 云计算服务
云计算服务
 服务器租用
服务器租用
 DDOS 防护
DDOS 防护
 虚拟主机
虚拟主机
 域名服务
域名服务
 基础设施
基础设施
 关于我们
关于我们
已经有了管理主从集群的哨兵,为什么还需要推出切片集群呢?我认为有两个比较重要的原因:
N/2+1
下面来聊聊 Redis cluster 是如何解决这两个问题的。
什么是切片集群切片集群是一种水平扩展的技术方案,它的主体思想是增加 Redis 实例组成集群,将原来保存在单个实例的上数据切片按照某种算法分散在各个不同的实例上,以减轻单个实例数据过大时同步和持久化时的压力。同时,水平扩展方案和垂直扩展方案相比扩展性更强,受硬件和成本的影响更小。

目前主要的实现方案有官方的 Redis Cluster 和 第三方的 Codis。Codis 在官方的 Redis Cluster 成熟之后已经很久没有更新了,这里就不特别介绍了,主要介绍下 Redis Cluster 的实现。
数据分区切片集群实际就是一个分布式的数据库,而分布式数据库首先要解决的问题就是如何把整个数据集划分到多个节点上。
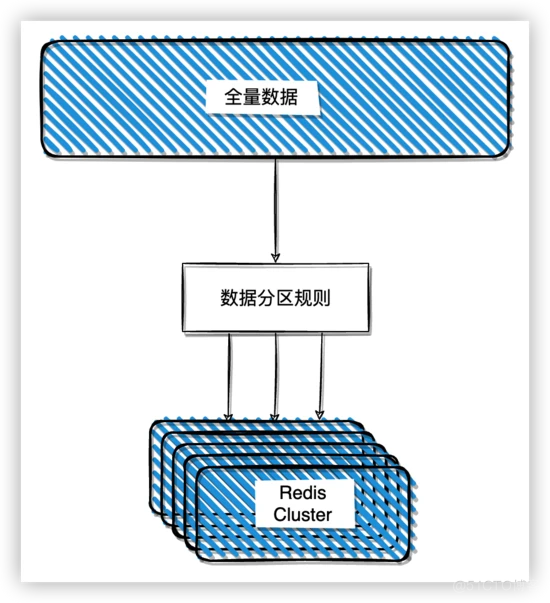
Redis Cluster 采用的是虚拟槽的分区技术。Redis Cluster 一共定义了 16384 个槽,数据与槽关联,而不是和实际的节点关联,这样可以很好的将数据和节点解耦,方便数据拆分和集群扩展。通常情况下,Redis 会将槽平均分配到节点上,用户可以使用命令 cluster addslots 来手动分配。需要注意的是,手动分配哈希槽时必须要把 16384 个槽都分配完,否则 Redis 集群会无法工作。
映射到节点的流程有两步:
根据 key 计算一个 16 bit 的值,然后将这个值对 16384 取模,得到 key 应该落在哪个槽上: crc16(key) % 16384。Redis Cluster 搭建完成的时候会预先分配每个节点负责哪几个槽的数据,客户端连接到集群的时候会获取到映射关系,然后客户端会将数据发送到对应的节点上。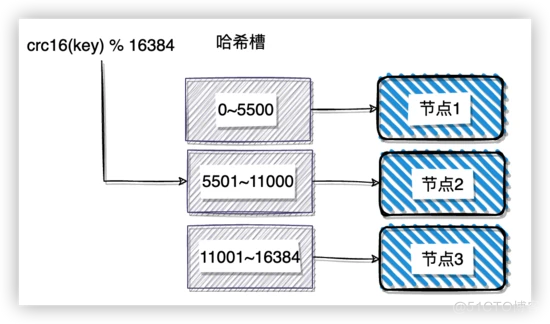
集群功能目前有一些功能限制:
mset、mget 等批量操作、事务操作,lua 脚本只支持对落在同一个 slot 上 key 进行操作。集群只能使用一个 db0,而不像单机 Redis 可以支持 16 个 db。主从复制不支持联级主从复制,即从库只能从主库同步数据。哈希标签(hash tag)为了解决上述的第一个问题,Redis Cluster 提供了哈希标签(hash tag)功能,例如有两条 Redis 命令:
set Hello world
set Hello1 world
这两个操作的 key 可能不会落在同一个槽上。这时候如果将 Hello1 改成 {Hello}1,Redis就会只计算被{}包围的字符串属于那个槽,这样这两个命令的 key 就会落在同一个槽上,就可以使用 mset、事务、lua 脚本来处理了。
可以使用命令cluster keyslot <key>来验证两个 key 是否落在同一个槽上。
127.0.0.1:30001> cluster keyslot hello请求重定向
(integer) 866
127.0.0.1:30001> cluster keyslot hello1
(integer) 11613
127.0.0.1:30001> cluster keyslot {hello}1
(integer) 866
如果没有使用哈希标签,如果 Redis 命令中 key 计算之后的哈希值不是落在当前节点持有的槽内,节点会返回一个 MOVED 错误,告诉客户端该操作应该在哪个节点上执行:
127.0.0.1:30006> set hello1 world
(error) MOVED 11613 127.0.0.1:30003
