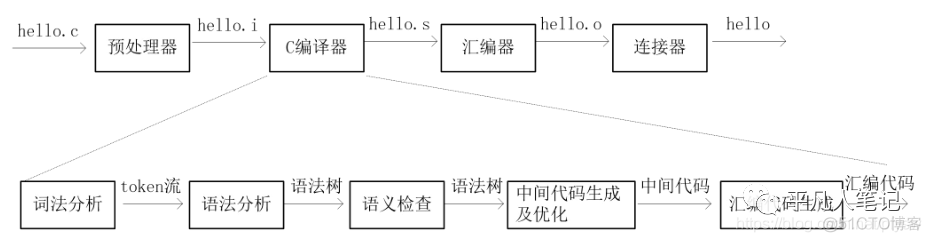
 云计算服务
云计算服务
 服务器租用
服务器租用
 DDOS 防护
DDOS 防护
 虚拟主机
虚拟主机
 域名服务
域名服务
 基础设施
基础设施
 关于我们
关于我们
parser 词法分析含义
将源代码中人类可读但计算机不可读的字符对它做一些基本的分析

告诉计算机这些字符是什么
需要识别的内容关键字
首先识别跟语言相关的关键字
比如 if、else、while
每个语言都有每个语言的特色
包括语言的类型系统 会识别类型关键字
int、char、char*(char封装的指针)
还比如goto关键字
定义的变量、函数
比如 int a变量,int add(int a,int b)函数
字面量
比如 a=3 a如果是整数 那么3就是一个int的字面量或叫number字面量
比如字符串字面量 printf("hello world")
操作符
+-*/(=>{[
停用词
没有意义 实际不需要解析 直接跳过的
比如注释符号、空格、换行
那编译器如何识别上述内容呢?
词法解析里面唯一的方法 tokenize
这个方法会去读源码的字符
这个方法做分词
分词完了之后 输出它是什么类别、在类别中具体的内容
它的返回值叫token和token value
这个方法的返回值类型是void
通过全局变量来定义token和token value
通过修改全局变量来告诉parser的其他部分
读到的源码字符串是什么类别、具体内容是什么
parser接下来就可以做词法分析 比如生成相应的vm指令
如果解析出来的变量或字符 发现是个函数的时候
这个变量或函数 会有一个声明或定义的地方
也会有一个使用的地方
需要保证声明和定义需要在使用之前
在声明和定义的地方就已经可以对这个变量和函数做出很充分的解析
知道它是什么类别 也知道它各种的属性
解析完之后 需要把这些内容存放在一个地方即某个table中
在使用的时候 比如使用add函数 就需要去table中找到这个函数
读出相应的属性 对它做语法的分析和代码的生成
都需要定义过程中解析出来的各种属性
存中间变量的地方是symbol table
使用场景中再遇到这个符号的时候 能读到在声明定义的过程中已经解析好的属性值
symbol table(符号表不属于词法分析而属于语法分析)有哪些内容token
只有在变量和函数的时候才需要使用symbol table
其他情况不需要symbol table 比如乘号*
关键字也需要特殊处理下 因为关键字也可能是很长的字符串
在关键字keyword之外就是变量和函数
所以token分为2类 一类是keyword 一类是id
keyword的token值就是keyword具体的值
如果是程序员自己定义的变量或字符串
