 云计算服务
云计算服务
 服务器租用
服务器租用
 DDOS 防护
DDOS 防护
 虚拟主机
虚拟主机
 域名服务
域名服务
 基础设施
基础设施
 关于我们
关于我们
proxy在目标对象的外层搭建了一层拦截,外界对目标对象的某些操作,必须通过这层拦截
var proxy = new Proxy(target, handler);new Proxy()表示生成一个Proxy实例,target参数表示所要拦截的目标对象,handler参数也是一个对象,用来定制拦截行为
var target = {
name: 'poetries'
};
var logHandler = {
get: function(target, key) {
console.log(`${key} 被读取`);
return target[key];
},
set: function(target, key, value) {
console.log(`${key} 被设置为 ${value}`);
target[key] = value;
}
}
var targetWithLog = new Proxy(target, logHandler);
targetWithLog.name; // 控制台输出:name 被读取
targetWithLog.name = 'others'; // 控制台输出:name 被设置为 others
console.log(target.name); // 控制台输出: otherstargetWithLog 读取属性的值时,实际上执行的是 logHandler.get :在控制台输出信息,并且读取被代理对象 target 的属性。在 targetWithLog 设置属性值时,实际上执行的是 logHandler.set :在控制台输出信息,并且设置被代理对象 target 的属性的值// 由于拦截函数总是返回35,所以访问任何属性都得到35
var proxy = new Proxy({}, {
get: function(target, property) {
return 35;
}
});
proxy.time // 35
proxy.name // 35
proxy.title // 35Proxy 实例也可以作为其他对象的原型对象
var proxy = new Proxy({}, {
get: function(target, property) {
return 35;
}
});
let obj = Object.create(proxy);
obj.time // 35proxy对象是obj对象的原型,obj对象本身并没有time属性,所以根据原型链,会在proxy对象上读取该属性,导致被拦截
Proxy的作用
对于代理模式 Proxy 的作用主要体现在三个方面拦截和监视外部对对象的访问降低函数或类的复杂度在复杂操作前对操作进行校验或对所需资源进行管理Proxy所能代理的范围--handler
实际上 handler 本身就是ES6所新设计的一个对象.它的作用就是用来 自定义代理对象的各种可代理操作 。它本身一共有13中方法,每种方法都可以代理一种操作.其13种方法如下
// 在读取代理对象的原型时触发该操作,比如在执行 Object.getPrototypeOf(proxy) 时。
handler.getPrototypeOf()
// 在设置代理对象的原型时触发该操作,比如在执行 Object.setPrototypeOf(proxy, null) 时。
handler.setPrototypeOf()
// 在判断一个代理对象是否是可扩展时触发该操作,比如在执行 Object.isExtensible(proxy) 时。
handler.isExtensible()
// 在让一个代理对象不可扩展时触发该操作,比如在执行 Object.preventExtensions(proxy) 时。
handler.preventExtensions()
// 在获取代理对象某个属性的属性描述时触发该操作,比如在执行 Object.getOwnPropertyDescriptor(proxy, "foo") 时。
handler.getOwnPropertyDescriptor()
// 在定义代理对象某个属性时的属性描述时触发该操作,比如在执行 Object.defineProperty(proxy, "foo", {}) 时。
andler.defineProperty()
// 在判断代理对象是否拥有某个属性时触发该操作,比如在执行 "foo" in proxy 时。
handler.has()
// 在读取代理对象的某个属性时触发该操作,比如在执行 proxy.foo 时。
handler.get()
// 在给代理对象的某个属性赋值时触发该操作,比如在执行 proxy.foo = 1 时。
handler.set()
// 在删除代理对象的某个属性时触发该操作,比如在执行 delete proxy.foo 时。
handler.deleteProperty()
// 在获取代理对象的所有属性键时触发该操作,比如在执行 Object.getOwnPropertyNames(proxy) 时。
handler.ownKeys()
// 在调用一个目标对象为函数的代理对象时触发该操作,比如在执行 proxy() 时。
handler.apply()
// 在给一个目标对象为构造函数的代理对象构造实例时触发该操作,比如在执行new proxy() 时。
handler.construct()为何Proxy不能被Polyfill
如class可以用function模拟;promise可以用callback模拟但是proxy不能用Object.defineProperty模拟目前谷歌的polyfill只能实现部分的功能,如get、set https://github.com/GoogleChro...
