 云计算服务
云计算服务
 服务器租用
服务器租用
 DDOS 防护
DDOS 防护
 虚拟主机
虚拟主机
 域名服务
域名服务
 基础设施
基础设施
 关于我们
关于我们
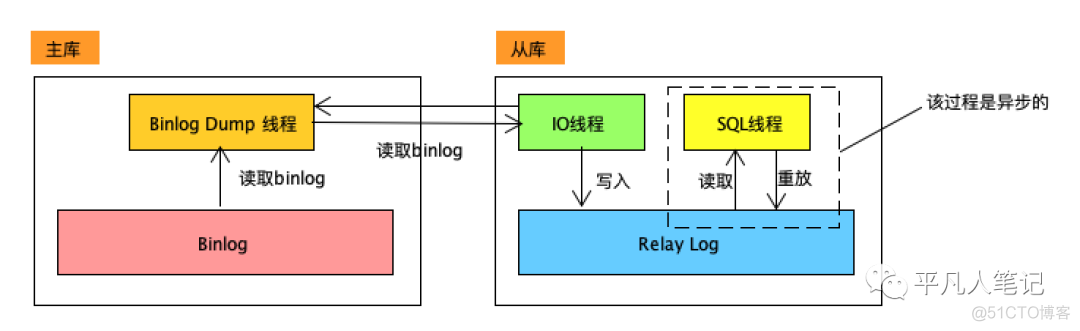
主库开启binlog并正常记录binlog查看binlog
a、从库启动IO线程 跟主库建立客户端连接
b、主库启动binlog dump线程
读取主库上的binlog event发送给从库的IO线程
c、从库的IO线程获取到binlog event之后将其写入从库
的Relay Log中
d、从库启动SQL线程 将Relay中的数据重放
完成从库的数据更新
查看binlog是否开启
show variables like '%log_bin%'
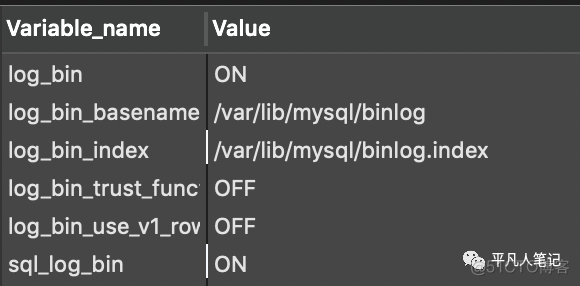

是否开启binloglog_bin_basename
binlog存储文件的完整名称log_bin_index
会默认在文件名后面添加递增的序号
如mysql-bin.000001
binlog索引文件名称
如mysql-bin.index
查看所有的binlog文件
show binary logs
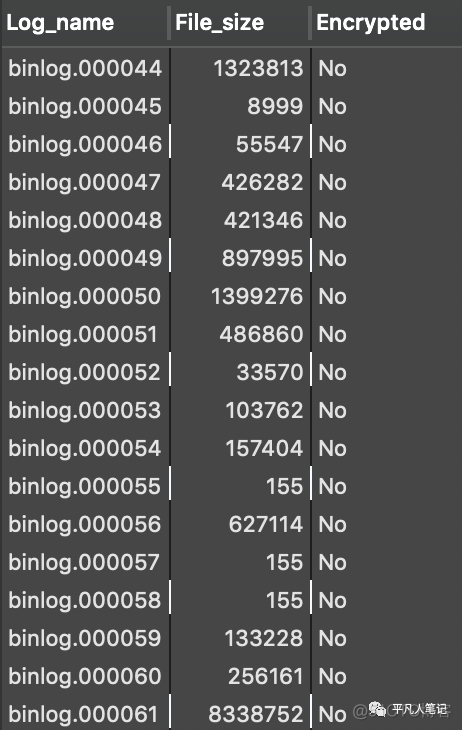
文件名称中的序号越大表示日志越新