127.0.0.1:30006>
节点是不会处理请求转发的功能,我们启动 redis-cli 的时候可以添加一个 -c 参数,这样,redis-cli 就会帮我们转发请求了,而不是返回一个错误:
$ redis-cli -p 30006 -cACK重定向
127.0.0.1:30006> set hello1 world
-> Redirected to slot [11613] located at 127.0.0.1:30003
OK
当集群进行伸缩重新分配槽的时候,如果有请求需要处理落在迁移中的槽上,那么 Redis Cluster 会怎么处理呢?
Redis 定义了一个结构clusterState来记录本地的集群状态,其中有几个成员来记录槽的信息:
typedef struct clusterState {
...
clusterNode *migrating_slots_to[CLUSTER_SLOTS]; //记录槽转移的目标节点
clusterNode *importing_slots_from[CLUSTER_SLOTS]; //记录槽转移的源节点
clusterNode *slots[CLUSTER_SLOTS]; //记录集群中槽所属的节点
...
} clusterState;当开始重新分配槽时,拥有槽的原节点会将目标节点记录到migrating_slots_to中,目标节点会将原节点信息记录到importing_slots_from中,重分配槽的过程中,槽的拥有者还是原节点。
此时原节点收到操作命令时,如果在本地找不到数据,会在migrating_slots_to中找到目标节点信息,然后返回 ACK 重定向来告诉客户端对应的数据正在迁移到目标节点。
$ redis-cli -p 6380 -c get key:test:5028
(error) ASK 4096 127.0.0.1:6380
收到 ACK 之后,不像 MOVED 错误一样直接到对应的节点上执行命令就可以了,首先需要发送一个 ASKING,然后再发送实际的命令。这是因为在重分配槽的过程中,槽的所有者还没有发生改变,如果直接向目标节点发送命令,目标节点会直接返回 MOVED 错误,因为目标节点在本地的clusterState→slots中并没有发现 key 所属的槽分配给了自己。
需要注意的是 ASKING 命令是临时的,收到 AKSING 命令后会开启 CLIENT_ASKING(askingCommand 函数),执行完命令后会将 CLIENT_ASKING 状态清除(resetClient函数)。
在搭建好的集群中,插入 3 条数据:
mset key:test:5028 world key:test:68253 world key:test:79212 world
这三个 key 都落在槽 4096 上。我们在集群中加入一个新节点 6380,准备将槽 4096 的数据迁移到 6380 节点上:
redis-cli -p 6380 cluster setslot 4096 importing 750c1ac1e53b8e33da160e7e925be98a37c8b1f3
redis-cli -p 30006 cluster setslot 4096 migrating 8557dbdfdb08a9a939cf526d74d7e35e0dc4b478
importing命令在 6380 上执行,指定 4096 槽的原节点的 runId,migrating 命令指定 6380 的 runId,runId 使用命令cluster nodes查看。
然后将key:test:5028key:test:68253先迁移到 6380 :
redis-cli -p 30006 migrate 127.0.0.1 6380 "" 0 5000 KEYS key:test:5028 key:test:68253
