 云计算服务
云计算服务
 服务器租用
服务器租用
 DDOS 防护
DDOS 防护
 虚拟主机
虚拟主机
 域名服务
域名服务
 基础设施
基础设施
 关于我们
关于我们
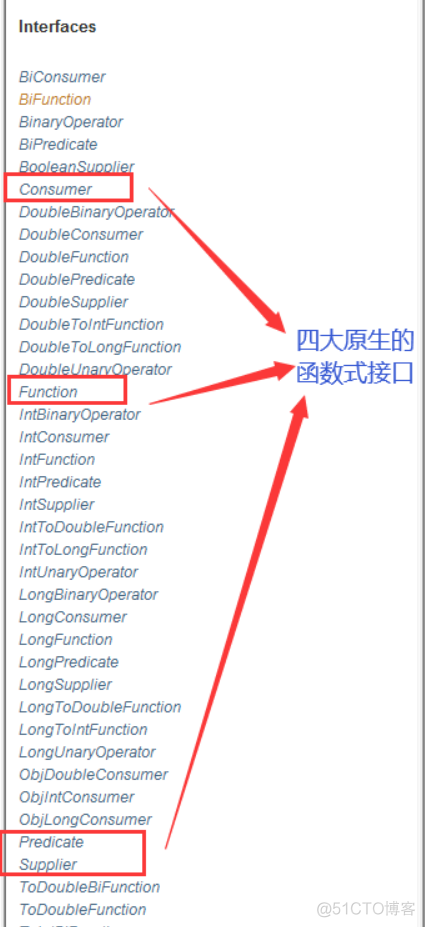
12. 四大函数式接口
新时代的程序员:lambda表达式、链式编程、函数式接口、Stream流式计算
函数式接口:只有一个方法的接口

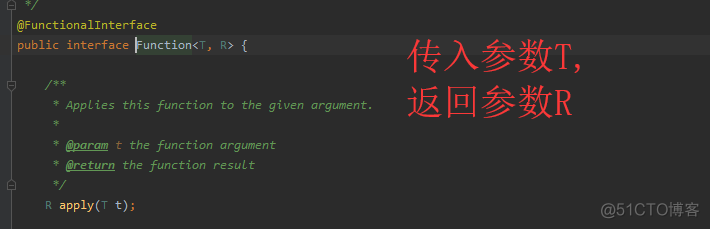
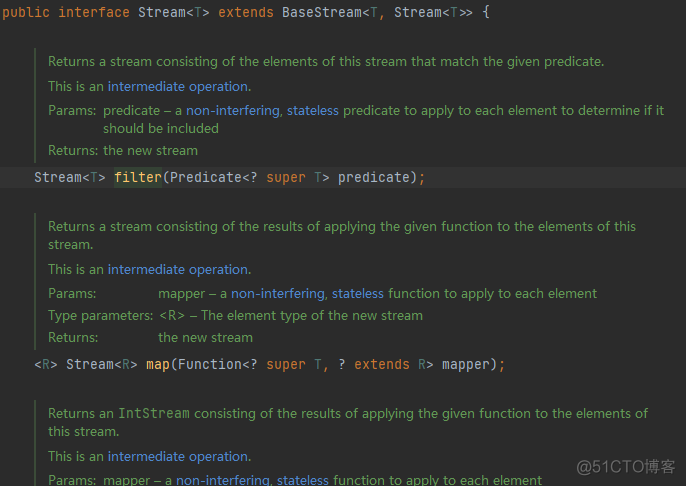
1)Function 函数型接口
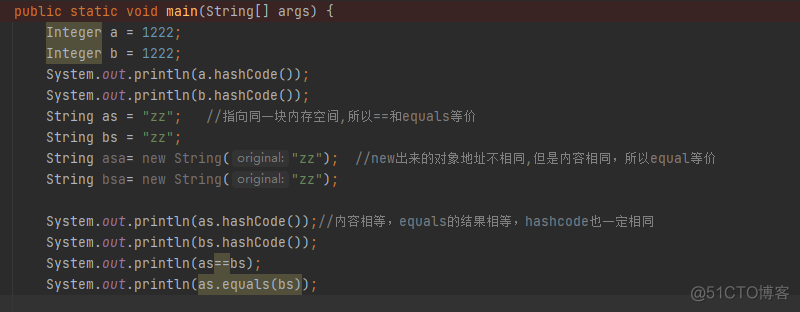
public class FunctionDemo {
public static void main(String[] args) {
Function<String, String> function = (str) -> {return str;};
System.out.println(function.apply("aaaaaaaaaa"));
}
}2)Predicate 断定型接口

public class PredicateDemo {
public static void main(String[] args) {
Predicate<String> predicate = (str) -> {return str.isEmpty();};
// false
System.out.println(predicate.test("aaa"));
// true
System.out.println(predicate.test(""));
}
}3)Suppier 供给型接口

/**4)Consummer 消费型接口
* 供给型接口,只返回,不输入
*/
public class Demo4 {
public static void main(String[] args) {
Supplier<String> supplier = ()->{return "1024";};
System.out.println(supplier.get());
}
}

/**13. Stream 流式计算
* 消费型接口 没有返回值!只有输入!
*/
public class Demo3 {
public static void main(String[] args) {
Consumer<String> consumer = (str)->{
System.out.println(str);
};
consumer.accept("abc");
}
}
流式编程代码更简洁
/**14. ForkJoin
* Description:
* 题目要求: 用一行代码实现
* 1. Id 必须是偶数
* 2.年龄必须大于23
* 3. 用户名转为大写
* 4. 用户名倒序
* 5. 只能输出一个用户
*
* @author jiaoqianjin
* Date: 2020/8/12 14:55
**/
public class StreamDemo {
public static void main(String[] args) {
User u1 = new User(1, "a", 23);
User u2 = new User(2, "b", 23);
User u3 = new User(3, "c", 23);
User u4 = new User(6, "d", 24);
User u5 = new User(4, "e", 25);
List<User> list = Arrays.asList(u1, u2, u3, u4, u5);
// lambda、链式编程、函数式接口、流式计算
list.stream() //使用四大函数式接口在一个流里面完成一行代码满足要求。
.filter(user -> {return user.getId()%2 == 0;})
.filter(user -> {return user.getAge() > 23;})
.map(user -> {return user.getName().toUpperCase();})
.sorted((user1, user2) -> {return user2.compareTo(user1);})
.limit(1)
.forEach(System.out::println);
}
}
ForkJoin 在JDK1.7,并行执行任务!提高效率~。在大数据量速率会更快!
大数据中:MapReduce 核心思想->把大任务拆分为小任务!
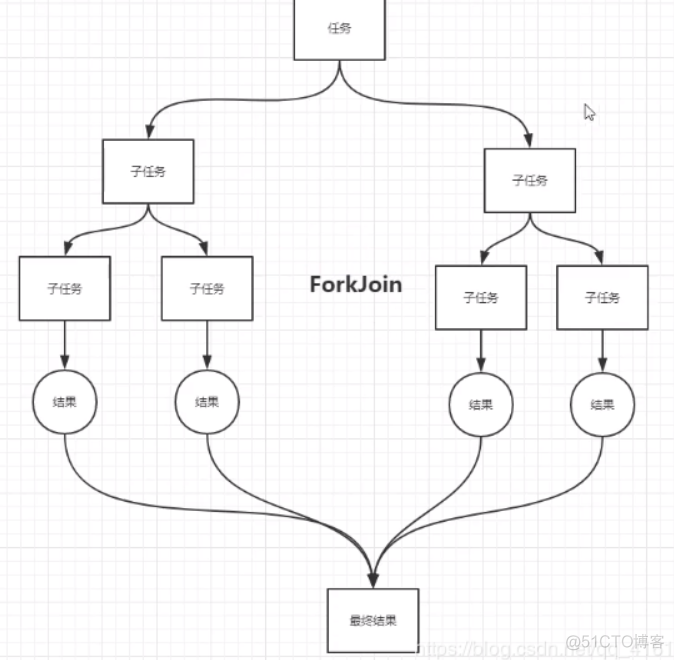
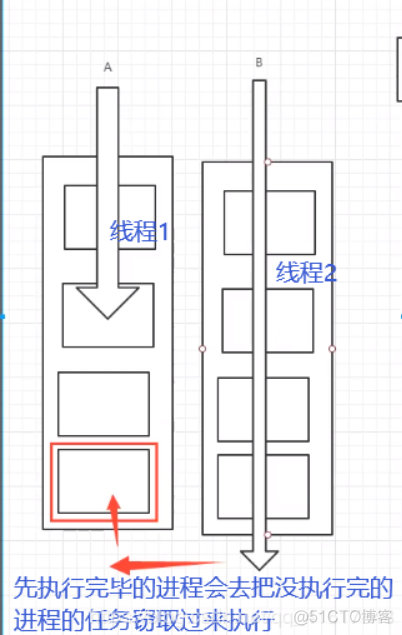
实现原理是:双端队列!从上面和下面都可以去拿到任务进行执行!
ForkJoin 的计算类
package com.marchsoft.forkjoin;
import java.util.concurrent.RecursiveTask;
/**
* Description:
*
* @author jiaoqianjin
* Date: 2020/8/13 8:33
**/
public class ForkJoinDemo extends RecursiveTask<Long> {
private long star;
private long end;
/** 临界值 */
private long temp = 1000000L;
public ForkJoinDemo(long star, long end) {
this.star = star;
this.end = end;
}
/**
* 计算方法
* @return
*/
@Override
protected Long compute() {
if ((end - star) < temp) {
Long sum = 0L;
for (Long i = star; i < end; i++) {
sum += i;
}
return sum;
}else {
// 使用ForkJoin 分而治之 计算
//1 . 计算平均值
long middle = (star + end) / 2;
ForkJoinDemo forkJoinDemo1 = new ForkJoinDemo(star, middle);
// 拆分任务,把线程压入线程队列
forkJoinDemo1.fork();
ForkJoinDemo forkJoinDemo2 = new ForkJoinDemo(middle, end);
forkJoinDemo2.fork();
long taskSum = forkJoinDemo1.join() + forkJoinDemo2.join();
return taskSum;
}
}
}
测试类
package com.marchsoft.forkjoin;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask;
import java.util.stream.LongStream;
/**
* Description:
*
* @author jiaoqianjin
* Date: 2020/8/13 8:43
**/
public class ForkJoinTest {
private static final long SUM = 20_0000_0000;
public static void main(String[] args) throws ExecutionException, InterruptedException {
test1();
test2();
test3();
}
/**
* 使用普通方法
*/
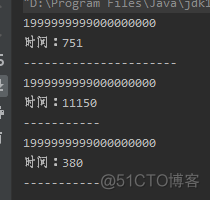
public static void test1() {
long star = System.currentTimeMillis();
long sum = 0L;
for (long i = 1; i < SUM ; i++) {
sum += i;
}
long end = System.currentTimeMillis();
System.out.println(sum);
System.out.println("时间:" + (end - star));
System.out.println("----------------------");
}
/**
* 使用ForkJoin 方法
*/
public static void test2() throws ExecutionException, InterruptedException {
long star = System.currentTimeMillis();
ForkJoinPool forkJoinPool = new ForkJoinPool();
ForkJoinTask<Long> task = new ForkJoinDemo(0L, SUM);
ForkJoinTask<Long> submit = forkJoinPool.submit(task);
Long along = submit.get();
System.out.println(along);
long end = System.currentTimeMillis();
System.out.println("时间:" + (end - star));
System.out.println("-----------");
}
/**
* 使用 Stream 流计算
*/
public static void test3() {
long star = System.currentTimeMillis();
long sum = LongStream.range(0L, 20_0000_0000L).parallel().reduce(0, Long::sum);
System.out.println(sum);
long end = System.currentTimeMillis();
System.out.println("时间:" + (end - star));
System.out.println("-----------");
}
}
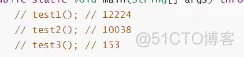
.parallel().reduce(0, Long::sum)使用一个并行流去计算整个计算,提高效率。
Future 设计的初衷:对将来的某个事件结果进行建模!
