 云计算服务
云计算服务
 服务器租用
服务器租用
 DDOS 防护
DDOS 防护
 虚拟主机
虚拟主机
 域名服务
域名服务
 基础设施
基础设施
 关于我们
关于我们

Tesseract 两个重要的github连接:
https://github.com/rmtheis/tess-two
https://github.com/tesseract-ocr/tessdata

1、添加依赖 compile 'com.rmtheis:tess-two:8.0.0'(这应该再熟悉不过了)
2、从上面的第二个tessdata的链接下载对应的字库,创建assets目录,添加字库,如下图
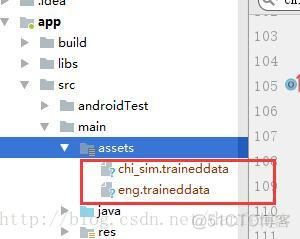
3、编码
(1)初始化TessBaseAPI
路径
private String mDataPath=Environment.getExternalStorageDirectory().getAbsolutePath()+"/tessdata/";
下面创建目录跟复制字库我都放在了onCreate方法中,但是这样的话activity会出现空白一小会儿。
//创建父目录
File parentfile=new File(mDataPath);
if (!parentfile.exists()){
parentfile.mkdir();
}
copyFiles();//复制字库,具体代码见下文
String lang = "chi_sim+eng";//中文简体+英文
mTess = new TessBaseAPI();
mTess.init(mFilePath, lang);//mFilePath不知道?
(2)复制字库
private void copyFiles() {
//循环复制2中字库
String[] datafilepaths = new String[]{mDataPath + "/chi_sim.traineddata",mDataPath+"/eng.traineddata"};
for (String datafilepath : datafilepaths) {
copyFile(datafilepath);
}
}
private void copyFile(String datafilepath) {
try {
String filepath = datafilepath;
String[] filesegment = filepath.split(File.separator);
String filename = filesegment[(filesegment.length - 1)];//获取chi_sim.traineddata和eng.traineddata文件名
AssetManager assetManager = getAssets();
InputStream instream = assetManager.open(filename);//打开chi_sim.traineddata和eng.traineddata文件
OutputStream outstream = new FileOutputStream(filepath);
byte[] buffer = new byte[1024];
int read;
while ((read = instream.read(buffer)) != -1) {
outstream.write(buffer, 0, read);
}
outstream.flush();
outstream.close();
instream.close();
File file = new File(filepath);
if (!file.exists()) {
throw new FileNotFoundException();
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch(3)获得结果
这一步属于是耗时操作,建议异步进行AsyncTask或者Rxjava
Long starttime=System.currentTimeMillis();
String OCRresult = null;
mTess.setImage(bitmap);
OCRresult = mTess.getUTF8Text();
Long endtime=System.currentTimeMillis();
Log.e("耗时时间",(endtime-starttime)+"");
总结:
1、两种语言进行的识别时间会比单纯一种语言的识别慢很多倍,如果是识别少量文字,速度还可以,但是如果需要识别大量文字,几乎是要崩溃……这个有待改进
2、上图我还没有加osd.traineddata,试了下旋转过的图片效果不好
3、识别效果的好坏还跟你处理的图片的好坏有关系,多方面因素吧。






.png)

.png)