此时在 30006 上查询key:test:79212的数据是可以正常返回的,而查询其它两个 key 都会返回错误:
(error) ASK 4096 127.0.0.1:6380
其它写操作也都会返回这个错误。
然后在 6380 上执行 get key:test:5028 会返回 MOVED 错误,因为此时槽还没有迁移完成,槽的拥有者还是 30006:
127.0.0.1:6380> get key:test:5028
(error) MOVED 4096 127.0.0.1:30006
需要先执行 ASKING 命令,在执行其它命令:
127.0.0.1:6380> askingsmart 客户端
OK
127.0.0.1:6380> mget key:test:5028
"world"
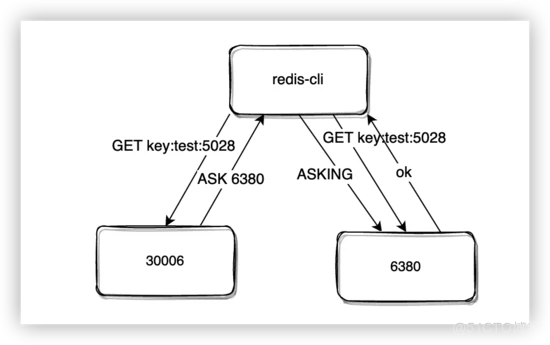
如果要求在往节点写数据的时候重定向到实际执行命令的节点,想想都觉得这是一个比较低效的实现方式,并且增加了网络开销。所以,通常 Redis 客户端采用的实现方式是在本地缓存一份槽和节点的映射关系,这个映射关系使用命令cluster slots可以获取。在处理请求的时候,先根据本地的映射关系往对应节点发送请求,如果收到的MOVED错误,客户端会将数据发送到正确的节点,并且更新本地的映射关系。
Redis 源码里附带了一个脚本可以快速搭建集群,这个脚本在 utils/create-cluster 目录中。
启动节点。使用命令./create-cluster start来启动节点,该脚本会启动 6 个节点。$ ./create-cluster start
Starting 30001
Starting 30002
Starting 30003
Starting 30004
Starting 30005
Starting 30006
使用 ls 命令查看一下当前目录,会发现主要生成了三种文件:节点运行日志( <redis-port>.log)、持久化文件目录(appendonlydir- <redis-port>)、集群节点信息文件(nodes- <redis-port>.conf)。</redis-port></redis-port></redis-port>建立集群。使用命令
./create-cluster create会自动建立集群关系。执行成功后,查看集群节点信息文件,会看到不同节点的角色,runId,ip,port,以及分配到该节点的槽范围: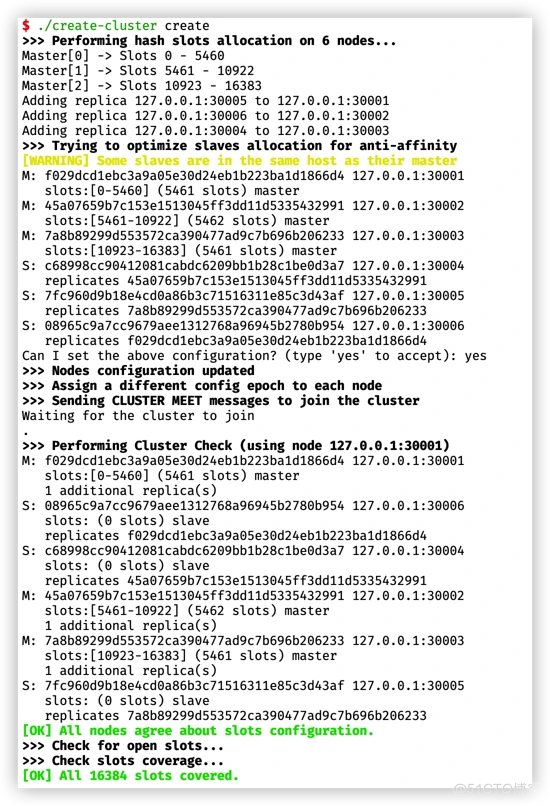
官方的这个脚本让我们很快就能拥有一个可以测试的集群,它把很多细节都隐藏起来了,我们来手动搭建一个集群,顺便理一下 Redis Cluster 到底做了哪些事情。
启动节点启动一个集群模式的节点需要在配置文件中开启集群模式:
cluster-enabled yes
在同一个机器上运行的话每个节点还要指定不同的端口,以及要指定节点信息保存文件,这个文件会保存集群的元数据:
port 6382
cluster-config-file "nodes-6382.conf"
其它和集群相关的配置可以查看官方文档,本文不做过多赘述。
redis-server node-6380.conf
redis-server node-6381.conf
redis-server node-6382.conf
启动的集群节点会有两个端口,一个端口是面向客户端连接的(6379,下称其为面向客户端口),另个一端口会在该端口上加 10000 用作集群内部通信使用(16379,下称其为面向总线接口)。可以使用命令netstat -anp | grep redis-server查看应用程序的网络信息:

启动的三个节点是相互独立的集群,那么如何告知这三个节点对方的信息,让它们组成集群呢?