// commonJS require
const proxyPolyfill = require('proxy-polyfill/src/proxy')();
// Your environment may also support transparent rewriting of commonJS to ES6:
import ProxyPolyfillBuilder from 'proxy-polyfill/src/proxy';
const proxyPolyfill = ProxyPolyfillBuilder();
// Then use...
const myProxy = new proxyPolyfill(...);它们都是函数的方法
call: Array.prototype.call(this, args1, args2]) apply: Array.prototype.apply(this, [args1, args2]) :ES6 之前用来展开数组调用, foo.appy(null, []),ES6 之后使用 ... 操作符
四条规则:
默认绑定,没有其他修饰(bind、apply、call),在非严格模式下定义指向全局对象,在严格模式下定义指向 undefinedfunction foo() {
console.log(this.a);
}
var a = 2;
foo();
function foo() {
console.log(this.a);
}
var obj = {
a: 2,
foo: foo,
}
obj.foo(); // 2
function foo() {
console.log(this.a);
}
var obj = {
a: 2
};
foo.call(obj);
显示绑定之硬绑定
function foo(something) {
console.log(this.a, something);
return this.a + something;
}
function bind(fn, obj) {
return function() {
return fn.apply(obj, arguments);
};
}
var obj = {
a: 2
}
var bar = bind(foo, obj);
New 绑定,new 调用函数会创建一个全新的对象,并将这个对象绑定到函数调用的 this。
New 绑定时,如果是 new 一个硬绑定函数,那么会用 new 新建的对象替换这个硬绑定 this,function foo(a) {
this.a = a;
}
var bar = new foo(2);
console.log(bar.a)
前端进阶面试题详细解答
compose题目描述:实现一个 compose 函数
// 用法如下:
function fn1(x) {
return x + 1;
}
function fn2(x) {
return x + 2;
}
function fn3(x) {
return x + 3;
}
function fn4(x) {
return x + 4;
}
const a = compose(fn1, fn2, fn3, fn4);
console.log(a(1)); // 1+4+3+2+1=11
实现代码如下:
function compose(...fn) {
if (!fn.length) return (v) => v;
if (fn.length === 1) return fn[0];
return fn.reduce(
(pre, cur) =>
(...args) =>
pre(cur(...args))
);
}
在 HTML 页面中,如果在执行脚本时,页面的状态是不可相应的,直到脚本执行完成后,页面才变成可相应。web worker 是运行在后台的 js,独立于其他脚本,不会影响页面的性能。 并且通过 postMessage 将结果回传到主线程。这样在进行复杂操作的时候,就不会阻塞主线程了。
如何创建 web worker:
检测浏览器对于 web worker 的支持性创建 web worker 文件(js,回传函数等)创建 web worker 对象事件是什么?事件模型?事件是用户操作网页时发生的交互动作,比如 click/move, 事件除了用户触发的动作外,还可以是文档加载,窗口滚动和大小调整。事件被封装成一个 event 对象,包含了该事件发生时的所有相关信息( event 的属性)以及可以对事件进行的操作( event 的方法)。
事件是用户操作网页时发生的交互动作或者网页本身的一些操作,现代浏览器一共有三种事件模型:
DOM0 级事件模型,这种模型不会传播,所以没有事件流的概念,但是现在有的浏览器支持以冒泡的方式实现,它可以在网页中直接定义监听函数,也可以通过 js 属性来指定监听函数。所有浏览器都兼容这种方式。直接在dom对象上注册事件名称,就是DOM0写法。IE 事件模型,在该事件模型中,一次事件共有两个过程,事件处理阶段和事件冒泡阶段。事件处理阶段会首先执行目标元素绑定的监听事件。然后是事件冒泡阶段,冒泡指的是事件从目标元素冒泡到 document,依次检查经过的节点是否绑定了事件监听函数,如果有则执行。这种模型通过attachEvent 来添加监听函数,可以添加多个监听函数,会按顺序依次执行。DOM2 级事件模型,在该事件模型中,一次事件共有三个过程,第一个过程是事件捕获阶段。捕获指的是事件从 document 一直向下传播到目标元素,依次检查经过的节点是否绑定了事件监听函数,如果有则执行。后面两个阶段和 IE 事件模型的两个阶段相同。这种事件模型,事件绑定的函数是addEventListener,其中第三个参数可以指定事件是否在捕获阶段执行。页面有多张图片,HTTP是怎样的加载表现?在HTTP 1下,浏览器对一个域名下最大TCP连接数为6,所以会请求多次。可以用多域名部署解决。这样可以提高同时请求的数目,加快页面图片的获取速度。在HTTP 2下,可以一瞬间加载出来很多资源,因为,HTTP2支持多路复用,可以在一个TCP连接中发送多个HTTP请求。对 WebSocket 的理解WebSocket是HTML5提供的一种浏览器与服务器进行全双工通讯的网络技术,属于应用层协议。它基于TCP传输协议,并复用HTTP的握手通道。浏览器和服务器只需要完成一次握手,两者之间就直接可以创建持久性的连接, 并进行双向数据传输。
WebSocket 的出现就解决了半双工通信的弊端。它最大的特点是:服务器可以向客户端主动推动消息,客户端也可以主动向服务器推送消息。
WebSocket原理:客户端向 WebSocket 服务器通知(notify)一个带有所有接收者ID(recipients IDs)的事件(event),服务器接收后立即通知所有活跃的(active)客户端,只有ID在接收者ID序列中的客户端才会处理这个事件。
WebSocket 特点的如下:
支持双向通信,实时性更强可以发送文本,也可以发送二进制数据‘’建立在TCP协议之上,服务端的实现比较容易数据格式比较轻量,性能开销小,通信高效没有同源限制,客户端可以与任意服务器通信协议标识符是ws(如果加密,则为wss),服务器网址就是 URL与 HTTP 协议有着良好的兼容性。默认端口也是80和443,并且握手阶段采用 HTTP 协议,因此握手时不容易封禁,能通过各种 HTTP 代理服务器。Websocket的使用方法如下:
在客户端中:
// 在index.html中直接写WebSocket,设置服务端的端口号为 9999
let ws = new WebSocket('ws://localhost:9999');
// 在客户端与服务端建立连接后触发
ws.onopen = function() {
console.log("Connection open.");
ws.send('hello');
};
// 在服务端给客户端发来消息的时候触发
ws.onmessage = function(res) {
console.log(res); // 打印的是MessageEvent对象
console.log(res.data); // 打印的是收到的消息
};
// 在客户端与服务端建立关闭后触发
ws.onclose = function(evt) {
console.log("Connection closed.");
};
题目描述:柯里化(Currying),又称部分求值(Partial Evaluation),是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数而且返回结果的新函数的技术。核心思想是把多参数传入的函数拆成单参数(或部分)函数,内部再返回调用下一个单参数(或部分)函数,依次处理剩余的参数。
实现代码如下:
function currying(fn, ...args) {
const length = fn.length;
let allArgs = [...args];
const res = (...newArgs) => {
allArgs = [...allArgs, ...newArgs];
if (allArgs.length === length) {
return fn(...allArgs);
} else {
return res;
}
};
return res;
}
// 用法如下:
// const add = (a, b, c) => a + b + c;
// const a = currying(add, 1);
// console.log(a(2,3))
实现:getBoundClientRect 的实现方式,监听 scroll 事件(建议给监听事件添加节流),图片加载完会从 img 标签组成的 DOM 列表中删除,最后所有的图片加载完毕后需要解绑监听事件。
// scr 加载默认图片,data-src 保存实施懒加载后的图片
// <img src="./default.jpg" data-src="https://xxx.jpg" alt="" />