其实就是前端 --> 发送ajax异步请求给后端
但是我们平时都使用CompletableFuture
(1)没有返回值的runAsync异步回调public static void main(String[] args) throws ExecutionException, InterruptedException(2)有返回值的异步回调supplyAsync
{
// 发起 一个 请求
System.out.println(System.currentTimeMillis());
System.out.println("---------------------");
CompletableFuture<Void> future = CompletableFuture.runAsync(()->{
//发起一个异步任务
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+".....");
});
System.out.println(System.currentTimeMillis());
System.out.println("------------------------------");
//输出执行结果
System.out.println(future.get()); //获取执行结果
//有返回值的异步回调
CompletableFuture<Integer> completableFuture=CompletableFuture.supplyAsync(()->{
System.out.println(Thread.currentThread().getName());
try {
TimeUnit.SECONDS.sleep(2);
int i=1/0;
} catch (InterruptedException e) {
e.printStackTrace();
}
return 1024;
});
System.out.println(completableFuture.whenComplete((t, u) -> {
//success 回调
System.out.println("t=>" + t); //正常的返回结果
System.out.println("u=>" + u); //抛出异常的 错误信息
}).exceptionally((e) -> {
//error回调
System.out.println(e.getMessage());
return 404;
}).get());
whenComplete: 有两个参数,一个是t 一个是u
T:是代表的 正常返回的结果;
U:是代表的 抛出异常的错误信息;
如果发生了异常,get可以获取到exceptionally返回的值;
16. JMM1)对Volatile 的理解
Volatile 是 Java 虚拟机提供 轻量级的同步机制
1、保证可见性
2、不保证原子性
3、禁止指令重排
如何实现可见性
volatile变量修饰的共享变量在进行写操作的时候回多出一行汇编:
0x01a3de1d:movb $0×0,0×1104800(%esi);0x01a3de24**:lock** addl $0×0,(%esp);
Lock前缀的指令在多核处理器下会引发两件事情。
1)将当前处理器缓存行的数据写回到系统内存。
2)这个写回内存的操作会使其他cpu里缓存了该内存地址的数据无效。
多处理器总线嗅探:
为了提高处理速度,处理器不直接和内存进行通信,而是先将系统内存的数据读到内部缓存后再进行操作,但操作不知道何时会写到内存。如果对声明了volatile的变量进行写操作,JVM就会向处理器发送一条lock前缀的指令,将这个变量所在缓存行的数据写回到系统内存。但是在多处理器下,为了保证各个处理器的缓存是一致的,就会实现缓存缓存一致性协议,每个处理器通过嗅探在总线上传播的数据来检查自己的缓存值是不是过期了,如果处理器发现自己缓存行对应的内存地址呗修改,就会将当前处理器的缓存行设置无效状态,当处理器对这个数据进行修改操作的时候,会重新从系统内存中把数据库读到处理器缓存中。
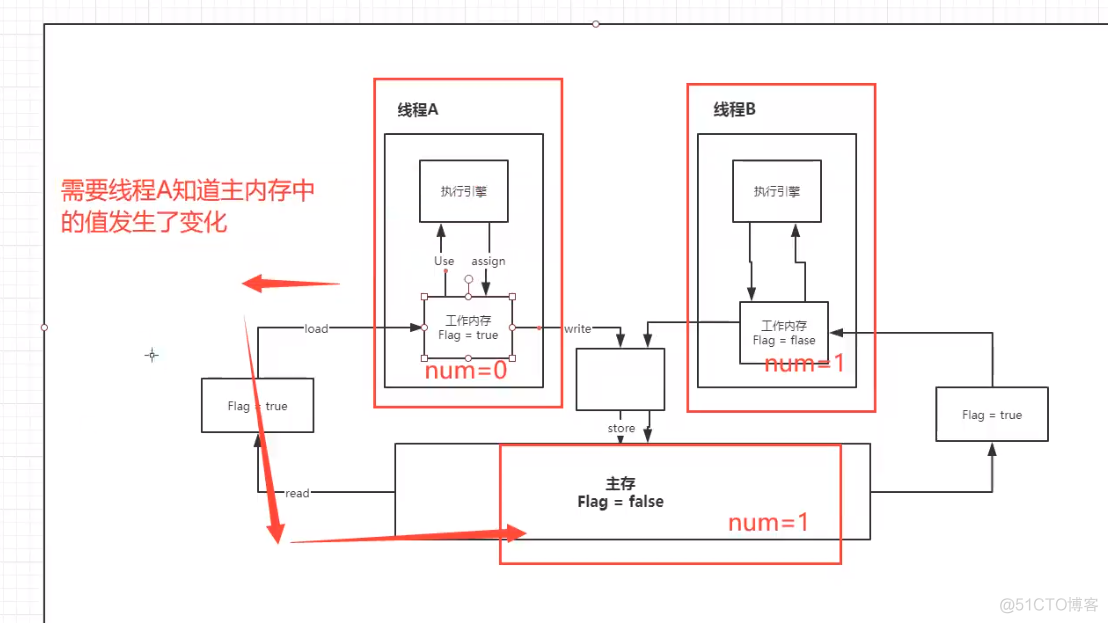
2)什么是JMM?
JMM:JAVA内存模型,不存在的东西,是一个概念,也是一个约定!
关于JMM的一些同步的约定:
1、线程解锁前,必须把共享变量立刻刷回主存;
2、线程加锁前,必须读取主存中的最新值到工作内存中;
3、加锁和解锁是同一把锁;
线程中分为 工作内存、主内存
8种操作:
Read(读取):作用于主内存变量,它把一个变量的值从主内存传输到线程的工作内存中,以便随后的load动作使用;
load(载入):作用于工作内存的变量,它把read操作从主存中变量放入工作内存中;
Use(使用):作用于工作内存中的变量,它把工作内存中的变量传输给执行引擎,每当虚拟机遇到一个需要使用到变量的值,就会使用到这个指令;
assign(赋值):作用于工作内存中的变量,它把一个从执行引擎中接受到的值放入工作内存的变量副本中;
store(存储):作用于主内存中的变量,它把一个从工作内存中一个变量的值传送到主内存中,以便后续的write使用;
write(写入):作用于主内存中的变量,它把store操作从工作内存中得到的变量的值放入主内存的变量中;
lock(锁定):作用于主内存的变量,把一个变量标识为线程独占状态;
unlock(解锁):作用于主内存的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定;
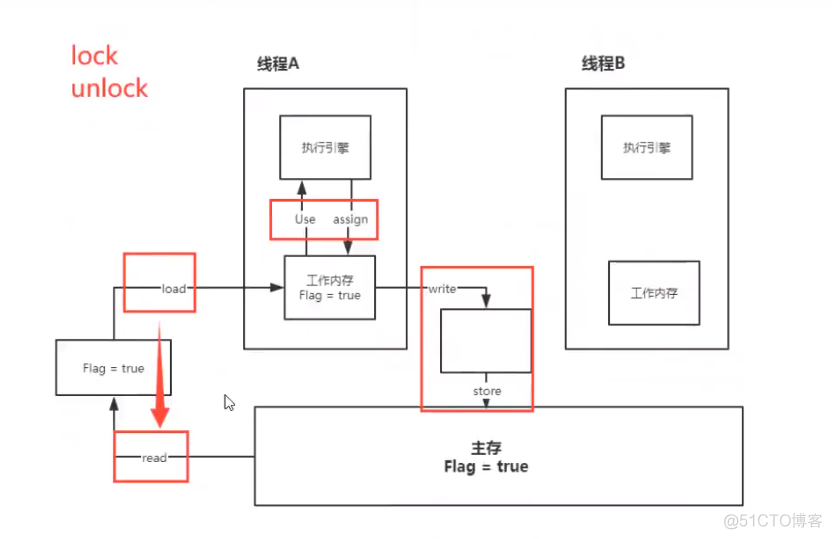