cluster meet {ip} {port}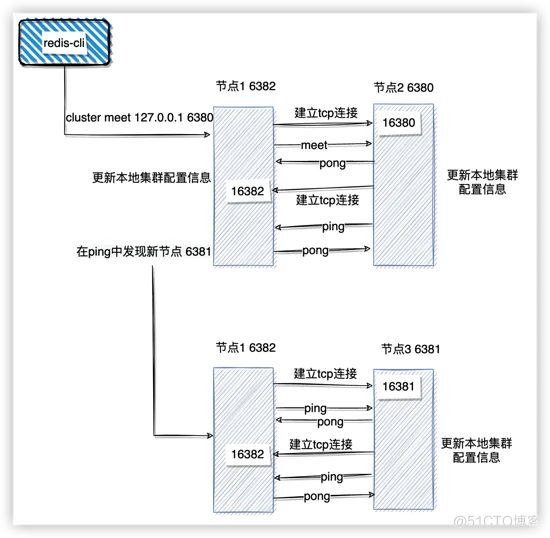
节点握手完成之后,使用命令 cluster nodes 查看节点状态:

字段含义会在下面进行说明。
分配槽节点握手之后还是不能工作的,使用命令cluster info查看当前集群状态,会发现cluster_state字段还是fail状态。这时往 Redis 写数据的时候也会提示集群未开始正常服务。
127.0.0.1:6380> set hello world
(error) CLUSTERDOWN Hash slot not served
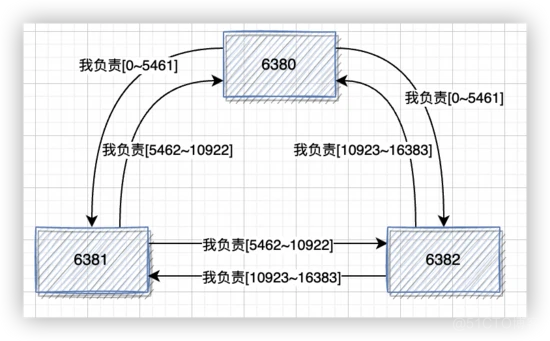
上面提到过,Redis 集群把所有数据映射到 16384 个槽中,通过命令 cluster addslots 命令为节点分配槽:
redis-cli -h 127.0.0.1 -p 6380 cluster addslots {0..5461}
redis-cli -h 127.0.0.1 -p 6381 cluster addslots {5462..10922}
redis-cli -h 127.0.0.1 -p 6382 cluster addslots {10923..16383}节点会在 PING 或者 PONG 消息中带上自己分配的槽信息,这样槽配置信息就会扩散到整个集群中。
Redis 把槽信息保存在数组 myslots 中:
typedef struct {
...
unsigned char myslots[CLUSTER_SLOTS/8];
...