let imgs = [...document.querySelectorAll("img")];
const len = imgs.length;
let lazyLoad = function() {
let count = 0;
let deleteImgs = [];
// 获取当前可视区的高度
let viewHeight = document.documentElement.clientHeight;
// 获取当前滚动条的位置(距离顶部的距离,等价于document.documentElement.scrollTop)
let scrollTop = window.pageYOffset;
imgs.forEach((img) => {
// 获取元素的大小,及其相对于视口的位置,如 bottom 为元素底部到网页顶部的距离
let bound = img.getBoundingClientRect();
// 当前图片距离网页顶部的距离
// let imgOffsetTop = img.offsetTop;
// 判断图片是否在可视区内,如果在就加载(两种判断方式)
// if(imgOffsetTop < scrollTop + viewHeight)
if (bound.top < viewHeight) {
img.src = img.dataset.src; // 替换待加载的图片 src
count++;
deleteImgs.push(img);
// 最后所有的图片加载完毕后需要解绑监听事件
if(count === len) {
document.removeEventListener("scroll", imgThrottle);
}
}
});
// 图片加载完会从 `img` 标签组成的 DOM 列表中删除
imgs = imgs.filter((img) => !deleteImgs.includes(img));
}
window.onload = function () {
lazyLoad();
};
// 使用 防抖/节流 优化一下滚动事件
let imgThrottle = debounce(lazyLoad, 1000);
// 监听 `scroll` 事件
window.addEventListener("scroll", imgThrottle);
Object.create() 会创建一个 “新” 对象,然后将此对象内部的 [[Prototype]] 关联到你指定的对象(Foo.prototype)。Object.create(null) 创建一个空 [[Prototype]] 链接的对象,这个对象无法进行委托。
function Foo(name) {
this.name = name;
}
Foo.prototype.myName = function () {
return this.name;
}
// 继承属性,通过借用构造函数调用
function Bar(name, label) {
Foo.call(this, name);
this.label = label;
}
// 继承方法,创建备份
Bar.prototype = Object.create(Foo.prototype);
// 必须设置回正确的构造函数,要不然在会发生判断类型出错
Bar.prototype.constructor = Bar;
// 必须在上一步之后
Bar.prototype.myLabel = function () {
return this.label;
}
var a = new Bar("a", "obj a");
a.myName(); // "a"
a.myLabel(); // "obj a"
HTTP1.0 中默认是在每次请求/应答,客户端和服务器都要新建一个连接,完成之后立即断开连接,这就是短连接。当使用Keep-Alive模式时,Keep-Alive功能使客户端到服务器端的连接持续有效,当出现对服务器的后继请求时,Keep-Alive功能避免了建立或者重新建立连接,这就是长连接。其使用方法如下:
HTTP1.0版本是默认没有Keep-alive的(也就是默认会发送keep-alive),所以要想连接得到保持,必须手动配置发送Connection: keep-alive字段。若想断开keep-alive连接,需发送Connection:close字段;HTTP1.1规定了默认保持长连接,数据传输完成了保持TCP连接不断开,等待在同域名下继续用这个通道传输数据。如果需要关闭,需要客户端发送Connection:close首部字段。Keep-Alive的建立过程:
客户端向服务器在发送请求报文同时在首部添加发送Connection字段服务器收到请求并处理 Connection字段服务器回送Connection:Keep-Alive字段给客户端客户端接收到Connection字段Keep-Alive连接建立成功服务端自动断开过程(也就是没有keep-alive):
