 云计算服务
云计算服务
 服务器租用
服务器租用
 DDOS 防护
DDOS 防护
 虚拟主机
虚拟主机
 域名服务
域名服务
 基础设施
基础设施
 关于我们
关于我们
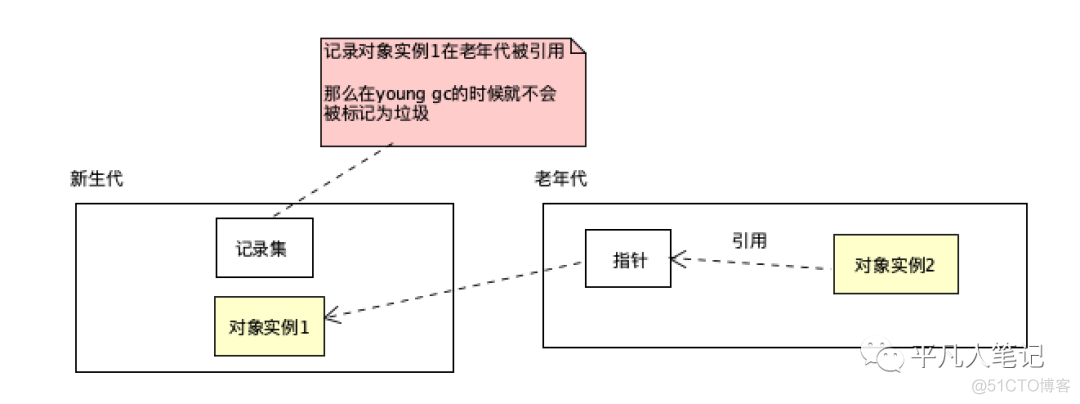
在新生代做GCRoots可达性扫描过程中可能会碰到跨代引用的现象卡表
这种如果又去对老年代再去扫描效率太低了
为此 在新生代引入记录集(Remember Set)的数据结构(记录从非收集区到收集区的指针集合)
避免把整个老年代加入GCRoots扫描范围
事实上并不只是新生代、老年代之间才有跨代引用的问题
所有涉及部门区域收集(Partial GC)行为的垃圾收集器
典型的如G1、ZGC和Shenandoah收集器 都会面临相同的问题
垃圾收集场景中 收集器只需通过记忆集判断出某一块非收集区域是否存在
指向收集区域的指针即可 无需了解跨代引用指针的全部细节
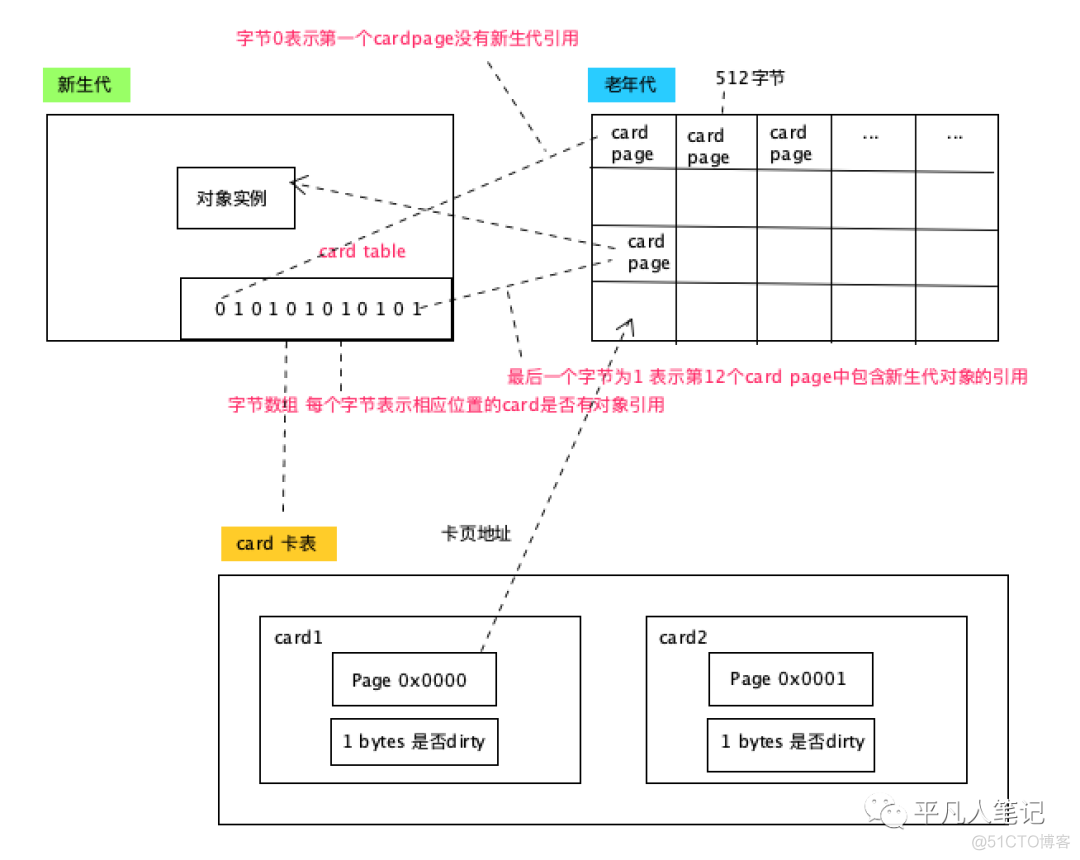
hotspot使用一种叫做"卡表"的方式实现记忆集
关于卡表和记忆集的关系可以比作HashMap和Map和关系
卡表是使用一个字节数组实现CARD_TABLE[]
每个元素对应其标识的内存区域一块特定大小的内存块 成为卡页
hotspot使用的卡页是2^9大小 即512字节
一个卡页中可包含多个对象 只要有一个对象的字段存在跨代指针
其对应的卡表元素标识就变成1 表示该元素变脏 否则为0
GC时 只要筛选本收集区的卡表中变脏的元素加入GCRoots里
卡表的维护

