 云计算服务
云计算服务
 服务器租用
服务器租用
 DDOS 防护
DDOS 防护
 虚拟主机
虚拟主机
 域名服务
域名服务
 基础设施
基础设施
 关于我们
关于我们
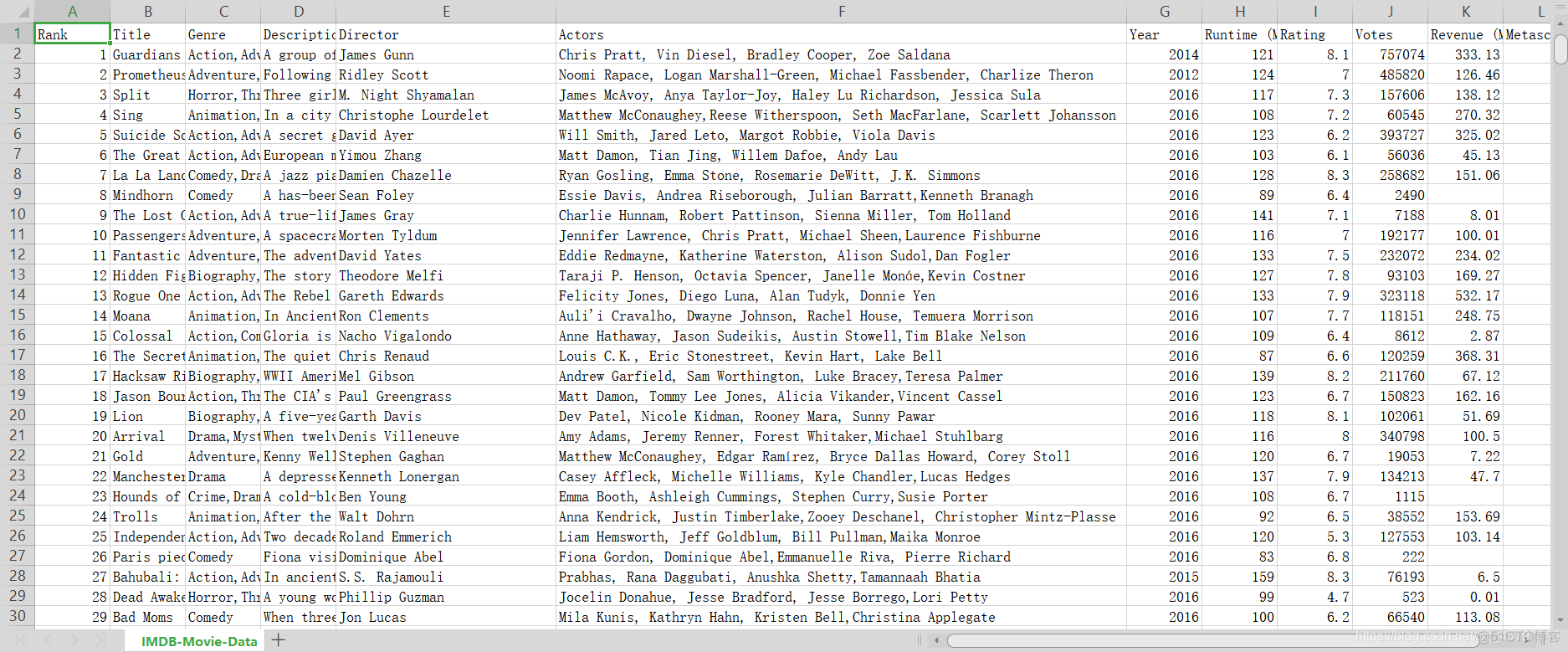
数据分析.pandas.字符串离散(案例)一、字符串离散

1.概念:在这里本人所理解的就是将原本大量数据,以某个符号分割开来,便于后继的统计分析。
2.分离方法:str.split(“,”)
temp_actors_list = df["Actors"].str.split(",").tolist()
案例1
2006-2016年1000部流行电影的数据,分离出评分的均分、导演人数等数据
import numpy as np
import pandas as pd
# 读取外部CSV文件
file_path = "Topmovies/IMDB-Movie-Data.csv"
df = pd.read_csv(file_path)
#查看数据总体信息
#print(df.info())
#查看第一条数据
#print(df.head(1))
#获取平均评分
print(df["Rating"].mean()) #6.723199999999999
#获取导演的人数
print(len(set(df["Director"].tolist()))) #644
#方法一
# 1.tolist() ---> Return a list of the values. 返回值列表
# 2.set()
# def __init__(self, seq=()): # known special case of set.__init__
# """
# set() -> new empty set object
# set(iterable) -> new set object
#
# Build an unordered collection of unique elements. 建立独特元素的无序集合
# # (copied from class doc)
# """
# pass
# 3.len()
# def len(*args, **kwargs): # real signature unknown
# """ Return the number of items in a container. """ 返回容器中的项目数
# pass
#方法二
print(len(df["Director"].unique())) #644
# 1.unique() 该方法返回的是:去除目标列中重复值后的唯一值数组。本案例中就是返回所有导演名字的一个数组。
# def unique(self):
# """
# Compute the ExtensionArray of unique values. 计算唯一值的扩展数组。
#
# Returns
# -------
# uniques : ExtensionArray
# """
# uniques = unique(self.astype(object))
# return self._from_sequence(uniques, dtype=self.dtype)
#获取演员的人数
temp_actors_list = df["Actors"].str.split(",").tolist()
actors_list = [i for j in temp_actors_list for i in j]
actors_num = len(set(actors_list))
print(actors_num) #2394
#获取电影时长的最大值、最小值
max_runtime = df["Runtime (Minutes)"].max()
print(max_runtime) #191
max_runtime_index = df["Runtime (Minutes)"].argmax()
print(max_runtime_index ) #828