把它的token统一定义成id(identitier)
hash
name字符串压缩成的数字
只是为了后续加速查找的过程
直接比较hash值,hash值相同的情况下取name
这是一个优化的实现
如果是用户定义的变量或函数的话
比如add是一个函数function还是变量(局部变量还是全局变量)
如果是关键字的话 也有一种特殊情况 比如是printf(属于system call)
还有可能是number 比如用了枚举 enum {A,B,C} ABC看起来是符号
但实际上它表示的是A是0,B是1,C是2
如果是number或变量的话 value值可能是具体的数值 比如0,1
如果不是number类型或char类型 它可能是指针类型比如430430地址
假设函数中的全局变量装的是字面量 比如hello world
字面量是装在data区的
那么value里面装的就是data区的地址比如230258
如果是一个函数的话 可能是一个函数地址
pc最终会跳转到这个函数地址 比如是code区的地址123123
所以value是什么 取决于class是什么 也取决于type是什么
还有3个属性 Gclass、Gtype、GValue
这就涉及到c语言的feature 局部变量的遮蔽
比如有一个全部变量 char* a
又有一个函数 里面有一个局部变量 int a
那么在解析这段函数的时候 需要知道函数中的a是局部变量a
而不是全局变量 a
char * a //行1
function(){
int a //行2
}
在执行函数之前 已经解析过行1了
a已经有了属性对应的class、type、value了
token、hash、name可能是一样的
但class、type、value属性是不一样的
在解析函数的时候 需要把之前全局解析出来的属性
暂存到G开头的这3个属性中 Gclass、Gtype、Gvalue
在解析局部变量a这个属性值赋值到class、type、vlaue中
等函数全部解析完了,退出这个函数的时候 需要把这个全局遮蔽的全局属性
又得写回至目前它的属性里
函数之外的a还是原来全局的那个a
通过暂存全局属性的方式来实现局部遮蔽的featrue
依照符号表来看下tokenize的代码实现(词法分析最核心的逻辑)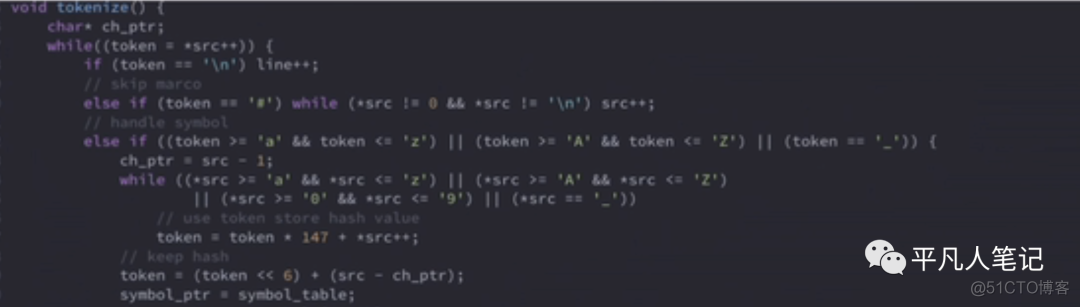
首先从源码中把字符取出来
然后字符指针往后移
src++
如果发现是一个换行符
会把全局变量line++
这个是为了debug用的 没什么实际的含义
就是当debug报错信息的时候 源代码多少行有什么样的语法错误
只要遇到宏就完全忽略
然后就是处理符号identifier
c语言里面是有规定的
由大写字母小写字母下划线和数字组成