客户端向服务器只是发送内容报文(不包含Connection字段)服务器收到请求并处理服务器返回客户端请求的资源并关闭连接客户端接收资源,发现没有Connection字段,断开连接客户端请求断开连接过程:
客户端向服务器发送Connection:close字段服务器收到请求并处理connection字段服务器回送响应资源并断开连接客户端接收资源并断开连接开启Keep-Alive的优点:
较少的CPU和内存的使⽤(由于同时打开的连接的减少了);允许请求和应答的HTTP管线化;降低拥塞控制 (TCP连接减少了);减少了后续请求的延迟(⽆需再进⾏握⼿);报告错误⽆需关闭TCP连;开启Keep-Alive的缺点:
长时间的Tcp连接容易导致系统资源无效占用,浪费系统资源。说一下slice splice split 的区别?// slice(start,[end])
// slice(start,[end])方法:该方法是对数组进行部分截取,该方法返回一个新数组
// 参数start是截取的开始数组索引,end参数等于你要取的最后一个字符的位置值加上1(可选)。
// 包含了源函数从start到 end 所指定的元素,但是不包括end元素,比如a.slice(0,3);
// 如果出现负数就把负数与长度相加后再划分。
// slice中的负数的绝对值若大于数组长度就会显示所有数组
// 若参数只有一个,并且参数大于length,则为空。
// 如果结束位置小于起始位置,则返回空数组
// 返回的个数是end-start的个数
// 不会改变原数组
var arr = [1,2,3,4,5,6]
/*console.log(arr.slice(3))//[4,5,6] 从下标为0的到3,截取3之后的数console.log(arr.slice(0,3))//[1,2,3] 从下标为0的地方截取到下标为3之前的数console.log(arr.slice(0,-2))//[1,2,3,4]console.log(arr.slice(-4,4))//[3,4]console.log(arr.slice(-7))//[1,2,3,4,5,6]console.log(arr.slice(-3,-3))// []console.log(arr.slice(8))//[]*/
// 个人总结:slice的参数如果是正数就从左往右数,如果是负数的话就从右往左边数,
// 截取的数组与数的方向一致,如果是2个参数则截取的是数的交集,没有交集则返回空数组
// ps:slice也可以切割字符串,用法和数组一样,但要注意空格也算字符
// splice(start,deletecount,item)
// start:起始位置
// deletecount:删除位数
// item:替换的item
// 返回值为被删除的字符串
// 如果有额外的参数,那么item会插入到被移除元素的位置上。
// splice:移除,splice方法从array中移除一个或多个数组,并用新的item替换它们。
//举一个简单的例子
var a=['a','b','c'];
var b=a.splice(1,1,'e','f');
console.log(a) //['a', 'e', 'f', 'c']
console.log(b) //['b']
var a = [1, 2, 3, 4, 5, 6];
//console.log("被删除的为:",a.splice(1, 1, 8, 9)); //被删除的为:2
// console.log("a数组元素:",a); //1,8,9,3,4,5,6
// console.log("被删除的为:", a.splice(0, 2)); //被删除的为:1,2
// console.log("a数组元素:", a) //3,4,5,6
console.log("被删除的为:", a.splice(1, 0, 2, 2)) //插入 第二个数为0,表示删除0个
console.log("a数组元素:", a) //1,2,2,2,3,4,5,6
// split(字符串)
// string.split(separator,limit):split方法把这个string分割成片段来创建一个字符串数组。
// 可选参数limit可以限制被分割的片段数量。
// separator参数可以是一个字符串或一个正则表达式。
// 如果separator是一个空字符,会返回一个单字符的数组,不会改变原数组。
var a="0123456";
var b=a.split("",3);
console.log(b);//b=["0","1","2"]
// 注意:String.split() 执行的操作与 Array.join 执行的操作是相反的。
function Person(name) {
this.name = name;
}
Person.prototype.constructor = Person
标准答案更正确的解释
什么是原型链?