} clusterMsg;CLUSTER_SLOTS 的值为 16384,计算之后得到 myslots 数组的长度为 2048,myslots 等于是一个bitmap,数组的每一位代表一个槽的序号,节点在发送消息的时候会将自己拥有的槽对应的位设置为 1。例如,上面给 6380 节点分配的节点为 0 ~ 5461,那么 myslots 的值会如下设置:

这段代码是 Redis 计算每个槽应该落在 myslots 数组哪一位的函数:
void bitmapSetBit(unsigned char *bitmap, int pos) {
off_t byte = pos/8;
int bit = pos&7;
bitmap[byte] |= 1<<bit;
}通过计算,大家会发现 Redis 在 myslots 中保存值类似小端序的方式。例如,槽 7 经过计算后,byte 为 0,即保存在 myslots[0] 上;bit 为 7 ,即 myslots[0] 的第七位为槽 7。myslots[682] 实际保存的值会是 0x3f,而不是我们以为的 0xfc。
集群中的节点并不需要都分配到槽,只要将槽都分配完成就可以正常工作了。分配完成之后,在执行命令cluster info会看到cluster_state已经是ok了,执行命令 cluster nodes 可以查看当前槽的分配情况:

每个字段的含义如下:

和单例服务一样,切片集群也可以通过分配从库来增加集群的可用性。通过命令cluster replicate <node-id>告诉当前节点与指定主库 id 建立主从关系。
$ redis-cli -p 6383 cluster replicate 1a43101213e2a80cd2eca1468d2b6a3447059a8a
OK
$ redis-cli -p 6384 cluster replicate 1a43101213e2a80cd2eca1468d2b6a3447059a8a
(error) ERR Unknown node 1a43101213e2a80cd2eca1468d2b6a3447059a8a
分配从库有几点需要注意的:
收到建立主从关系的命令时,当前节点会检查本地配置中目标节点是否是同一个集群内的,如果不是一个集群的会返回错误。从库只能挂在主库上,而不能挂在另一个从库上形成级联从库。replicate 命令执行成功后,主从关系会通过 gossip 消息扩散到整个集群。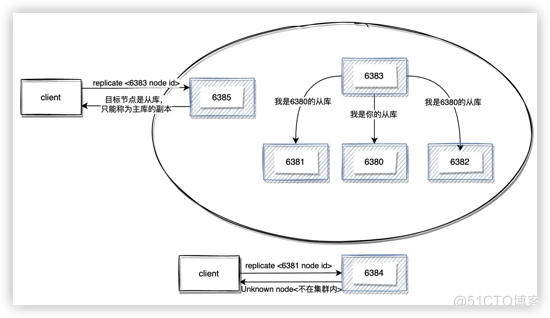
都分配好之后,通过 check 子命令可以检查集群的配置是否正确,槽是否已全部分配:
$ redis-cli --cluster check 127.0.0.1:6380集群通信
127.0.0.1:6380 (1a431012...) -> 1 keys | 5462 slots | 1 slaves.
127.0.0.1:6381 (37b018c0...) -> 0 keys | 5461 slots | 1 slaves.
127.0.0.1:6382 (63f9cd0e...) -> 0 keys | 5461 slots | 1 slaves.
[OK] 1 keys in 3 masters.
0.00 keys per slot on average.
>>> Performing Cluster Check (using node 127.0.0.1:6380)
M: 1a43101213e2a80cd2eca1468d2b6a3447059a8a 127.0.0.1:6380
slots:[0-5461] (5462 slots) master
1 additional replica(s)
M: 37b018c0b4d8c5d9f13a56f6461b3f534de0003a 127.0.0.1:6381
slots:[5462-10922] (5461 slots) master
1 additional replica(s)
S: c0763947801dcf2292b6ce7678a60f84c4f13bc2 127.0.0.1:6385
slots: (0 slots) slave