以这种字符开头的就知道它是一个符号
处理符号的过程 就会计算它的hash值
因为它已经是个符号了 那么token一定是id
所以先用token来暂存下它的hash值
然后通过while循环读取它的hash值和name
然后就知道了这么一个identifier
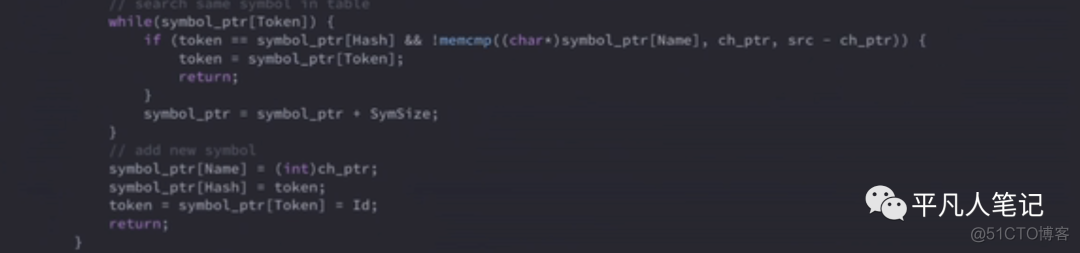
然后去symbol table中暂存的所有的identifier
对比看下 是否是以前已经解析过的
一个个的找 先比较hash再比较名字
如果hash不同就直接跳过了
如果找到了就把找到后的结果直接返回就行了
在真正对代码做parser之前 会把所有的keyword
全部调用一遍tokenize
也就是说在调用parser方法 已经把所有的keyword解析完了
存进了symbol table里面了
所以这个时候遇到了keyword一定能够在symbol table中找到
找到了就直接返回了
如果是一个没有遇到过的用户写的变量或方法
就新增一个符号 这个符号的名字就是它的字符串
它的hash就是刚刚算出来的hash
它的token就是这个id
这个时候为什么不解析它的class、type、value呢
因为这个时候还不知道
比如看到了一个int a
刚读完a
后面无论遇到一个分号还是括号 这个时候已经停下来了
但不知道它到底是个什么
如果是括号 它可能是个函数
如果是个分号的话 那有可能是个变量
这个时候仅仅知道它是a
那a具体是什么呢 这是在语法解析的时候需要关心的
解析完了identifier之后 需要解析num
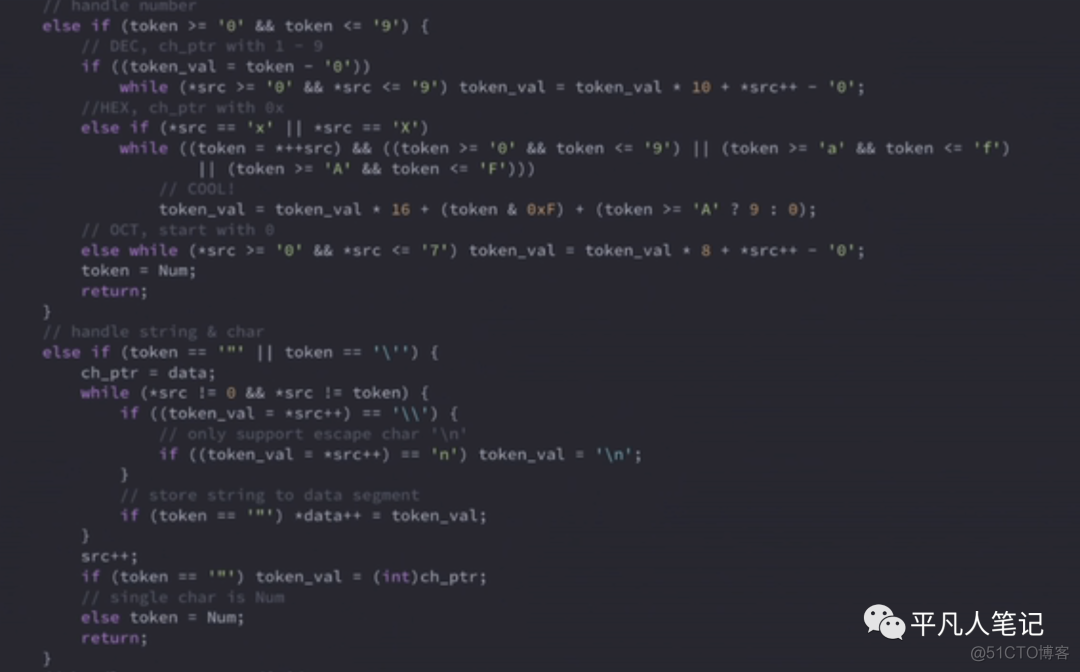
如果它是0-9开头的
那就是一个num
这个num有可能是十进制、十六进制、八进制的
num的值可以直接算出来即token_val
如果是双引号开头或是单引号开头
那它就是一个字符串或字符
如果是字符串的话 就把字符串全部读取出来
存到data区 ,data区开头的地址就是token value
如果是一个字符呢比如A 它的token value就是它本身即A这个字符的ascii码
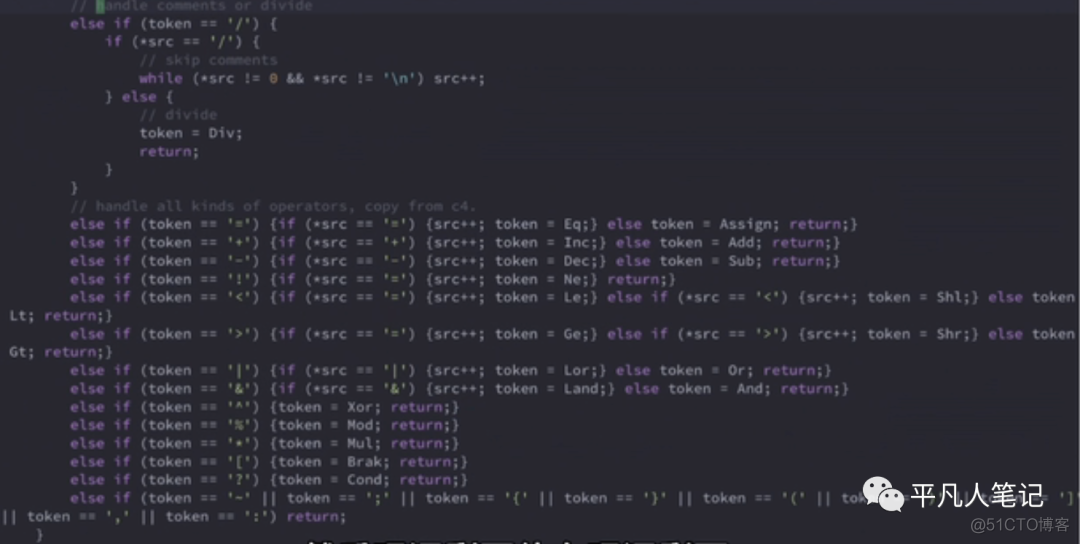
然后还剩下operator
先处理下特殊符号/除号,如果2个除号一起//就是注释符
如果是注释符就把内容忽略掉
再比如++
如果一个+它就是add
如果是连续的两个加
那它就是自增
以上就是词法分析中最核心的逻辑
先从identifier开头
再解析字面量里的数字、string和char
最后解析运算符
举一个简单的例子 来讲解整个词法分析的过程char* a
int add(int a,int b){
int ret;
ret = a+b;
return ret;
}