当对象查找一个属性的时候,如果没有在自身找到,那么就会查找自身的原型,如果原型还没有找到,那么会继续查找原型的原型,直到找到 Object.prototype 的原型时,此时原型为 null,查找停止。
这种通过 通过原型链接的逐级向上的查找链被称为原型链
什么是原型继承?
一个对象可以使用另外一个对象的属性或者方法,就称之为继承。具体是通过将这个对象的原型设置为另外一个对象,这样根据原型链的规则,如果查找一个对象属性且在自身不存在时,就会查找另外一个对象,相当于一个对象可以使用另外一个对象的属性和方法了。
对line-height 的理解及其赋值方式(1)line-height的概念:
line-height 指一行文本的高度,包含了字间距,实际上是下一行基线到上一行基线距离;如果一个标签没有定义 height 属性,那么其最终表现的高度由 line-height 决定;一个容器没有设置高度,那么撑开容器高度的是 line-height,而不是容器内的文本内容;把 line-height 值设置为 height 一样大小的值可以实现单行文字的垂直居中;line-height 和 height 都能撑开一个高度;(2)line-height 的赋值方式:
带单位:px 是固定值,而 em 会参考父元素 font-size 值计算自身的行高纯数字:会把比例传递给后代。例如,父级行高为 1.5,子元素字体为 18px,则子元素行高为 1.5 * 18 = 27px百分比:将计算后的值传递给后代HTTP3Google 在推SPDY的时候就已经意识到了这些问题,于是就另起炉灶搞了一个基于 UDP 协议的“QUIC”协议,让HTTP跑在QUIC上而不是TCP上。主要特性如下:实现了类似TCP的流量控制、传输可靠性的功能。虽然UDP不提供可靠性的传输,但QUIC在UDP的基础之上增加了一层来保证数据可靠性传输。它提供了数据包重传、拥塞控制以及其他一些TCP中存在的特性实现了快速握手功能。由于QUIC是基于UDP的,所以QUIC可以实现使用0-RTT或者1-RTT来建立连接,这意味着QUIC可以用最快的速度来发送和接收数据。集成了TLS加密功能。目前QUIC使用的是TLS1.3,相较于早期版本TLS1.3有更多的优点,其中最重要的一点是减少了握手所花费的RTT个数。多路复用,彻底解决TCP中队头阻塞的问题。DOM 节点操作
(1)创建新节点
createDocumentFragment() //创建一个DOM片段
createElement() //创建一个具体的元素
createTextNode() //创建一个文本节点(2)添加、移除、替换、插入
appendChild(node)
removeChild(node)
replaceChild(new,old)
insertBefore(new,old)(3)查找
getElementById();
getElementsByName();
getElementsByTagName();
getElementsByClassName();
querySelector();
querySelectorAll();(4)属性操作
getAttribute(key);
setAttribute(key, value);
hasAttribute(key);
removeAttribute(key);短轮询和长轮询的目的都是用于实现客户端和服务器端的一个即时通讯。
短轮询的基本思路: 浏览器每隔一段时间向浏览器发送 http 请求,服务器端在收到请求后,不论是否有数据更新,都直接进行响应。这种方式实现的即时通信,本质上还是浏览器发送请求,服务器接受请求的一个过程,通过让客户端不断的进行请求,使得客户端能够模拟实时地收到服务器端的数据的变化。这种方式的优点是比较简单,易于理解。缺点是这种方式由于需要不断的建立 http 连接,严重浪费了服务器端和客户端的资源。当用户增加时,服务器端的压力就会变大,这是很不合理的。