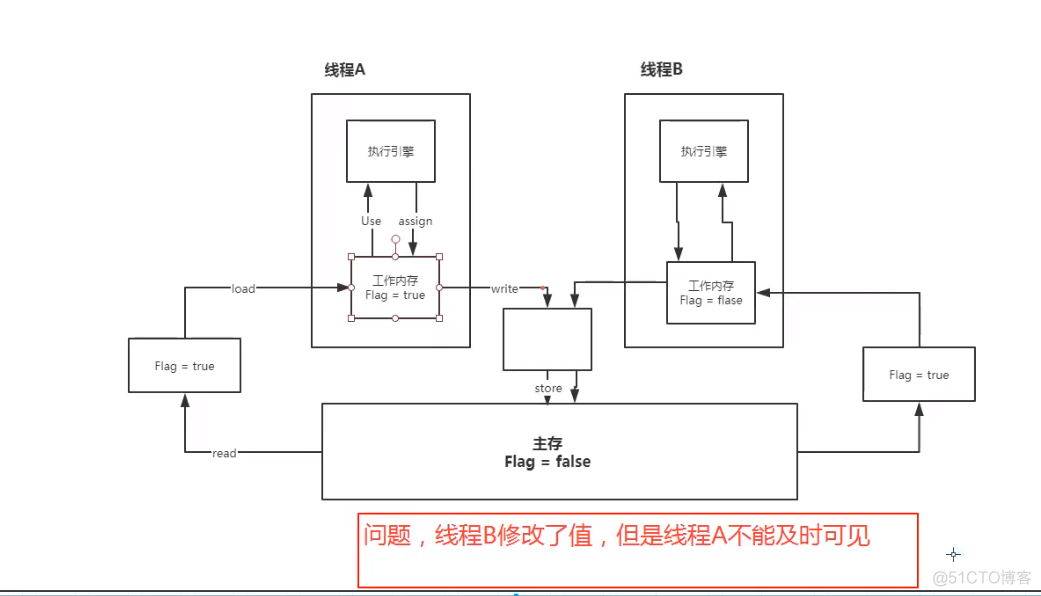
JMM对这8种操作给了相应的规定:
不允许read和load、store和write操作之一单独出现。即使用了read必须load,使用了store必须write
不允许线程丢弃他最近的assign操作,即工作变量的数据改变了之后,必须告知主存
不允许一个线程将没有assign的数据从工作内存同步回主内存
一个新的变量必须在主内存中诞生,不允许工作内存直接使用一个未被初始化的变量。就是对变量实施use、store操作之前,必须经过assign和load操作
一个变量同一时间只有一个线程能对其进行lock。多次lock后,必须执行相同次数的unlock才能解锁
如果对一个变量进行lock操作,会清空所有工作内存中此变量的值,在执行引擎使用这个变量前,必须重新load或assign操作初始化变量的值
如果一个变量没有被lock,就不能对其进行unlock操作。也不能unlock一个被其他线程锁住的变量
对一个变量进行unlock操作之前,必须把此变量同步回主内存
public class JMMDemo01 {
// 如果不加volatile 程序会死循环
// 加了volatile是可以保证可见性的
private volatile static Integer number = 0;
public static void main(String[] args) {
//main线程
//子线程1
new Thread(()->{
while (number==0){
}
}).start();
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
//子线程2
new Thread(()->{
while (number==0){
}
}).start();
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
number=1;
System.out.println(number);
}
}2)不保证原子性原子性:不可分割;
线程A在执行任务的时候,不能被打扰的,也不能被分割的,要么同时成功,要么同时失败。
/**
* 不保证原子性
* number <=2w
*
*/
public class VDemo02 {
private static volatile int number = 0;
public static void add(){
number++;
//++ 不是一个原子性操作,是两个~3个操作
//
}
public static void main(String[] args) {
//理论上number === 20000
for (int i = 1; i <= 20; i++) {
new Thread(()->{
for (int j = 1; j <= 1000 ; j++) {
add();
}
}).start();
}
while (Thread.activeCount()>2){
//main gc
Thread.yield();
}
System.out.println(Thread.currentThread().getName()+",num="+number);
}
}
使用原子类
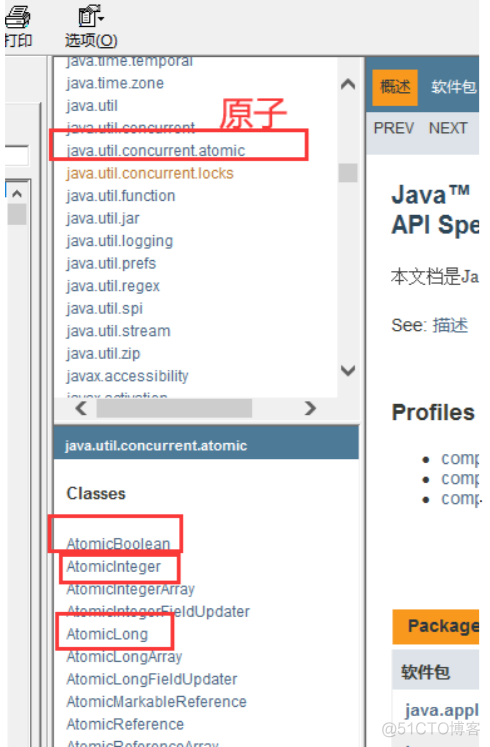
public class VDemo02 {
private static volatile AtomicInteger number = new AtomicInteger();
public static void add(){
// number++;
number.incrementAndGet(); //底层是CAS保证的原子性
}
public static void main(String[] args) {
//理论上number === 20000
for (int i = 1; i <= 20; i++) {
new Thread(()->{
for (int j = 1; j <= 1000 ; j++) {
add();
}
}).start();
}
while (Thread.activeCount()>2){
//main gc
Thread.yield();
}
System.out.println(Thread.currentThread().getName()+",num="+number);
}
}这些类的底层都直接和操作系统挂钩!是在内存中修改值。
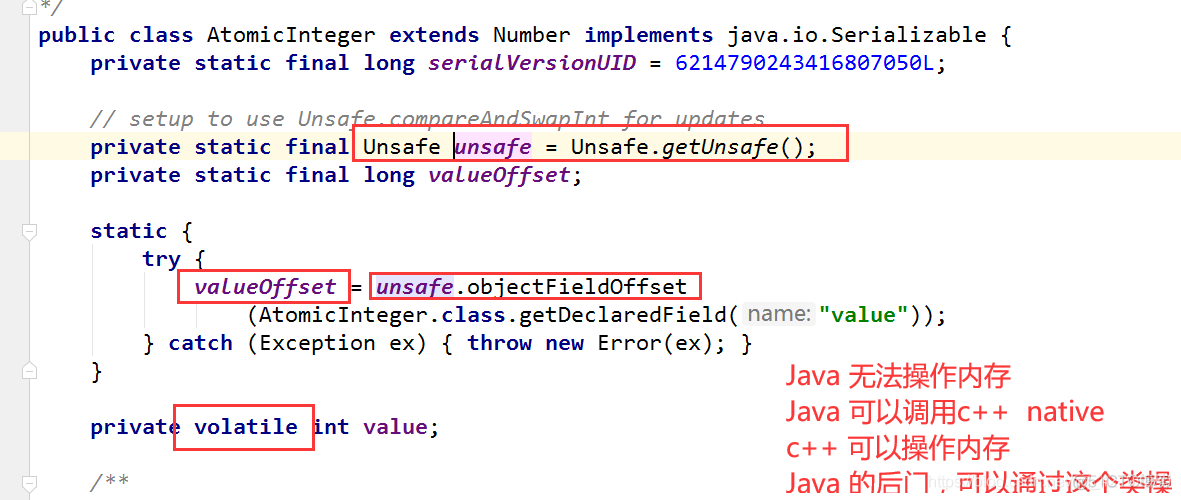
Unsafe类是一个很特殊的存在;
原子类为什么这么高级?
3)禁止指令重排
什么是指令重排?
我们写的程序,计算机并不是按照我们自己写的那样去执行的
源代码–>编译器优化重排–>指令并行也可能会重排–>内存系统也会重排–>执行
处理器在进行指令重排的时候,会考虑数据之间的依赖性!
int x=1; //1
int y=2; //2
x=x+5; //3
y=x*x; //4
//我们期望的执行顺序是 1_2_3_4 可能执行的顺序会变成2134 1324
//可不可能是 4123? 不可能的
可能造成的影响结果:前提:a b x y这四个值 默认都是0
线程A 线程B
x=a y=b
b=1 a=2
正常的结果: x = 0; y =0;
线程A 线程B
b=1 a=2
x=a y=b
可能在线程A中会出现,先执行b=1,然后再执行x=a;
在B线程中可能会出现,先执行a=2,然后执行y=b;
那么就有可能结果如下:x=2; y=1.