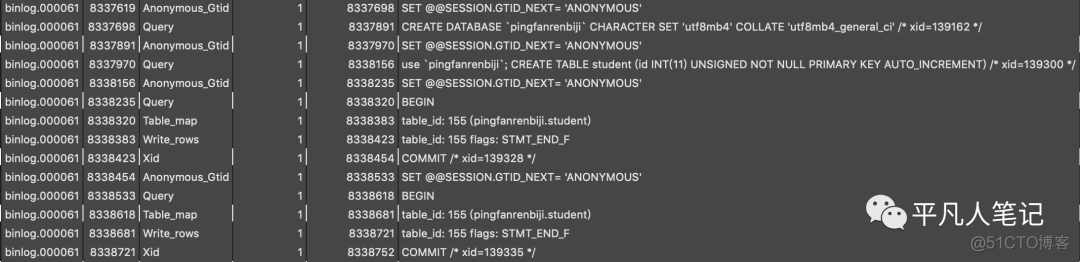
查看指定binlog内容
show binlog events in 'binlog.000061'

第一行 Event_type=Format_desc
内容为 Server ver: 8.0.18, Binlog ver: 4
表示MySQ版本为8.0.18,Binlog版本是V4
执行SQL操作
# 创建库
CREATE DATABASE pingfanrenbiji DEFAULT CHARACTER SET = utf8mb4;
# 创建表
use pingfanrenbiji;
CREATE TABLE student (id INT(11) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT);
# 插入数据
INSERT INTO `student` (`id`) VALUES (1);
INSERT INTO `student` (`id`) VALUES (2);
再次查看binlog
show binlog events in 'binlog.000061' limit 66000,1000
每次插入一条数据都会开启一个事务

MySQL默认采用自动提交(AUTOCOMMIT)机制Relay Log
show variables like '%AUTOCOMMIT%';
