -0.386314 -0.217601\n', 'ddd -0.871858 -0.348382 1.100491\n']
# 可以看到这个 txt 文件中,充斥着分隔符,分隔符包括:单个空格、多个空格和换行符现在让我们来将这个 txt 数据导入为 DataFrame:
in: df = pd.read_table('examples\ex3.txt')
df
out: A B C
0 aaa -0.264438 -1.026059 -0.619500
1 bbb 0.927272 0.302904 -0.032399
2 ccc -0.264273 -0.386314 -0.217601
3 ddd -0.871858 -0.348382 1.100491 # 这个结果看上去很好
in: df.columns # 但如果我们看看它的列标签,我们就会知道这不是我们想要的结果
out: Index([' A B C'], dtype='object')出现上述问题的原因是,不同的分隔符让 pandas 难以识别行与列的分隔。如何解决这个问题呢?我们可以像前面提到的,指定 sep 参数,让 pandas 识别出分隔符。但是分隔符包括单个空格、多个空格和换行符,如何表示这三种分隔符呢?我们用到了正则表达式:
# 此处用到了正则表达式:\s 代表空格和换行符,+ 代表可以包括1个至多个加号前面的字符——即多个空格
in: df = pd.read_table('examples\ex3.txt',sep='\s+')
df.columns
out: Index(['A', 'B', 'C'], dtype='object') # 这回是我们想要的结果了有的人在编写表格时,喜欢在表格的前几行备注一些信息。我们需要跳过无意义的备注信息。
比如这个文件 “examples\ex4.csv”:
# hey!
a,b,c,d,message
# just wanted to make things more difficult for you
# who reads CSV files with computers, anyway?
1,2,3,4,hello
5,6,7,8,world
9,10,11,12,foo我们想要跳过无意义的第1、3、4行,只需要指定 skiprows 参数就可以了:
in: pd.read_csv('examples\ex4.csv',skiprows=[0,2,3])
out: a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo如今,我们处理表格数据最常用的软件就是 Excel,保存下来的表格文件,通常是 xlsx 文件。我最常用的打开此类数据的方式是:
path = r'一个数据.xlsx'
df = pd.read_excel(path, engine='openpyxl', dtype=object, keep_default_na=False)让我来解释一下 pd.read_excel() 中我使用的参数:
之前曾经出现过 Excel xlsx file; not supported - 简书 (jianshu.com) 这篇文章描述过的错误,因此我导入 xlsx 文件是通常会把 engine 参数设置为 'openpyxl'。但现在似乎不再需要了。dtype 设置为 object,可以保留数据的原貌keep_default_na = False 可以不将缺失值设置为 NaN4.1.5 缺失值处理让我们来看一个有缺失值的数据:
in: pd.read_csv('examples\ex5.csv')
out: something a b c d message
0 one 1 2 3.0 4 NaN # 可以看到,里面包含缺失值
1 two 5 6 NaN 8 world
2 three 9 10 11.0 12 foo如果你不想让缺失值表现为 NaN,那么可以像上面一样,设置 keep_default_na = False。
如果除了空值,其他的某个值(比如 foo)也代表缺失值,我们想让等于 foo 的值也表现为 NaN:
in: pd.read_csv('examples\ex5.csv',na_values=['foo'])
out: something a b c d message
0 one 1 2 3.0 4 NaN
1 two 5 6 NaN 8 world
2 three 9 10 11.0 12 NaN我们在处理从网上爬到的数据时,往往需要处理 JSON 数据。如:
in: obj = """
{"name": "Wes",
"places_lived": ["United States", "Spain", "Germany"],
"pet": null,
"siblings": [{"name": "Scott", "age": 30, "pets": ["Zeus", "Zuko"]},
{"name": "Katie", "age": 38,
"pets": ["Sixes", "Stache", "Cisco"]}]
}
""" # 我们定义一个 JSON 数据
obj # 我们得到了一个 JSON 格式的字符串
out: '\n{"name": "Wes",\n "places_lived": ["United States", "Spain", "Germany"],\n "pet": null,\n "siblings": [{"name": "Scott", "age": 30, "pets": ["Zeus", "Zuko"]},\n {"name": "Katie", "age": 38,\n "pets": ["Sixes", "Stache", "Cisco"]}]\n}\n'为了能够处理这个 JSON 字符串,我们需要将它转换为 Python 的字典形式:
in: import json
result = json.loads(obj) # 我们通过 json.loads() 进行转换
result # 可以看到,现在它变成了一个字典
out: {'name': 'Wes', 'places_lived': ['United States', 'Spain', 'Germany'], 'pet': None, 'siblings': [{'name': 'Scott', 'age': 30, 'pets': ['Zeus', 'Zuko']}, {'name': 'Katie', 'age': 38, 'pets': ['Sixes', 'Stache', 'Cisco']}]}现在,这个数据就可以转化为 DataFrame 处理了:
in: pd.DataFrame(result['siblings']) # 传入字典列表
out: name age pets
0 Scott 30 [Zeus, Zuko]
1 Katie 38 [Sixes, Stache, Cisco]
in: pd.DataFrame(result['siblings'],columns=['name','age'])
out: name age
0 Scott 30
1 Katie 38Python 字典同样可以转换回 JSON 字符串:
in: json.dumps(result) # 我们通过 json.dumps() 进行转换
out: '{"name": "Wes", "places_lived": ["United States", "Spain", "Germany"], "pet": null, "siblings": [{"name": "Scott", "age": 30, "pets": ["Zeus", "Zuko"]}, {"name": "Katie", "age": 38, "pets": ["Sixes", "Stache", "Cisco"]}]}'当然,pandas 也可以直接读取 JSON 文件,但是 JSON 文件的格式最好规整。
in: pd.read_json('examples/example.json')
out: a b c
0 1 2 3
1 4 5 6
2 7 8 9在处理大文件时,我们常常希望读取其中的一小块。
比如这个有 10000 行数据的文件:
# 为了显示好看,我们先让 pandas 在展示时只显示 10 行
pd.options.display.max_rows = 10 # 让 pandas 在展示的时候只显示10行
in: df = pd.read_csv('examples/ex6.csv')
df
out: one two three four key
0 0.467976 -0.038649 -0.295344 -1.824726 L
1 -0.358893 1.404453 0.704965 -0.200638 B
2 -0.501840 0.659254 -0.421691 -0.057688 G
3 0.204886 1.074134 1.388361 -0.982404 R
4 0.354628 -0.133116 0.283763 -0.837063 Q
... ... ... ... ..
9995 2.311896 -0.417070 -1.409599 -0.515821 L
9996 -0.479893 -0.650419 0.745152 -0.646038 E
9997 0.523331 0.787112 0.486066 1.093156 K
9998 -0.362559 0.598894 -1.843201 0.887292 G
9999 -0.096376 -1.012999 -0.657431 -0.573315 0
[10000 rows x 5 columns]为了逐块读取文件,我们需要指定块的大小。比如,我们按一块 1000 行来读取。
chunker = pd.read_csv('examples/ex6.csv', chunksize=1000) # 这个东西是个迭代器
tot = pd.Series([])
for piece in chunker: # 这样就可以逐块处理了
tot = tot.add(piece['key'].value_counts(), fill_value=0)表格数据我们通常会导出为 csv 或 xlsx 文件。这样就可以导出了:
data = pd.read_csv('examples/ex5.csv') # 首先我们读一个文件
path = r"一个文件.csv"
data.to_csv(path) # 这样就导出了
path = r"一个文件.xlsx"
data.to_excel(path, index=False) # 将 index 设置为 False 可以不输出索引注:转载请注明出处。
本文属于《利用 Python 进行数据分析》读书笔记系列:
利用 Python 进行数据分析 —— 1 数据结构、函数和文件
利用 Python 进行数据分析 —— 2 NumPy 基础
利用 Python 进行数据分析 —— 3 pandas 入门






.png)

.png)