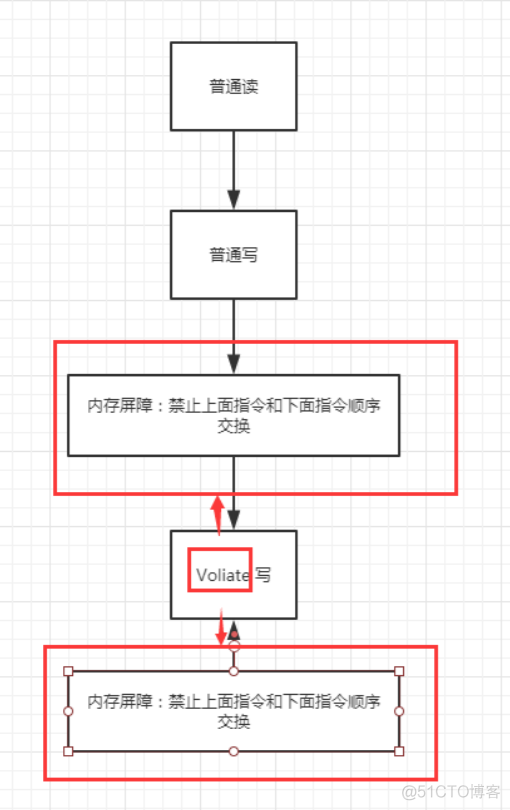
volatile可以避免指令重排:
volatile中会加一道内存的屏障,这个内存屏障可以保证在这个屏障中的指令顺序。
内存屏障:CPU指令。作用:
1、保证特定的操作的执行顺序;
2、可以保证某些变量的内存可见性(利用这些特性,就可以保证volatile实现的可见性)
面试官:那么你知道在哪里用这个内存屏障用得最多呢?单例模式
单例模式_反射破坏单例模式_枚举类_枚举类实现单例_枚举类解决单例模式破坏
理解CAS什么是CAS :
CAS 是 Compare And Swap的简称,从字面上理解就是比较并更新,简单来说:从某一内存上取值V,和预期值A进行比较,如果内存值V和预期值A的结果相等,那么我们就把新值B更新到内存,如果不相等,那么就重复上述操作直到成功为止。
在 Java的原子类中,有对cas的封装进行应用:此处用AtomicInteger举例
public class CAS_Demo {
public static void main(String[] args) {
AtomicInteger atomicInteger = new AtomicInteger(2020);
//CAS的封装体现:compareAndSet 比较并赋值
//比较当前值是否为2020? set 2021,return true : do nothing,return false
System.out.println(atomicInteger.compareAndSet(2020, 2021));//true
System.out.println(atomicInteger.get());//此时为2021
//获取值并自增
atomicInteger.getAndIncrement();//自增后为 2022
System.out.println(atomicInteger.compareAndSet(2021, 2033));//false
System.out.println(atomicInteger.get());// 2022
}
}点击查看AtomicInteger的源码:
直接通过Unsafe类调用底层 CAS方法
//compareAndSet
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
//getAndIncrement
public final int getAndIncrement() {
return unsafe.getAndAddInt(this, valueOffset, 1);
}
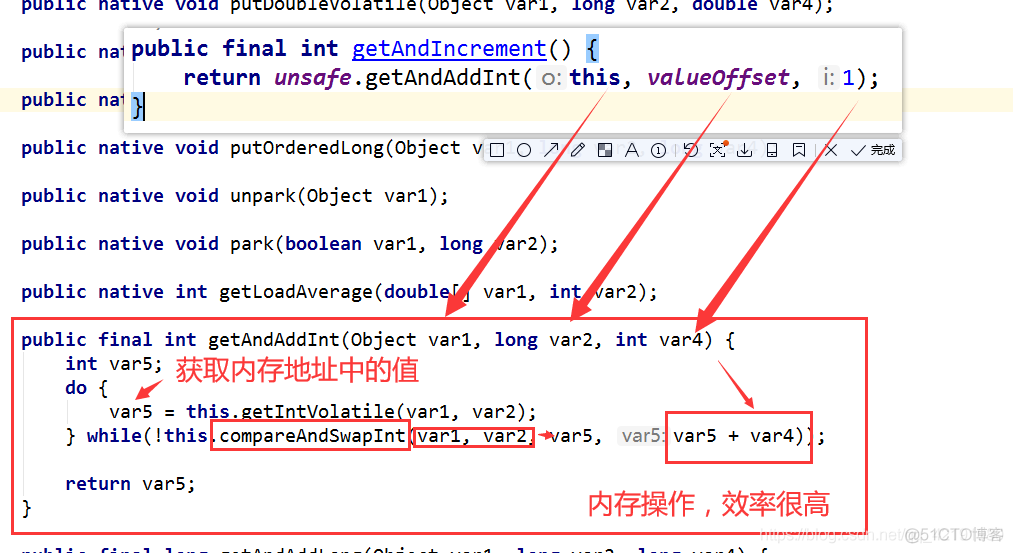
getAndAddInt方法详解:
通过一定的轮询,也就是后面介绍的自旋锁:

关于自增getAndIncrement()方法使用自旋锁实现安全

//AtomicInteger类
//变量value; 相当于i++中的i
private volatile int value;
//创建Unsafe类的实例
private static final Unsafe unsafe = Unsafe.getUnsafe();
//变量value的偏移量, 具体赋值是在下面的静态代码块中中进行的
private static final long valueOffset;
//在静态代码块中获取变量value的偏移量
static {
try {
//获取value变量的偏移量, 赋值给valueOffset
valueOffset = unsafe.objectFieldOffset(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
//执行value++操作
public final int getAndIncrement() {
//this是当前对象, valueOffset是
return unsafe.getAndAddInt(this, valueOffset, 1);
}
CAS的具体实现在Unsafe类的getAndAddInt()方法有体现, 代码如下
//Unsafe类
//获取内存地址为obj+offset的变量值, 并将该变量值加上delta
public final int getAndAddInt(Object obj, long offset, int delta) {
int v;
do {
//通过对象和偏移量获取变量的值
//由于volatile的修饰, 所有线程看到的v都是一样的
v= this.getIntVolatile(obj, offset);
/*
while中的compareAndSwapInt()方法尝试修改v的值,具体地, 该方法也会通过obj和offset获取变量的值
如果这个值和v不一样, 说明其他线程修改了obj+offset地址处的值, 此时compareAndSwapInt()返回false, 继续循环
如果这个值和v一样, 说明没有其他线程修改obj+offset地址处的值, 此时可以将obj+offset地址处的值改为v+delta, compareAndSwapInt()返回true, 退出循环
Unsafe类中的compareAndSwapInt()方法是原子操作, 所以compareAndSwapInt()修改obj+offset地址处的值的时候不会被其他线程中断
*/
} while(!this.compareAndSwapInt(obj, offset, v, v + delta));
return v;
}
自旋锁其实就是判断有没有其他线程修改地址变量,修改了则预期值和实际值就不相等,没有的话相等就自己才去修改。一定注意自旋锁除了循环不断去判断之外,最核心的就是unsafe的比较并替换方法是原子方法,来保证整体的原子性。
首先通过volatile的可见性,取出当前地址中的值,作为期望值。如果期望值与实际值不符,就一直循环获取期望值,直到set成功。
适用场景:
1. CAS 适合简单对象的操作,比如布尔值、整型值等;
2. CAS 适合冲突较少的情况,如果太多线程在同时自旋,那么长时间循环会导致 CPU 开销很大;
CAS的缺点:
1. CPU开销过大 : 在并发量比较高的情况下,如果许多线程反复尝试更新某一个变量,却又一直更新不成功,循环往复,会给CPU带来很到的压力。
2. 不能保证代码块的原子性:CAS机制所保证的知识一个变量的原子性操作,而不能保证整个代码块的原子性。比如需要保证3个变量共同进行原子性的更新,就不得不使用synchronized了。
3.ABA问题:如果内存地址V初次读取的值是A,在CAS等待期间它的值曾经被改成了B,后来又被改回为A,那CAS操作就会误认为它从来没有被改变过。
ABA问题以及解决
CAS锁其又称作Java的乐观锁,但是我们可以看到其实质上是没有上????的,只是赋值的过程前多了一个比较的方法,因此可能引起一定的ABA问题:
[狸猫换太子] 如果另一个线程修改V值假设原来是A,先修改成B,再修改回成A。当前线程的CAS操作无法分辨当前V值是否发生过变化。
举个栗子:
在你非常渴的情况下你发现一个盛满水的杯子,你一饮而尽。之后再给杯子里重新倒满水。然后你离开,当杯子的真正主人回来时看到杯子还是盛满水,他当然不知道是否被人喝完重新倒满。
public class CAS_Demo {
public static void main(String[] args) {
AtomicInteger atomicInteger = new AtomicInteger(2020);
// 我们想把数字改成6666
// ============== 捣乱的线程 ==================
atomicInteger.compareAndSet(2020, 2021);
System.out.println("such a fool...");
atomicInteger.compareAndSet(2021, 2020);
// ============== 期望的线程 ==================
System.out.println(atomicInteger.compareAndSet(2020, 6666));
System.out.println(atomicInteger.get());
}
}解决上述问题的一个策略是:
每一次倒水假设有一个自动记录仪记录下,也就是给操作赋值上一个标致,这样主人回来就可以分辨在他离开后是否发生过重新倒满的情况。
这也是解决ABA问题目前采用的策略,这就需要我们的原子引用
20. 原子引用官方说明:
一个AtomicStampedReference维护对象引用以及整数“印记”,可以原子更新。
实现注意事项:此实现通过创建表示“boxed”[引用,整数]对的内部对象来维护加盖引用
举个例子:
这里用到了双参构造方法:(一个初始值,一个时间戳)
public AtomicStampedReference(V initialRef, int initialStamp) {
pair = Pair.of(initialRef, initialStamp);
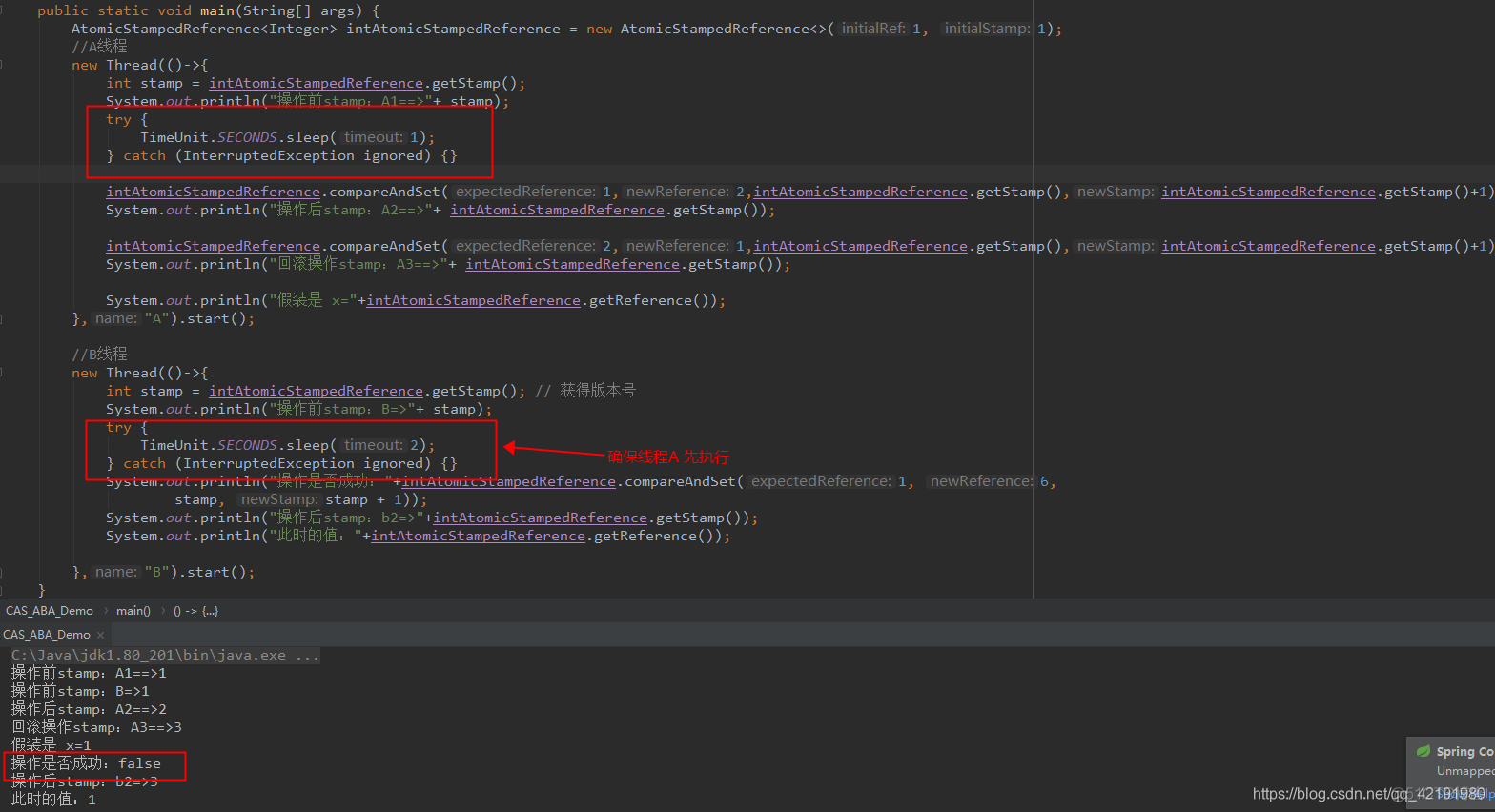
}public class CAS_ABA_Demo {
public static void main(String[] args) {
AtomicStampedReference<Integer> intAtomicStampedReference = new AtomicStampedReference<>(1, 1);
//A线程
new Thread(()->{
System.out.println("操作前stamp:A1==>"+ intAtomicStampedReference.getStamp());
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException ignored) {}
intAtomicStampedReference.compareAndSet(1,2,intAtomicStampedReference.getStamp(),intAtomicStampedReference.getStamp()+1);
System.out.println("操作后stamp:A2==>"+ intAtomicStampedReference.getStamp());
intAtomicStampedReference.compareAndSet(2,1,intAtomicStampedReference.getStamp(),intAtomicStampedReference.getStamp()+1);
System.out.println("回滚操作stamp:A3==>"+ intAtomicStampedReference.getStamp());
System.out.println("假装是 x="+intAtomicStampedReference.getReference());
},"A").start();
//B线程
new Thread(()->{
int stamp = intAtomicStampedReference.getStamp(); // 获得版本号
System.out.println("操作前stamp:B=>"+ stamp);
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException ignored) {}
System.out.println("操作是否成功:"+intAtomicStampedReference.compareAndSet(1, 6,
stamp, stamp + 1));
System.out.println("操作后stamp:b2=>"+intAtomicStampedReference.getStamp());
System.out.println("此时的值:"+intAtomicStampedReference.getReference());
},"B").start();
}
}还是IDEA香啊,代码写完后还会有赋值的提醒????