replicates 63f9cd0ee52af85dad46088a0ed44f66a584f44c
M: 63f9cd0ee52af85dad46088a0ed44f66a584f44c 127.0.0.1:6382
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: 64af469d5d2cab1a0730a865d4ac8bc53444191b 127.0.0.1:6384
slots: (0 slots) slave
replicates 37b018c0b4d8c5d9f13a56f6461b3f534de0003a
S: 8bb20a4da7577c39dbc025e0cdd58e9a51c26164 127.0.0.1:6383
slots: (0 slots) slave
replicates 1a43101213e2a80cd2eca1468d2b6a3447059a8a
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
Redis Cluster 中,每个实例上都会保存槽和实例的对应关系,以及自身的状态信息。Redis Cluster 会通过 gossip 协议,节点间彼此不断通信交换信息,就像流言一样,一段时间后所有的节点都会知道集群的完整信息。
工作原理每个实例有一个定时任务clusterCron,该定时任务会从集群内随机挑一些实例,给它们发送 PING 消息,用来检测这些实例是否在线,并交换彼此的状态信息。挑选实例的逻辑有两个:每过 1 秒随机挑 5 个节点,找出最久没有通信的节点发送 PING 消息;//clusterCron是每100毫秒调用一次,iteration每次调用加1,
//所以等于是每秒选择一个节点发送PING消息
if (!(iteration % 10)) {
int j;
/* Check a few random nodes and ping the one with the oldest
* pong_received time. */
for (j = 0; j < 5; j++) {
de = dictGetRandomKey(server.cluster->nodes);
clusterNode *this = dictGetVal(de);
/* Don't ping nodes disconnected or with a ping currently active. */
if (this->link == NULL || this->ping_sent != 0) continue;
if (this->flags & (CLUSTER_NODE_MYSELF|CLUSTER_NODE_HANDSHAKE))
continue;
if (min_pong_node == NULL || min_pong > this->pong_received) {
min_pong_node = this;
min_pong = this->pong_received;
}
}
if (min_pong_node) {
serverLog(LL_DEBUG,"Pinging node %.40s", min_pong_node->name);
clusterSendPing(min_pong_node->link, CLUSTERMSG_TYPE_PING);
}
}
2. 找出最后一次通信时间大于 `cluster_node_timeout / 2` 的节点;
//每次收到实例收到 PING 消息后,会回复一个 PONG 消息。PING 和 PONG 消息中都包含实例自身的状态信息、1/10 其它实例的状态信息(至少3个)以及槽的映射信息。通信开销
if (node->link &&
node->ping_sent == 0 &&
(now - node->pong_received) > server.cluster_node_timeout/2)
{
clusterSendPing(node->link, CLUSTERMSG_TYPE_PING);
continue;
}
gossip 消息体的定义如下:
typedef struct {