如何让卡表变脏?
即发生引用字段赋值时 如何更新卡表对应的标识为1G1垃圾回收器
Hotspot使用写屏障维护卡表状态
Java9默认是G1垃圾收集器
Java8也可以设置为G1 但算法性能还不算最优 某些场景下不如CMS
G1(Garbage-First)是一款面向服务器的垃圾收集器
主要针对多颗处理器及大容量内存的机器
以极高概率满足GC停顿时间要求的同时
还具备高吞吐量性能特征
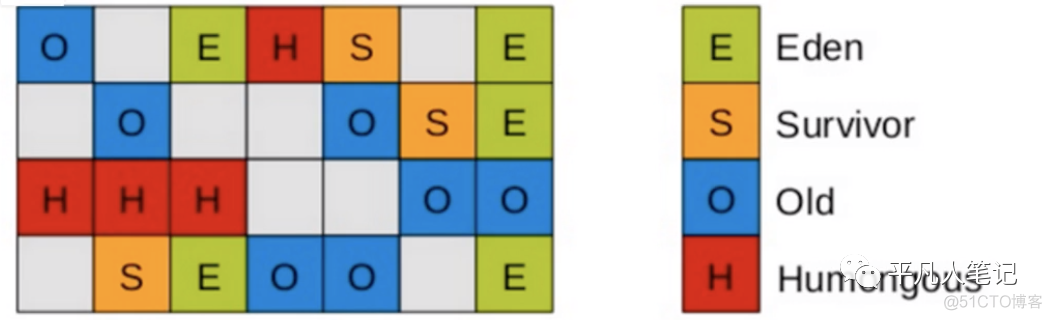
在物理上没有分代的概念 但在逻辑上还是有分代概念
物理上是一个一个小格子 整合成一个大的堆内存
G1将Java堆划分为多个大小相等的独立区域(Region)
JVM最多可以有2048个Region
一般Region大小等于堆大小除以2048 比如堆大小为4096M
则Region大小为2M
当然也可以用参数"-XX:G1HeapRegionSize"手动指定
Region大小 但是推荐默认的计算方式
G1保留了年轻代和老年代的概念 但不再是物理隔离了
它们都是(可以不连续)Region的集合
默认年轻代对堆内存的占比是5% 如果堆大小为4096M
那么年轻代占据200MB左右的内存
对应大概是100个Region 可以通过"-XX:G1NewSizePercent"设置
新生代初始占比 在系统运行中 JVM会不停的给年轻代增加更多的Region
但是最多新生代的占比不回超过60% 可以通过"-XX:G1MaxNewSizePercent"调整
年轻代中的Eden和Survivor对应的region也跟之前一样 默认8:1:1
假设年轻代有1000个region eden区对应800个 s0对应100个 s1对应100个
一个region可能之前是年轻代 如果region进行了垃圾回收 之后可能又变成老年代
也就是说region区域功能可能会动态变化
G1垃圾收集器对于对象什么时候转移到老年代跟之前原则一样 唯一不同的是对大对象的处理
G1有专门分配大对象的region叫Humongous区 而不是让大对象直接进入老年代的Region中 在G1中 大对象的判定规则就是一个大对象超过了一个Region大小的50%
比如每个Region是2M 只要一个大对象超过了1M 就会被放入Humongous中
而且一个大对象如果太大 可能会横跨多个Region来存放
Humongous区专门存放短期巨型对象 不用直接进老年代
可以节约老年代空间 避免因为老年代空间不够的GC开销
Full GC的时候除了专门收集年轻代和老年代之外 也会将Humongous区一并回收






.png)

.png)