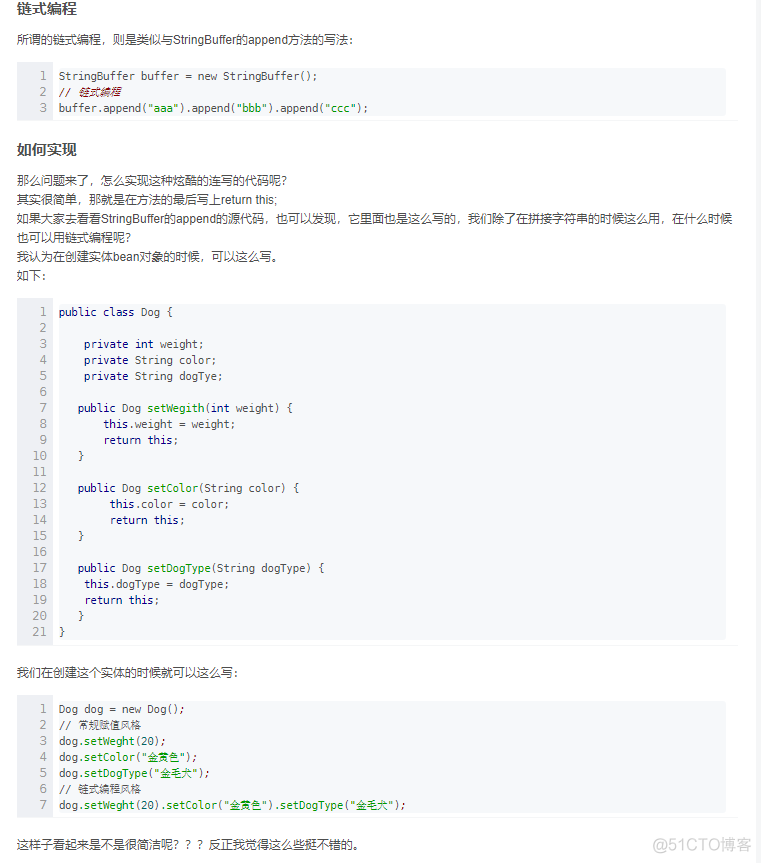
链式编程介绍

0
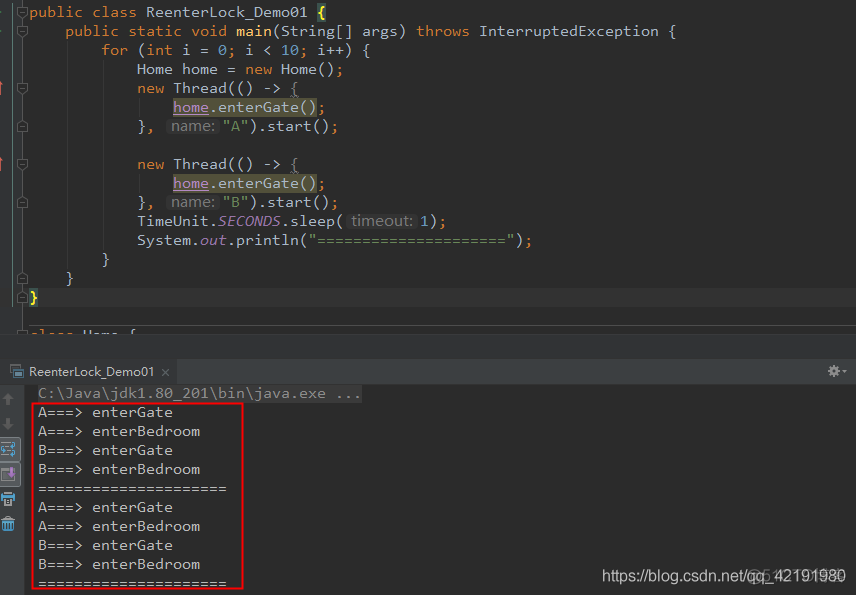
ReentrantLock
public class ReenterLock_Demo02 {
public static void main(String[] args) throws InterruptedException {
Home2 home = new Home2();
new Thread(() -> {
home.enterGate();
}, "A").start();
new Thread(() -> {
home.enterGate();
}, "B").start();
}
}
class Home2 {
Lock lock = new ReentrantLock();
//家中大门锁
public void enterGate() {
lock.lock();
try {
System.out.println(Thread.currentThread().getName() + "===> enterGate");
enterBedroom();
} catch (Exception ignored) {
} finally {
lock.unlock();
}
}
//卧室门锁
public void enterBedroom() {
lock.lock();
try {
System.out.println(Thread.currentThread().getName() + "===> enterBedroom");
} catch (Exception ignored) {
} finally {
lock.unlock();
}
}
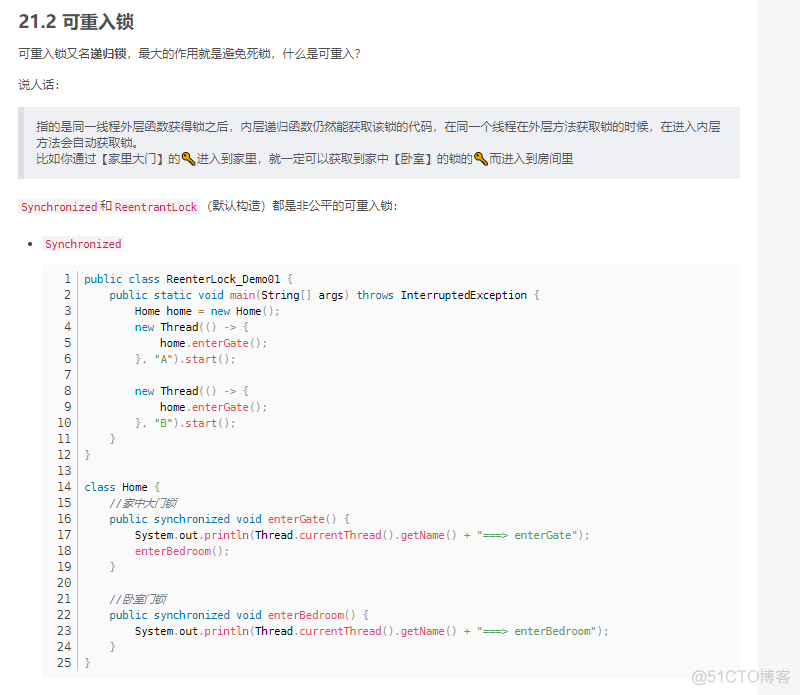
}什么是 “可重入”,可重入就是说某个线程已经获得某个锁,可以再次获取锁而不会出现死锁
21.3 自旋锁在初步认识CAS的过程中我们见识到了自旋锁:

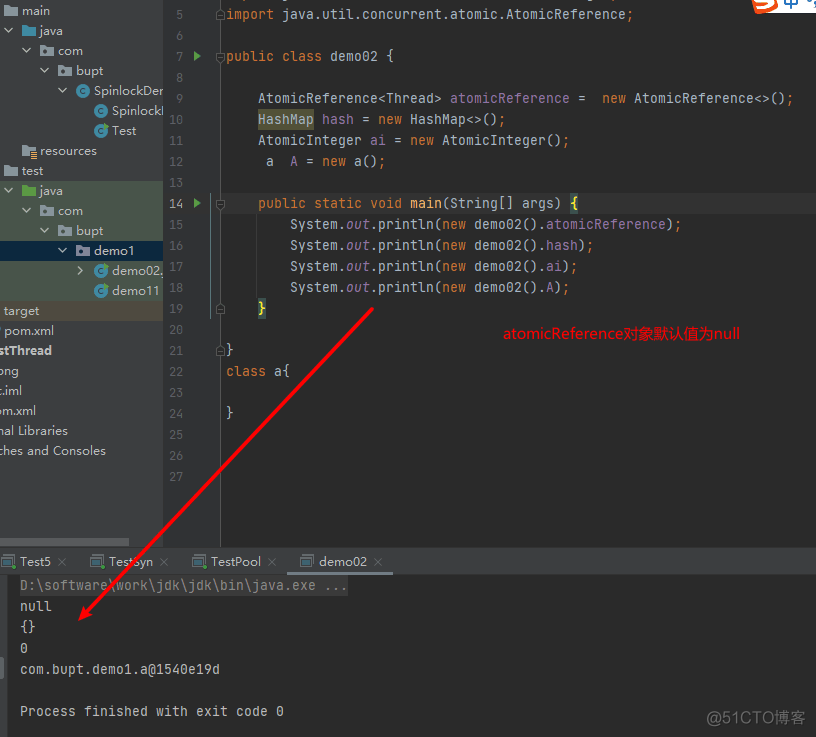
public class TestSpinLock {
public static void main(String[] args) throws InterruptedException {
MySpinlock lock = new MySpinlock();
new Thread(() -> {
lock.myLock();
try {
TimeUnit.SECONDS.sleep(5);
} catch (Exception ignored) {
} finally {
lock.myUnLock();
}
}, "T1").start();
TimeUnit.SECONDS.sleep(1);
new Thread(() -> {
lock.myLock();
try {
} catch (Exception ignored) {
} finally {
lock.myUnLock();
}
}, "T2").start();
}
}
class MySpinlock {
// Thread null
AtomicReference<Thread> atomicReference = new AtomicReference<>();
// 加锁
public void myLock() {
Thread thread = Thread.currentThread();
System.out.println(Thread.currentThread().getName() + "==> mylock");
// 自旋锁
while (!atomicReference.compareAndSet(null, thread)) {
}
}
// 解锁
public void myUnLock() {
Thread thread = Thread.currentThread();
System.out.println(Thread.currentThread().getName() + "==> myUnlock");
atomicReference.compareAndSet(thread, null);
}
}21.4 死锁互斥条件:一个资源每次只能被一个进程使用;
请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放;
不剥夺条件:进程已获得的资源,在末使用完之前,不能强行剥夺;
循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系
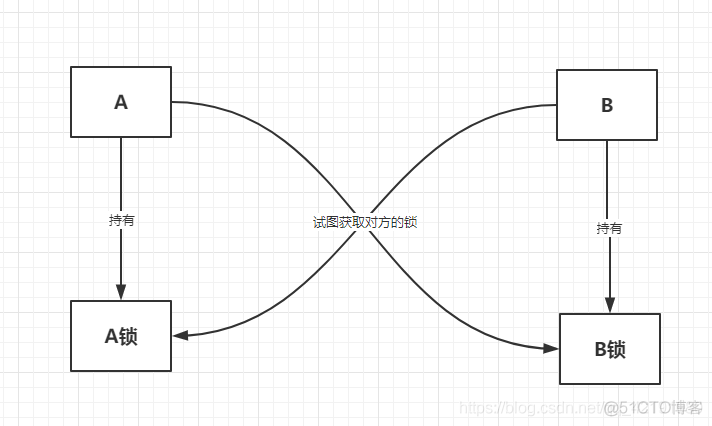
public class DeadLockDemo {
public static void main(String[] args) {