char nodename[CLUSTER_NAMELEN]; //40字节
uint32_t ping_sent; //4字节
uint32_t pong_received; //4字节
char ip[NET_IP_STR_LEN]; //46字节
uint16_t port; //2字节
uint16_t cport; //2字节
uint16_t flags; //2字节
uint32_t notused1; //4字节
} clusterMsgDataGossip;可以看到一个消息体的大小为 104 个字节。每次发送消息时还会带上 1 / 10 的节点信息,如果按照官方限制的集群最大节点数 1000 来计算,每次发送的消息体大小为 10400 个字节。clusterCron 是每 100 毫秒执行一次,每个实例每秒发出的消息为 104000 个字节。定时任务中还会给超时未通信的节点发送 PING 消息,假设每次定时任务有 10 个节点超时,那么每个节点每秒总的消息大小为 1M 多。当集群节点数较多时,通信开销还是很大的。
为了减少通信开销,我们可以做如下操作:
需要避免过大的集群,必要时可以将一个集群根据业务拆分成多个集群。适当调整 cluster_node_timeout 的值,减少每次定时需要发送的消息数。故障转移故障发现Redis Cluster 也通过主观下线(pfail)和客观下线(fail)来识别集群中的节点是否发生故障。集群中每个节点定时通过 PING、PONG 来检查集群中其它节点和自己的通讯状态。当目标节点和自己在超过cluster-node-timeout时间内未成功通信,那么当前节点会将该节点状态标记为主观下线。相关代码在clusterCron函数中:
mstime_t node_delay = (ping_delay < data_delay) ? ping_delay :
data_delay;
if (node_delay > server.cluster_node_timeout) {
/* Timeout reached. Set the node as possibly failing if it is
* not already in this state. */
if (!(node->flags & (CLUSTER_NODE_PFAIL|CLUSTER_NODE_FAIL))) {
serverLog(LL_DEBUG,"*** NODE %.40s possibly failing",
node->name);
//将目标节点状态标记为pfail
node->flags |= CLUSTER_NODE_PFAIL;
update_state = 1;
}
}
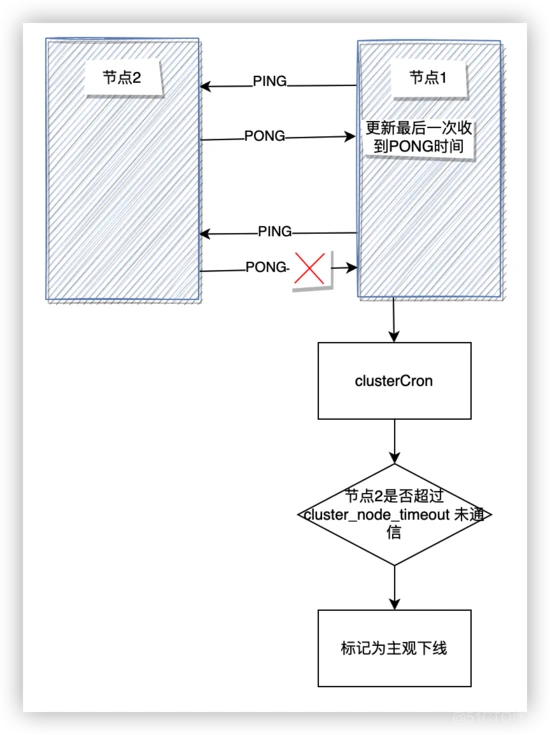
每个节点通过结构clusterNode来保存集群节点信息,该结构中的fail_reports字段记录了其它报告该节点主观下线的节点,flags字段维护目标节点的状态。
typedef struct clusterNode {
...
int flags; //记录节点当前状态
...
list *fail_reports; //记录主观下线的节点
} clusterNode;Redis Cluster 处理主观下线→客观下线的流程如下:
cluster_node_timeout * 2
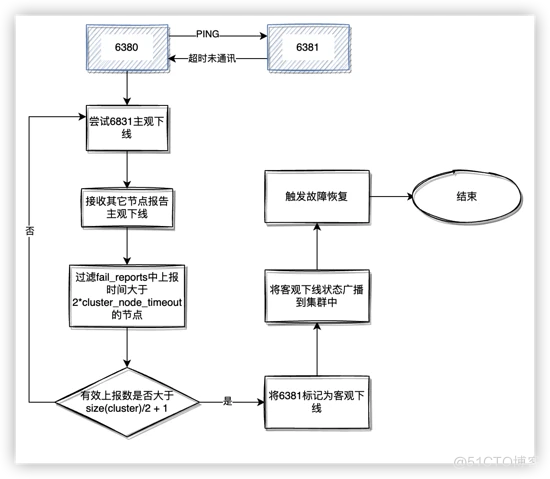
故障节点变为客观下线后,如果下线节点是持有槽的主节点,那么它的从节点就会参与竞选主节点,承担故障恢复的义务。在定时任务clusterCron中会调用clusterHandleSlaveFailover来检测到主节点的状态是否是客观下线,如果是客观下线就会尝试故障恢复。