min_runtime = df["Runtime (Minutes)"].min()
print(min_runtime) #66
min_runtime_index = df["Runtime (Minutes)"].argmin()
print(min_runtime_index ) #793
median_runtime = df["Runtime (Minutes)"].median()
print(median_runtime ) #111.0
注意点:
由于数据的特殊性:导演均是一位,二演员不止有一位,所以在我们统计人数时,做法会不一样,但是总的思路方法一致。
#获取导演的人数
#方法一
print(len(set(df["Director"].tolist()))) #644
#方法二
print(len(df["Director"].unique())) #644
在获取导演人数时,中间做出所有导演列表时有两种方法,具体参见代码注释。
#获取演员的人数
temp_actors_list = df["Actors"].str.split(",").tolist()
actors_list = [i for j in temp_actors_list for i in j]
actors_num = len(set(actors_list))
print(actors_num) #2394
在获取演员的人数时,需要多做一步actors_list = [i for j in temp_actors_list for i in j],是因为演员不止一个,在获取演员列表时出现列表嵌套列表的情况:[[第一部电影演员][第二部电影演员][第三部电影演员]…],此时需要循环将其展开。
案例2
统计电影的分类情况
难点:由于每一部电影的分类都不是唯一的,比如:某一部电影既是科幻类,也是爱情类,这样子在统计的时候两分类都得加上去。
思路:重新构造一个全为零的数组,列名为分类,若某一条数据中出现过该分类,则对应列加1。
#数据的合并和分组聚合----统计电影的分类情况
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from matplotlib import font_manager
# 读取外部CSV文件
file_path = "Topmovies/IMDB-Movie-Data.csv"
df = pd.read_csv(file_path)
#难点:由于每一部电影的分类都不是唯一的,比如:某一部电影既是科幻类,也是爱情类,这样子在统计的时候两分类都得加上去
#思路:重新构造一个全为零的数组,列名为分类,若某一条数据中出现过该分类,则对应列加1
#1.统计分类的列表
temp_genre_list = df["Genre"].str.split(",").tolist()
#列表嵌列表的形式
# [['Action', 'Adventure', 'Sci-Fi'], ['Adventure', 'Mystery', 'Sci-Fi'], ……]
genre_list = list(set([i for j in temp_genre_list for i in j]))
#返回出所有的电影类别
#['Adventure', 'Western', 'Comedy', 'Musical', 'Sci-Fi', 'Animation', 'Music', 'Action', 'Biography', 'War', 'Sport', 'Horror', 'Romance', 'Drama', 'Fantasy', 'Crime', 'Mystery', 'Family', 'Thriller', 'History']
#2.构造全为零的数组
zero_df = pd.DataFrame(np.zeros((df.shape[0],len(genre_list))),columns=genre_list)
print(zero_df)