String lockA = "lockA";
String lockB = "lockB";
new Thread(new MyThread(lockA, lockB), "T1").start();
new Thread(new MyThread(lockB, lockA), "T2").start();
}
}
class MyThread implements Runnable {
private final String lockA;
private final String lockB;
public MyThread(String lockA, String lockB) {
this.lockA = lockA;
this.lockB = lockB;
}
@Override
public void run() {
//锁住lockA对象
synchronized (lockA) {
//并在输出中尝试获取lockB对象
System.out.println(Thread.currentThread().getName() + "lock:" + lockA + "=>get" + lockB);
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
//锁住lockB对象
synchronized (lockB) {
//并在输出中尝试获取lockA对象
System.out.println(Thread.currentThread().getName() + "lock:" + lockB + "=>get" + lockA);
}
}
}
}问题解决:
使用jps -l定位进程号: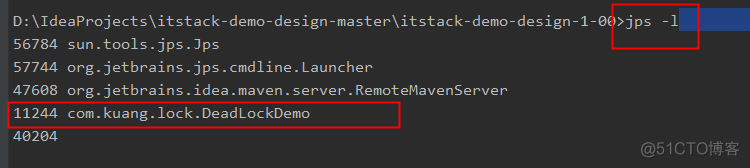
jstack 进程号找到死锁的问题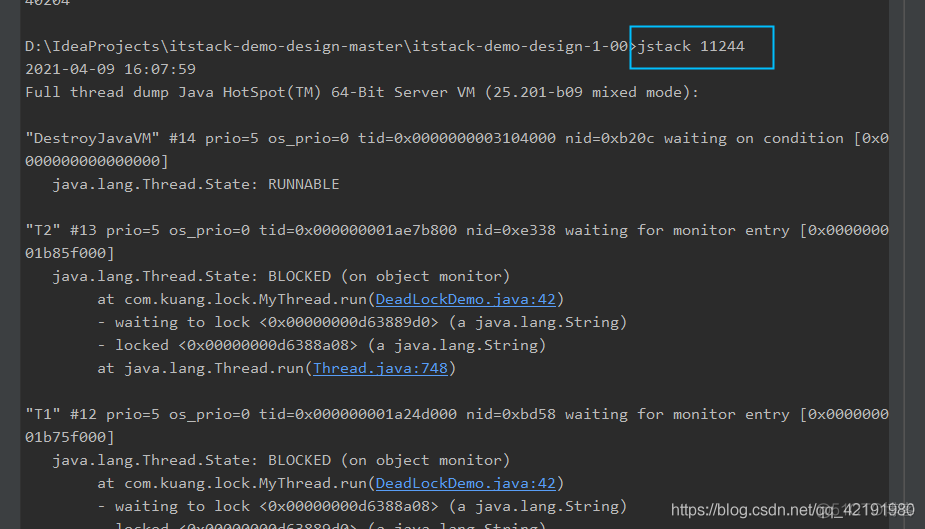
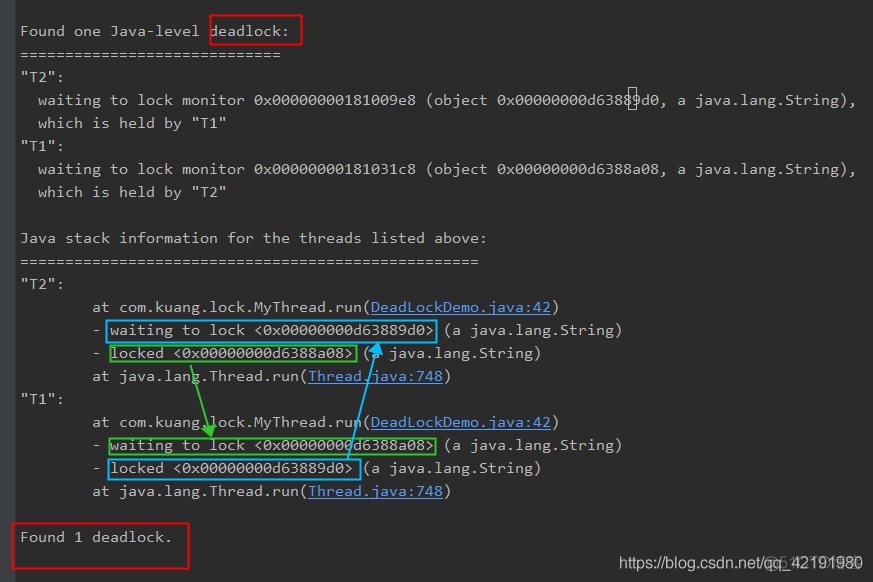
程序出现问题可以通过日志进行查看问题所在,也可以通过使用jstack等查看堆栈信息进行分析。
参考:(7条消息) 厚积薄发打卡Day49:狂神说Java之JUC并发编程<CAS入门到“锁“小结>(下)_COOLGWAYNE_TECH_BLOG-CSDN博客
java中的方法引用
volatile如何保证内存屏障在多线程的世界里,一共有三个问题:原子性问题、可见性问题、有序性问题。整个java并发体系也是围绕着如何解决这三个问题来设计的。volatile关键字也不例外,我们都知道它解决了可见性和有序性,但是不能保证原子性。这篇文章也主要基于其中一个特性,也就是研究一下volatile是如何保证有序性的。
一、有序性
1、有序性案例
有序性指的是:程序执行的顺序按照代码的先后顺序执行。我们可以先看一个被列举了一万次的代码:
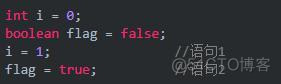
按照我们自己常规的想法,顺序应该从上往下依次执行,但是真实情况是:jvm会在真正执行这段代码的时候进行优化,发生指令的重排序。因此不能保证语句1一定在语句2先执行。
2、数据依赖性
上面的例子,你还会发现这样一个特点,就算是发生了指令的重排序,但是最后的结果总是正确的。我们再举一个例子:

这种情况会发生指令重排序吗?显然不会,原因是处理器在进行重排序时是会考虑指令之间的数据依赖性,如果一个指令2必须用到指令1的结果,那么处理器一定保证指令1在指令2执行。
3、多线程问题
这种数据的依赖性在单线程环境下一点问题没有,因为总能保证数据的正确,但是在多线程环境下就会出现错误。我们再举一个例子:
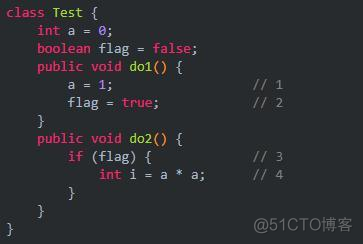
上面的这段代码由于语句1和语句2没有数据依赖性,因此会发生指令重排。do2只要看到flag为true,就执行。因此可能的顺序是:
(1)语句1先于语句2:语句2->语句3->语句1->语句4。这时候的结果i=1。
(1)语句2先于语句1:语句2->语句3->语句4->语句1。这时候的结果i=0。
现在我们可以看到在多线程环境下如果发生了指令的重排序,会对结果造成影响。
上面一开始提到过,volatile可以保证有序性,也就是可以防止指令重排序。那么它是如何解决的呢?这就是内存屏障。因此我们从内存屏障讲起。
二、内存屏障
1、什么是内存屏障
内存屏障其实就是一个CPU指令,在硬件层面上来说可以扥为两种:Load Barrier 和 Store Barrier即读屏障和写屏障。主要有两个作用:
(1)阻止屏障两侧的指令重排序;
(2)强制把写缓冲区/高速缓存中的脏数据等写回主内存,让缓存中相应的数据失效。
在JVM层面上来说作用与上面的一样,但是种类可以分为四种:
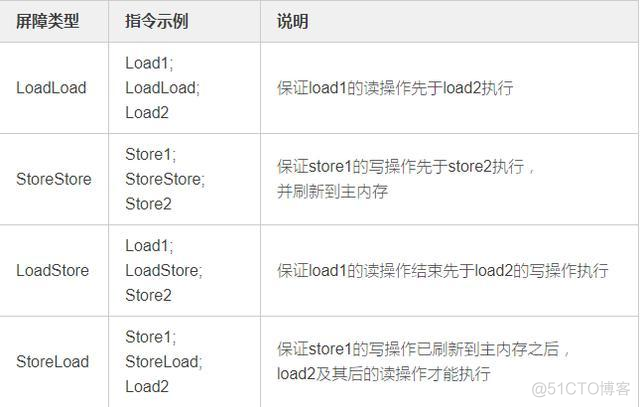
2、volatile如何保证有序性?