引入了Relay Log之后复制模型一主多从
让原本同步的获取事件、重放事件解耦了
两个步骤可以异步的进行
Relay Log充当了缓冲区的作用
Relay Log有一个relay-log.info的文件
用于记录当前复制的进度
下一个事件从什么Pos开始写入
该文件由SQL线程负责更新
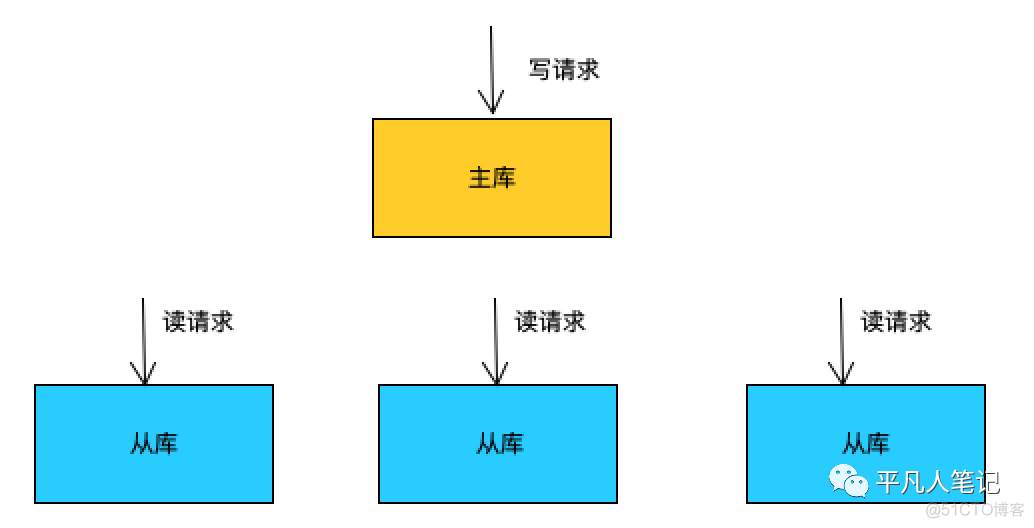
适合少量写、大量读
场景
把从库当成一个灾备库,除了主从复制之外,没有其他任何的请求和数据传输
也可将其中一个备库作为预发环境的数据库
但涉及到生产环境数据库的数据敏感性
缺点
如果有n个从库级联复制
那么主库会有n个binlog dump线程
如果n比较大 可能会造成主库的性能抖动
适合从库较多
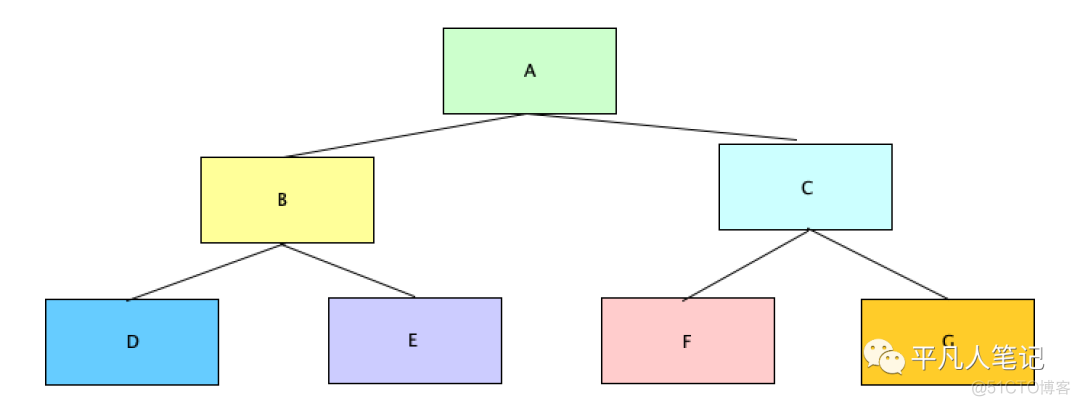
优势
级联复制的好处在于很大程度上减轻了主库的压力
主库只需要关心与其有直接复制关系的从库
剩下的复制则交给从库即可
劣势
由于是这种层层嵌套的关系主主复制
如果在较上层出现了错误
会影响到挂在该服务器下的所有子库
这些错误的影响效果被放大了
双主意义在于HA,而不是负载均衡
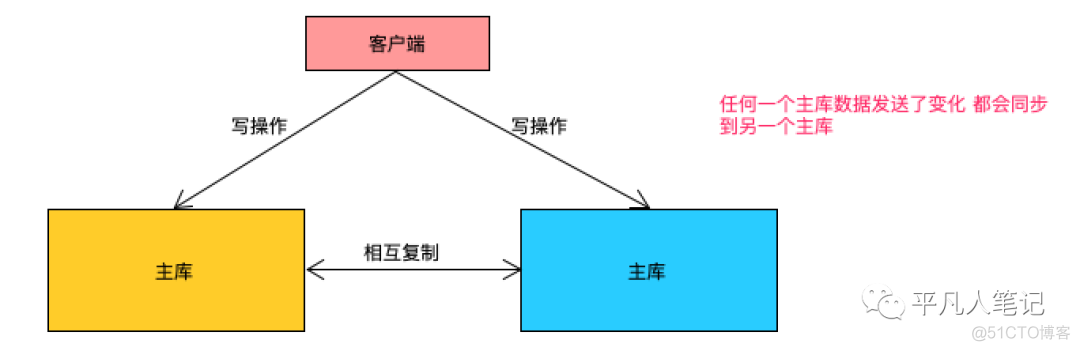
客户端可以任意写2个主库
劣势
两边的数据冲突的可能性很大主、被动的主主复制
例如复制停止了