# War Family Mystery History ... Animation Comedy Romance Thriller
# 0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
# 1 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
# 2 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
# 3 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
# 4 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
# .. ... ... ... ... ... ... ... ... ...
# 995 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
# 996 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
# 997 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
# 998 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
# 999 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
# [1000 rows x 20 columns]
#3.给每个电影分类出现的位置赋值
for i in range(df.shape[0]):
zero_df.loc[i,temp_genre_list[i]] = 1
print(df["Genre"].head(3))
print(zero_df.head(3))
#取前三行进行检验,(中间部分被省略)
# 0 Action,Adventure,Sci-Fi
# 1 Adventure,Mystery,Sci-Fi
# 2 Horror,Thriller
# Name: Genre, dtype: object
# Drama Sport History Romance ... Musical Adventure Action Music
# 0 0.0 0.0 0.0 0.0 ... 0.0 1.0 1.0 0.0
# 1 0.0 0.0 0.0 0.0 ... 0.0 1.0 0.0 0.0
# 2 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
# [3 rows x 20 columns]
#统计每个分类的和(每一列的和)
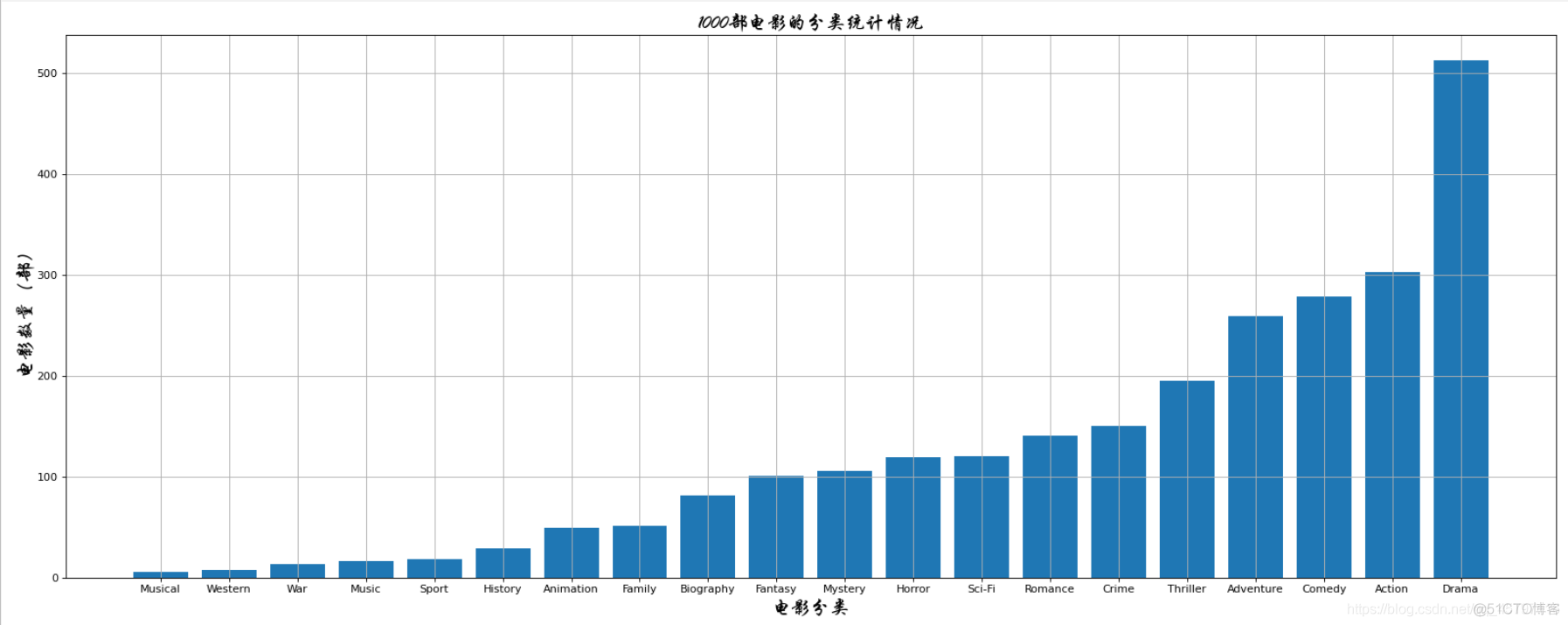
genre_count = zero_df.sum(axis=0)
genre_count = genre_count.sort_values()
print(genre_count)
# Musical 5.0
# Western 7.0
# War 13.0
# Music 16.0
# Sport 18.0
# History 29.0
# Animation 49.0
# Family 51.0
# Biography 81.0
# Fantasy 101.0
# Mystery 106.0
# Horror 119.0
# Sci-Fi 120.0
# Romance 141.0
# Crime 150.0
# Thriller 195.0
# Adventure 259.0
# Comedy 279.0
# Action 303.0
# Drama 513.0
# dtype: float64
#设置字体