首先一个变量被volatile关键字修饰之后有两个作用:
(1)对于写操作:对变量更改完之后,要立刻写回到主存中。
(2)对于读操作:对变量读取的时候,要从主存中读,而不是缓存。
OK,现在针对上面JVM的四种内存屏障,应用到volatile身上。因此volatile也带有了这种效果。其实上面提到的这些内存屏障应用的效果,可以happen-before来总结归纳。
3、内存屏障分类
内存屏障有三种类型和一种伪类型:
(1)lfence:即读屏障(Load Barrier),在读指令前插入读屏障,可以让高速缓存中的数据失效,重新从主内存加载数据,以保证读取的是最新的数据。
(2)sfence:即写屏障(Store Barrier),在写指令之后插入写屏障,能让写入缓存的最新数据写回到主内存,以保证写入的数据立刻对其他线程可见。
(3)mfence,即全能屏障,具备ifence和sfence的能力。
(4)Lock前缀:Lock不是一种内存屏障,但是它能完成类似全能型内存屏障的功能。
为什么说Lock是一种伪类型的内存屏障,是因为内存屏障具有happen-before的效果,而Lock在一定程度上保证了先后执行的顺序,因此也叫做伪类型。比如,IO操作的指令,当指令不执行时,就具有了mfence的功能。

指令重排的原理是为了提升CPU多段流水线的效率
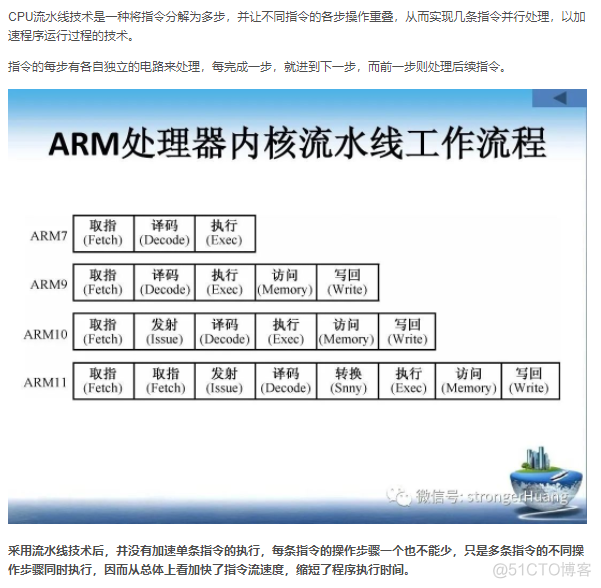
1. HashMap的数据结构
数据结构中有数组和链表来实现对数据的存储,但这两者基本上是两个极端。
数组
数组存储区间是连续的,占用内存严重,故空间复杂的很大。但数组的二分查找时间复杂度小,为O(1);数组的特点是:寻址容易,插入和删除困难;
链表
链表存储区间离散,占用内存比较宽松,故空间复杂度很小,但时间复杂度很大,达O(N)。链表的特点是:寻址困难,插入和删除容易。
哈希表
那么我们能不能综合两者的特性,做出一种寻址容易,插入删除也容易的数据结构?答案是肯定的,这就是我们要提起的哈希表。哈希表((Hash table)既满足了数据的查找方便,同时不占用太多的内容空间,使用也十分方便。
哈希表有多种不同的实现方法,我接下来解释的是最常用的一种方法——拉链法,我们可以理解为“链表的数组”,如图:
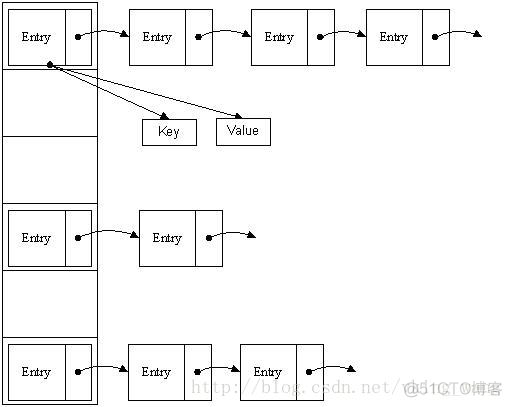
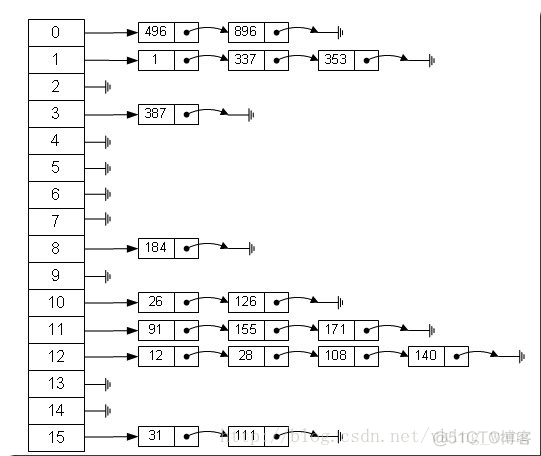
从上图我们可以发现哈希表是由数组+链表组成的,一个长度为16的数组中,每个元素存储的是一个链表的头结点。那么这些元素是按照什么样的规则存储到数组中呢。一般情况是通过hash(key)%len获得,也就是元素的key的哈希值对数组长度取模得到。比如上述哈希表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都存储在数组下标为12的位置。
HashMap其实也是一个线性的数组实现的,所以可以理解为其存储数据的容器就是一个线性数组。这可能让我们很不解,一个线性的数组怎么实现按键值对来存取数据呢?这里HashMap有做一些处理。
首先HashMap里面实现一个静态内部类Entry,其重要的属性有 key , value, next,从属性key,value我们就能很明显的看出来Entry就是HashMap键值对实现的一个基础bean,我们上面说到HashMap的基础就是一个线性数组,这个数组就是Entry[],Map里面的内容都保存在Entry[]里面。
/**
*Thetable,resizedasnecessary.LengthMUSTAlwaysbeapoweroftwo.
*/
transientEntry[]table;
2. HashMap的存取实现
既然是线性数组,为什么能随机存取?这里HashMap用了一个小算法,大致是这样实现:
// 存储时:
int hash = key.hashCode(); // 这个hashCode方法这里不详述,只要理解每个key的hash是一个固定的int值
int index = hash % Entry[].length;
Entry[index] = value;
// 取值时:
int hash = key.hashCode();
int index = hash % Entry[].length;
return
1)put
疑问:如果两个key通过hash%Entry[].length得到的index相同,会不会有覆盖的危险?
这里HashMap里面用到链式数据结构的一个概念。上面我们提到过Entry类里面有一个next属性,作用是指向下一个Entry。打个比方, 第一个键值对A进来,通过计算其key的hash得到的index=0,记做:Entry[0] = A。一会后又进来一个键值对B,通过计算其index也等于0,现在怎么办?HashMap会这样做:B.next = A,Entry[0] = B,如果又进来C,index也等于0,那么C.next = B,Entry[0] = C;这样我们发现index=0的地方其实存取了A,B,C三个键值对,他们通过next这个属性链接在一起。所以疑问不用担心。也就是说数组中存储的是最后插入的元素。到这里为止,HashMap的大致实现,我们应该已经清楚了。
public V put(K key, V value) {
if (key == null)
return putForNullKey(value); //null总是放在数组的第一个链表中
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
//遍历链表
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//如果key在链表中已存在,则替换为新value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e); //参数e, 是Entry.next
//如果size超过threshold,则扩充table大小。再散列
if (size++ >= threshold)
resize(2 * table.length);
}当然HashMap里面也包含一些优化方面的实现,这里也说一下。比如:Entry[]的长度一定后,随着map里面数据的越来越长,这样同一个index的链就会很长,会不会影响性能?HashMap里面设置一个因子,随着map的size越来越大,Entry[]会以一定的规则加长长度
2)get
publicVget(Objectkey){
if(key==null)
returngetForNullKey();
inthash=hash(key.hashCode());
//先定位到数组元素,再遍历该元素处的链表
for(Entry<K,V>e=table[indexFor(hash,table.length)];
e!=null;
e=e.next){
Objectk;
if(e.hash==hash&&((k=e.key)==key||key.equals(k)))
returne.value;
}
returnnull;
}
3)null key的存取
null key总是存放在Entry[]数组的第一个元素。
privateVputForNullKey(Vvalue){
for(Entry<K,V>e=table[0];e!=null;e=e.next){
if(e.key==null){
VoldValue=e.value;
e.value=value;
e.recordAccess(this);
returnoldValue;
}
}
modCount++;
addEntry(0,null,value,0);
returnnull;
}
privateVgetForNullKey(){
for(Entry<K,V>e=table[0];e!=null;e=e.next){
if(e.key==null)
returne.value;
}
returnnull;
}
4)确定数组index:hashcode % table.length取模
HashMap存取时,都需要计算当前key应该对应Entry[]数组哪个元素,即计算数组下标;算法如下:
/**
*Returnsindexforhashcodeh.
*/
staticintindexFor(inth,intlength){
returnh&(length-1);
}
按位取并,作用上相当于取模mod或者取余%。
这意味着数组下标相同,并不表示hashCode相同。
5)table初始大小
publicHashMap(intinitialCapacity,floatloadFactor){
.....
//Findapowerof2>=initialCapacity
intcapacity=1;
while(capacity<initialCapacity)
capacity<<=1;
this.loadFactor=loadFactor;
threshold=(int)(capacity*loadFactor);
table=newEntry[capacity];
init();
}
注意table初始大小并不是构造函数中的initialCapacity!!
而是 >= initialCapacity的2的n次幂!!!!
————为什么这么设计呢?——
3. 解决hash冲突的办法
开放定址法(线性探测再散列,二次探测再散列,伪随机探测再散列)
再哈希法
链地址法
建立一个公共溢出区
Java中hashmap的解决办法就是采用的链地址法。
4. 再散列rehash过程
当哈希表的容量超过默认容量时,必须调整table的大小。当容量已经达到最大可能值时,那么该方法就将容量调整到Integer.MAX_VALUE返回,这时,需要创建一张新表,将原表的映射到新表中。
/**
*Rehashesthecontentsofthismapintoanewarraywitha
*largercapacity.Thismethodiscalledautomaticallywhenthe
*numberofkeysinthismapreachesitsthreshold.
*
*IfcurrentcapacityisMAXIMUM_CAPACITY,thismethoddoesnot
*resizethemap,butsetsthresholdtoInteger.MAX_VALUE.
*Thishastheeffectofpreventingfuturecalls.
*
*@paramnewCapacitythenewcapacity,MUSTbeapoweroftwo;
*mustbegreaterthancurrentcapacityunlesscurrent
*capacityisMAXIMUM_CAPACITY(inwhichcasevalue
*isirrelevant).