长轮询的基本思路: 首先由客户端向服务器发起请求,当服务器收到客户端发来的请求后,服务器端不会直接进行响应,而是先将这个请求挂起,然后判断服务器端数据是否有更新。如果有更新,则进行响应,如果一直没有数据,则到达一定的时间限制才返回。客户端 JavaScript 响应处理函数会在处理完服务器返回的信息后,再次发出请求,重新建立连接。长轮询和短轮询比起来,它的优点是明显减少了很多不必要的 http 请求次数,相比之下节约了资源。长轮询的缺点在于,连接挂起也会导致资源的浪费。
SSE 的基本思想: 服务器使用流信息向服务器推送信息。严格地说,http 协议无法做到服务器主动推送信息。但是,有一种变通方法,就是服务器向客户端声明,接下来要发送的是流信息。也就是说,发送的不是一次性的数据包,而是一个数据流,会连续不断地发送过来。这时,客户端不会关闭连接,会一直等着服务器发过来的新的数据流,视频播放就是这样的例子。SSE 就是利用这种机制,使用流信息向浏览器推送信息。它基于 http 协议,目前除了 IE/Edge,其他浏览器都支持。它相对于前面两种方式来说,不需要建立过多的 http 请求,相比之下节约了资源。
WebSocket 是 HTML5 定义的一个新协议议,与传统的 http 协议不同,该协议允许由服务器主动的向客户端推送信息。使用 WebSocket 协议的缺点是在服务器端的配置比较复杂。WebSocket 是一个全双工的协议,也就是通信双方是平等的,可以相互发送消息,而 SSE 的方式是单向通信的,只能由服务器端向客户端推送信息,如果客户端需要发送信息就是属于下一个 http 请求了。
上面的四个通信协议,前三个都是基于HTTP协议的。
对于这四种即使通信协议,从性能的角度来看: WebSocket > 长连接(SEE) > 长轮询 > 短轮询 但是,我们如果考虑浏览器的兼容性问题,顺序就恰恰相反了: 短轮询 > 长轮询 > 长连接(SEE) > WebSocket 所以,还是要根据具体的使用场景来判断使用哪种方式。
GeneratorGenerator是ES6中新增的语法,和Promise一样,都可以用来异步编程。Generator函数可以说是Iterator接口的具体实现方式。Generator 最大的特点就是可以控制函数的执行。
function* 用来声明一个函数是生成器函数,它比普通的函数声明多了一个*,*的位置比较随意可以挨着 function 关键字,也可以挨着函数名yield 产出的意思,这个关键字只能出现在生成器函数体内,但是生成器中也可以没有yield 关键字,函数遇到 yield 的时候会暂停,并把 yield 后面的表达式结果抛出去next作用是将代码的控制权交还给生成器函数function *foo(x) {
let y = 2 * (yield (x + 1))
let z = yield (y / 3)
return (x + y + z)
}
let it = foo(5)
console.log(it.next()) // => {value: 6, done: false}
console.log(it.next(12)) // => {value: 8, done: false}
console.log(it.next(13)) // => {value: 42, done: true}上面这个示例就是一个Generator函数,我们来分析其执行过程:
首先 Generator 函数调用时它会返回一个迭代器当执行第一次 next 时,传参会被忽略,并且函数暂停在 yield (x + 1) 处,所以返回 5 + 1 = 6当执行第二次 next 时,传入的参数等于上一个 yield 的返回值,如果你不传参,yield 永远返回 undefined。此时 let y = 2 12,所以第二个 yield 等于 2 12 / 3 = 8当执行第三次 next 时,传入的参数会传递给 z,所以 z = 13, x = 5, y = 24,相加等于 42yield实际就是暂缓执行的标示,每执行一次next(),相当于指针移动到下一个yield位置