系统仍然在向两个主库中写入数据
也就是说一部分数据在A
另一部分的数据在B
但是没有相互复制
且数据也不同步了
要修复这部分数据的难度就会变得相当大
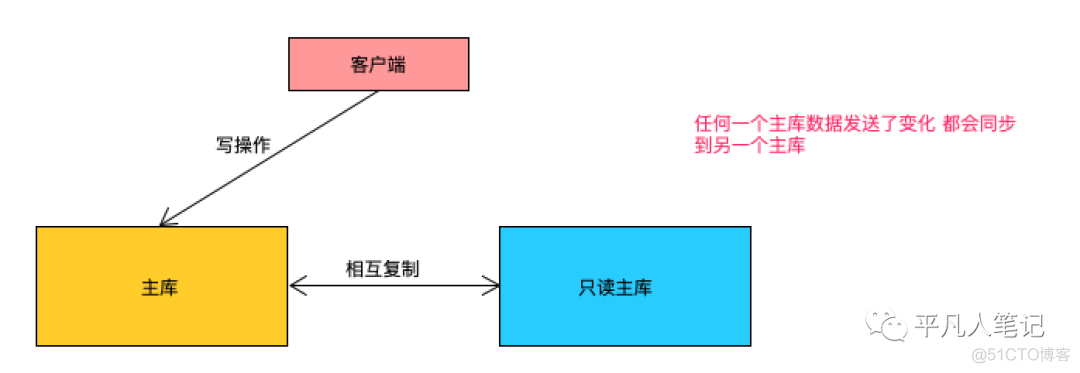
客户端只能写一个主库
另一个主库是只读的
应用场景
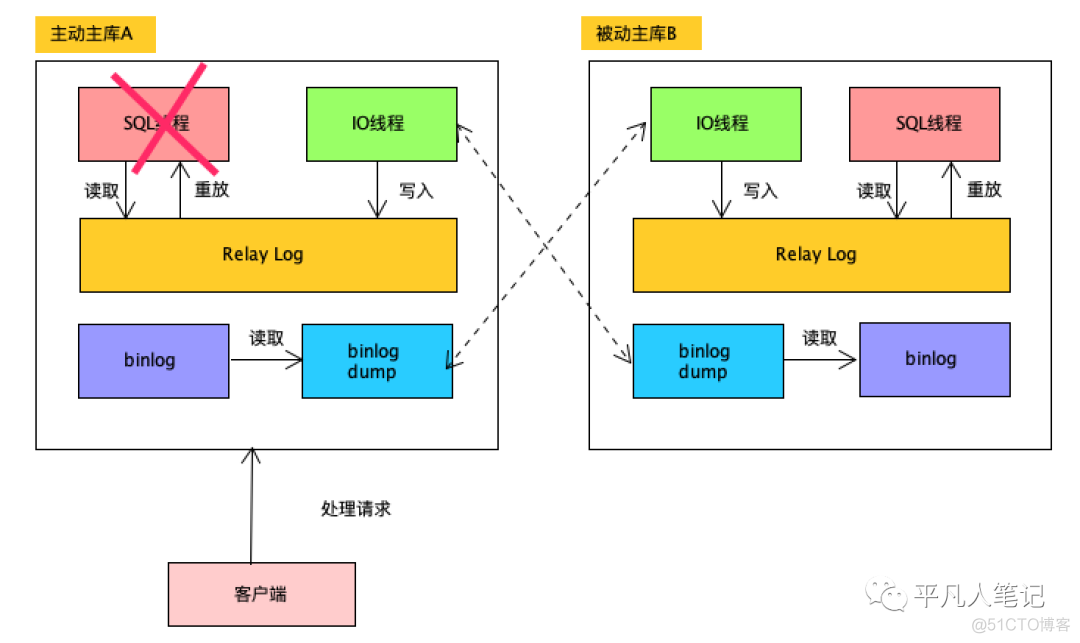
假设2个数据库 主动A库和被动B库
a、先停止A库对b库的复制
也就是停掉A上的SQL线程
b、在B上执行非常耗时、可能需要锁表的操作
就不会立即同步到A上来
此时A正对外提供服务 不能使其受到影响
由于采用的是异步的复制模式
所以Relay Log还是继续由I/O线程写入
只是不去进行重放
在B上执行此次的维护操作
"注意"此时A上面发生的更新还是会正常的同步到B来
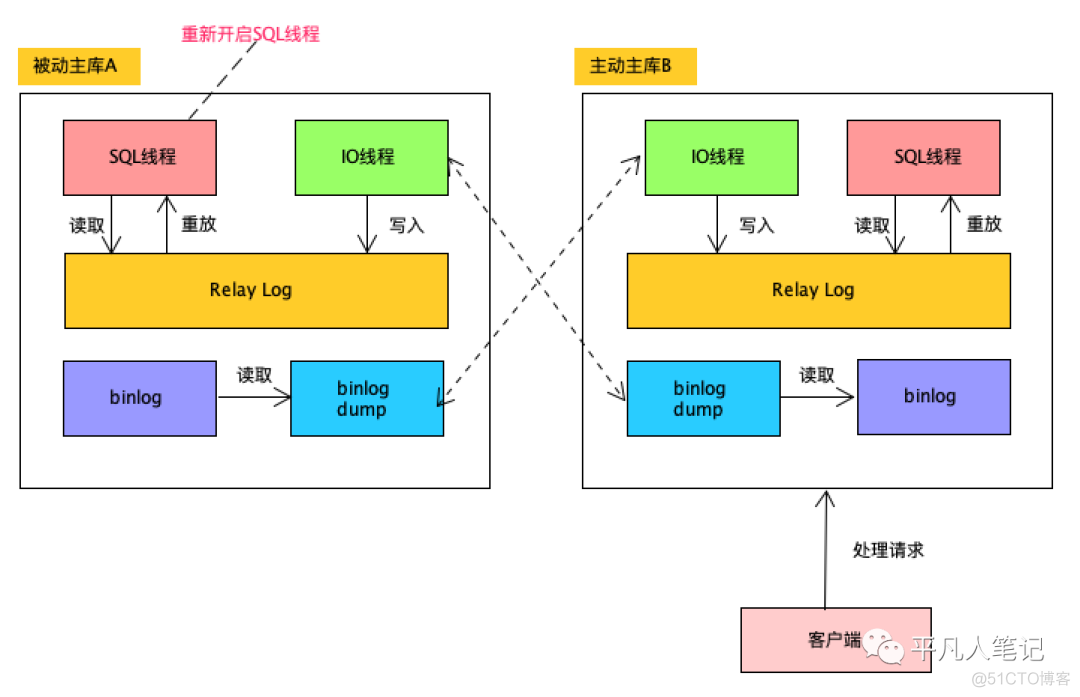
c、
执行完后交换读写的角色
也就是让A变成只读的被动主库
而B变为主动主库对外提供服务
d、重新开启SQL线程
A开始去对之前Relay Log中积累的event进行重放
虽然A此时可能会阻塞住
但是A已经没有对外提供服务了
所以没有问题
优势
可以在不停止服务的情况下去做数据库的结构更新
其次可以在主库发生故障的情况下
快速的切换,保证数据库的HA






.png)

.png)