*/
voidresize(intnewCapacity){
Entry[]oldTable=table;
intoldCapacity=oldTable.length;
if(oldCapacity==MAXIMUM_CAPACITY){
threshold=Integer.MAX_VALUE;
return;
}
Entry[]newTable=newEntry[newCapacity];
transfer(newTable);
table=newTable;
threshold=(int)(newCapacity*loadFactor);
}
/**
*TransfersallentriesfromcurrenttabletonewTable.
*/
voidtransfer(Entry[]newTable){
Entry[]src=table;
intnewCapacity=newTable.length;
for(intj=0;j<src.length;j++){
Entry<K,V>e=src[j];
if(e!=null){
src[j]=null;
do{
Entry<K,V>next=e.next;
//重新计算index
inti=indexFor(e.hash,newCapacity);
e.next=newTable[i];
newTable[i]=e;
e=next;
}while(e!=null);
}
}
}
AQS
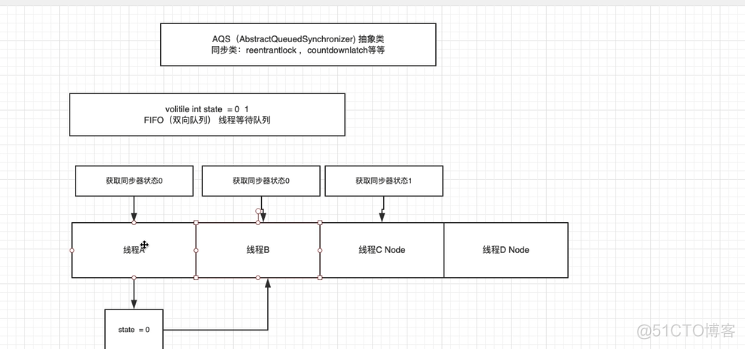
aqs中维持着一个队列和一个被volitile修饰的状态state,首先第一个获取该共享变量的线程通过自旋锁把该变量设置为1来进行加锁,其他线程获取该变量为1,而期待值是0就会一直自旋,并创建一个node结点加入到队列的尾部,线程a执行完操作后修改为0,其他线程竞争,竞争到该资源大的把自己的结点设置为头结点。
AQS:全称AbstractQueueSynchronizer,抽象队列同步器,这个类在java.util.concurrent.locks包下
它是一个底层同步工具类,比如CountDownLatch,Sammphore,ReentrantLock,ReentrantReadWriteLock等等都是基于AQS
底层三个内容:
1.state(用于计数器)
2.线程标记(哪一个线程加的锁)
3.阻塞队列(用于存放阻塞线程)
AQS提供了一种实现阻塞锁和一系列依赖FIFO等待队列的同步器的框架,如下图所示。AQS为一系列同步器依赖于一个单独的原子变量(state)的同步器提供了一个非常有用的基础。子类们必须定义改变state变量的protected方法,这些方法定义了state是如何被获取或释放的。
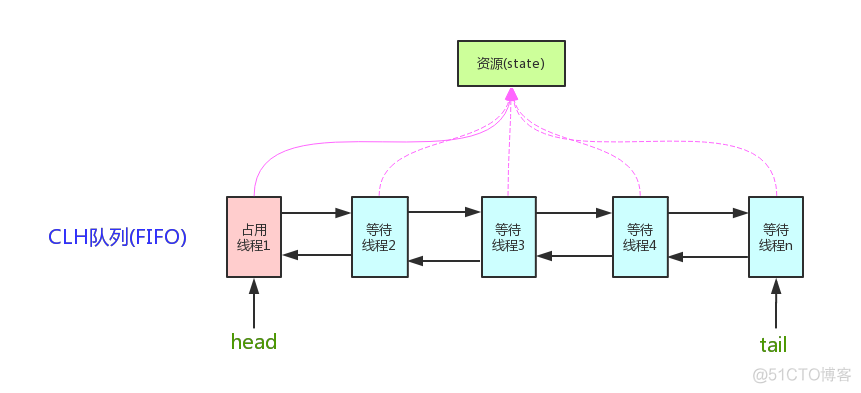
J.U.C是基于AQS实现的,AQS是一个同步器,设计模式是模板模式。
核心数据结构:双向链表 + state(锁状态)
底层操作:CAS
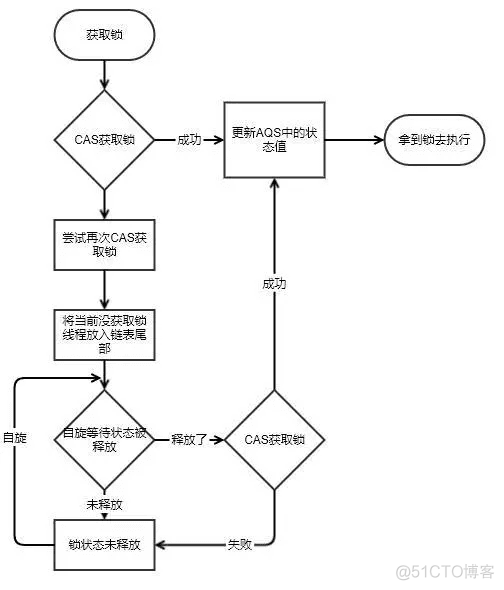
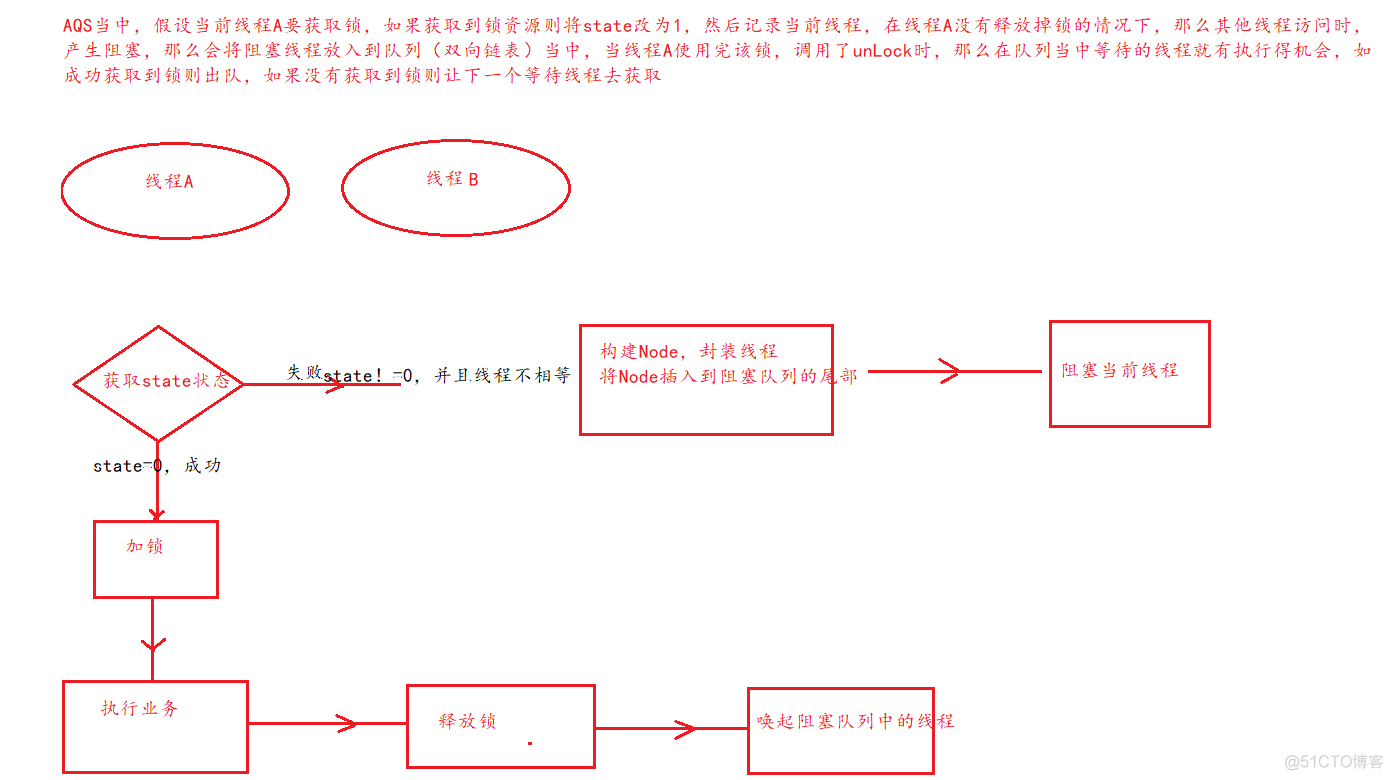
当出现锁竞争以及释放锁的时候,AQS同步队列中的节点会发生变化,首先看一下添加节点的场景。
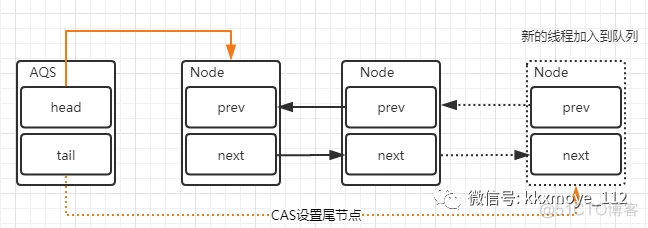
这里会涉及到两个变化
新的线程封装成Node节点追加到同步队列中,设置prev节点以及修改当前节点的前置节点的next节点指向自己通过CAS讲tail重新指向新的尾部节点释放锁移除节点head节点表示获取锁成功的节点,当头结点在释放同步状态时,会唤醒后继节点,如果后继节点获得锁成功,会把自己设置为头结点,节点的变化过程如下
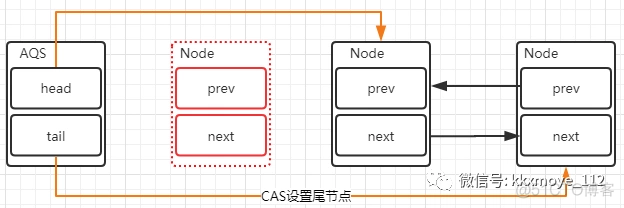
这个过程也是涉及到两个变化
修改head节点指向下一个获得锁的节点新的获得锁的节点,将prev的指针指向null这里有一个小的变化,就是设置head节点不需要用CAS,原因是设置head节点是由获得锁的线程来完成的,而同步锁只能由一个线程获得,所以不需要CAS保证,只需要把head节点设置为原首节点的后继节点,并且断开原head节点的next引用即可
作者:你的雷哥






.png)

.png)