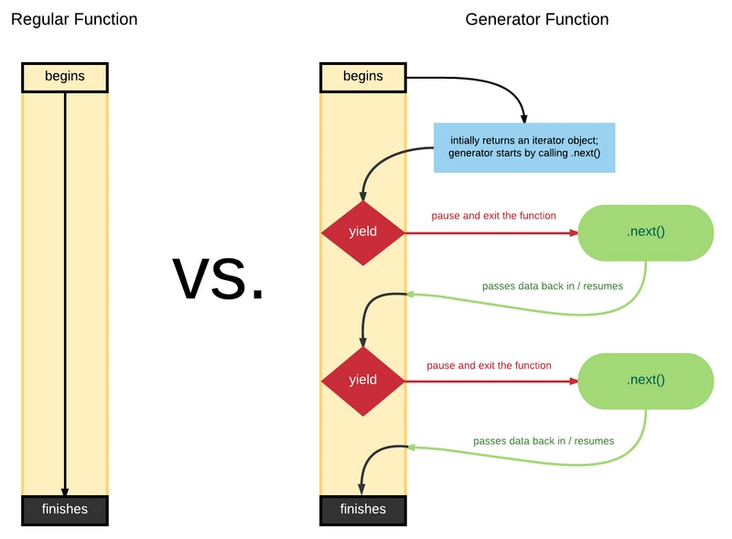
总结一下 ,Generator函数是ES6提供的一种异步编程解决方案。通过yield标识位和next()方法调用,实现函数的分段执行
遍历器对象生成函数,最大的特点是可以交出函数的执行权
function 关键字与函数名之间有一个星号;函数体内部使用 yield表达式,定义不同的内部状态;next指针移向下一个状态这里你可以说说回调函数事件监听发布/订阅Generator的异步编程,以及它的语法糖async和awiat,传统的异步编程。ES6之前,异步编程大致如下
传统异步编程方案之一:协程,多个线程互相协作,完成异步任务。
// 使用 * 表示这是一个 Generator 函数
// 内部可以通过 yield 暂停代码
// 通过调用 next 恢复执行
function* test() {
let a = 1 + 2;
yield 2;
yield 3;
}
let b = test();
console.log(b.next()); // > { value: 2, done: false }
console.log(b.next()); // > { value: 3, done: false }
console.log(b.next()); // > { value: undefined, done: true }从以上代码可以发现,加上*的函数执行后拥有了next函数,也就是说函数执行后返回了一个对象。每次调用next函数可以继续执行被暂停的代码。以下是Generator函数的简单实现
// cb 也就是编译过的 test 函数
function generator(cb) {
return (function() {
var object = {
next: 0,
stop: function() {}
};
return {
next: function() {
var ret = cb(object);
if (ret === undefined) return { value: undefined, done: true };
return {
value: ret,
done: false
};
}
};
})();
}
// 如果你使用 babel 编译后可以发现 test 函数变成了这样
function test() {
var a;
return generator(function(_context) {
while (1) {
switch ((_context.prev = _context.next)) {
// 可以发现通过 yield 将代码分割成几块
// 每次执行 next 函数就执行一块代码
// 并且表明下次需要执行哪块代码
case 0:
a = 1 + 2;
_context.next = 4;
return 2;
case 4:
_context.next = 6;
return 3;
// 执行完毕
case 6:
case "end":
return _context.stop();
}
}
});
}共同点:
改变行内元素的呈现方式,将display置为inline-block使元素脱离普通文档流,不再占据文档物理空间覆盖非定位文档元素不同点:
abuselute与fixed的根元素不同,abuselute的根元素可以设置,fixed根元素是浏览器。在有滚动条的页面中,absolute会跟着父元素进行移动,fixed固定在页面的具体位置。懒加载的特点减少无用资源的加载:使用懒加载明显减少了服务器的压力和流量,同时也减小了浏览器的负担。提升用户体验: 如果同时加载较多图片,可能需要等待的时间较长,这样影响了用户体验,而使用懒加载就能大大的提高用户体验。防止加载过多图片而影响其他资源文件的加载 :会影响网站应用的正常使用。





.png)

.png)