my_font=font_manager.FontProperties(fname="C:\Windows\Fonts\STXINGKA.TTF",size=18)
#设置图形大小
plt.figure(figsize=(20,8),dpi=80)
#设置坐标轴
_x = genre_count.index
_y = genre_count.values
#设置坐标轴信息
plt.xlabel("电影分类",fontproperties=my_font)
plt.ylabel("电影数量(部)",fontproperties=my_font)
plt.title("1000部电影的分类统计情况",fontproperties=my_font)
#绘制图形
plt.bar(range(len(_x)),_y)
plt.xticks(range(len(_x)),_x)
#添加网格
plt.grid()
#展示
plt.show()
注意点:
#1.统计分类的列表
temp_genre_list = df["Genre"].str.split(",").tolist()
#列表嵌列表的形式
# [['Action', 'Adventure', 'Sci-Fi'], ['Adventure', 'Mystery'
# , 'Sci-Fi'], ……]
genre_list = list(set([i for j in temp_genre_list for i in j]))
#返回出所有的电影类别
#['Adventure', 'Western', 'Comedy', 'Musical', 'Sci-Fi',
#'Animation', 'Music', 'Action', 'Biography', 'War', 'Sport',
# 'Horror', 'Romance', 'Drama', 'Fantasy', 'Crime', 'Mystery',
#'Family', 'Thriller', 'History']
这个地方就出现了与上面一个例子一样的问题,不再过多解释,参见上面一个注意点~
#3.给每个电影分类出现的位置赋值
for i in range(df.shape[0]): #循环
zero_df.loc[i,temp_genre_list[i]] = 1
print(df["Genre"].head(3))
print(zero_df.head(3))
#取前三行进行检验,(中间部分被省略)
# 0 Action,Adventure,Sci-Fi
# 1 Adventure,Mystery,Sci-Fi
# 2 Horror,Thriller
# Name: Genre, dtype: object
# Drama Sport History Romance ... Musical Adventure Action Music
# 0 0.0 0.0 0.0 0.0 ... 0.0 1.0 1.0 0.0
# 1 0.0 0.0 0.0 0.0 ... 0.0 1.0 0.0 0.0
# 2 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
# [3 rows x 20 columns]
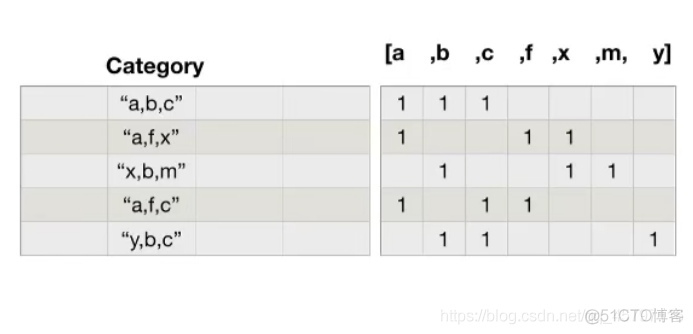
对于给每个电影分类出现的位置赋值,我们举出前三行示例,会发现在每部电影相对应的类型下都会加1,有记录(中间数据过多省略),重要的是 zero_df.loc[i,temp_genre_list[i]] = 1这步,通过标签索引行的形式进行对应分类赋值。
当i=0时,temp_genre_list[0]就是['Action', 'Adventure', 'Sci-Fi'],所以对应的’Action’, ‘Adventure’, 'Sci-Fi’列下会记录为1.最后计算该列的总和即可。
返回






.png)

.png)