cluster-replica-no-failover配置为 true 的时候,该节点会只作为从节点存在,失去竞选主节点的机会。过滤与主节点断线时间过大的。首先会获取时间基准,有两种情况:当从节点的副本状态(repl_state)还是连接状态(REPL_STATE_CONNECTED),会使用和主节点的最后通讯时间;否则,从节点会使用断线时间。获取时间基准后,会用当前时间减去时间基准,如果结果大于cluster_node_timeout,会将结果减去cluster_node_timeout(等于是从节点判断主节点主观下线后的时间开始计算?)最终得到data_age。最后将data_age和cluster-slave-validity-factor*cluster_node_timeout+repl_ping_slave_period比较,如果较大,则会失去竞选主节点的机会。当cluster-slave-validity-factor设置为 0 的时候,会直接进行下一步。选举准备选举时间。从节点通过筛选之后不会立刻发起选举,而是会先确定一个选举的开始时间。 这主要是为了让主从副本进度最接近原主节点的从节点优先发起选举,以及让原主节点的Fail状态有足够的时间在集群内传播。选举时间会有一个固定的基准时间(
failover_auth_time = mstime()+500+random()%500),然后从节点根据主节点下所有从节点的副本进度决定排名(fail_over_rank),根据排名决定选举延迟时间(failover_auth_time += fail_over_rank * 1000)。同时,副本进度会通过广播发送给所有相同主节点下的从节点,让它们更新排名。发送选举请求。当选举时间到了之后,当前节点将集群的配置纪元(clusterState.currentEpoch)加 1,然后再集群内广播选举消息(消息类型为CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST)。集群内的节点收到拉票消息后,会进行以下判断:lastVoteEpoch
cluster_node_timeout * 2
当以上检查都通过的时候,当前节点会有一下几个操作:
lastVoteEpoch替换主节点。从节点收到应答后,会将
sender→slaveof→voted_time
clusterSendFailorAuth
failover_auth_count加 1,当该值大于集群中持有槽的主节点数的一半时(failover_auth_count > cluster→size / 2 + 1),会开始替换主节点流程(clusterFailoverReplaceYourMaster):首先会将自己提升为主节点,然后停止向原主节点的副本同步操作。将原主节点持有的槽转交给自己负责。更新集群状态信息。广播消息,通知集群内其它节点自己当选为新的主节点。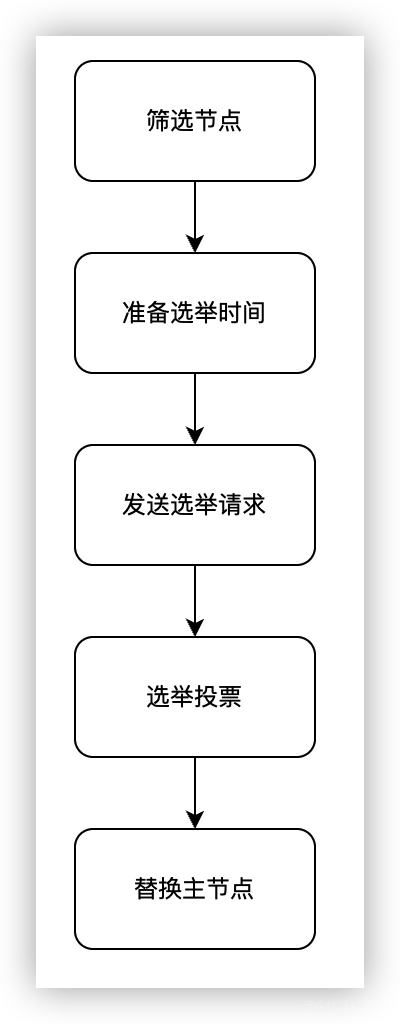
准备一个简单的 Redis Cluster,可以使用快速搭建集群中提到的方法搭建一个集群。这时候会得到一个 3 主库,3 从库的集群。使用命令ps -ef | grep redis-server来查看实例是否都已经运行:

然后使用命令redis-cli -p 30001 cluster nodes查看集群内主从节点的分配和槽的分配:

模拟节点下线可以使用命令 kill 来实现,这里让节点 30001 下线,上面使用 ps 命令看到 30001 的进程id 为 2102672,使用命令kill -9 2102672杀死 30001 进程。这时用redis-cli -p 30002 cluster nodes命令查看集群节点信息:

我们可以看到 30001节点的状态为客观离线(fail),30001 原来的从节点 30006 通过选举成为了新的主节点。我们可以看下 30006 的日志,看看这个过程,vim 30006.log:
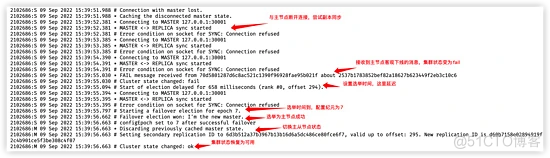
选举时间延迟 658 毫秒,计算方式在选举的第一点有提到过。
然后我们选择一个主节点和一个从节点的日志文件查看是否有参加投票,主节点选择 30002,可以看到日志中有将票投给 30006 节点(日志中打印的是 30006 的 runId):

从节点选择 30005,看到从节点并没有参加投票:

Redis 的源码和文档真的非常有观赏性。源码里的注释十分丰富,逻辑看不懂的时候看下注释基本能明白代码的作用。文档是我接触过的开源项目里写的最好的。希望能坚持下来,从 Redis 里学到更多更好的代码设计思想。






.png)

.png)