首先会提前把关键字处理掉 存到symbol table中去
比如这里是char(枚举的变量)、int、return
对应的name就是 "char" "int" "return"
由于这3个关键字不是系统函数
所以这些属性class、type、value是不关心的
然后是真正解析它的内容
首先遇到一个*号
后面在文法分析的时候会发现它是一个指针类型
但在目前的词法分析的时候 直接返回token就是一个*号
然后是空格是忽略的
然后发现一个identifier 小写字母a
后面发现是一个分号 那么这个identifier长度是1
在后面的文法分析的时候 会发现它的class是一个全局变量
它的类型是一个char型的指针
value值还不知道 还没有用到 还未给它赋值
然后再解析int 发现它是一个关键字
然后空格跳过
然后是add 一个新的id
长度是3位 一直到括号才能终结查询的过程
并且add在字符表中没有 所以加入进去
它的class类型是一个函数
返回值是一个int
在边解析的过程中会生成vm指令
所以在解析到add的时候
该生成的code指令都已经在逐步生成过程中了
所以pc就已经移动到了add代码的位置了
后续就是add代码的具体内容了
所以add的函数地址就是生成code的过程中pc的地址
然后解析 又发现一个a
在语法分析里面 可以在符号表中找到一个a了
需要对符号表中的a做个遮蔽
也就是把符号表中的a的class、type、value全部存在Gclass、Gtype、Gvalue中
然后会把目前分析出来的值放入class、type、vlaue中
首先class是一个局部变量
type是int
vlaue还不知道
当解析完这个函数的时候 会把Gclass、Gtype、Gvalue还原回去
然后会找到一个b 它也是identifier
对应的name是 "b"
它也是一个局部变量class
类型也是int
值也是不知道的
ret也是一样的
符号也会正常解析比如;、()但不会进入符号表
在语法分析解析完之后 会得到一个符号表
文法分析与递归下降概念
语法最小单元是单词
每个单词会有不同的形态
比如run ran running
其实它们的词素lexcme是一样的
在分析一门语言的时候
首先要定位到这个语言的词素是什么
然后看这些词素之间是怎么组成一个句子的
一个组织的规则就是语法syntax
有些分词器比如lexer会把词素提取出来
一个句子里面有哪些词素 比如 I am ok
词素有I,am,ok
token和lexcme(词素)区别
int a;
int b;
a和b是两个不同的词素
是同一类别的词素 这一类的词素就叫token
a和int是不同类的词素
这种由程序员自定义的变量名和方法名 叫identifier 简称id
它其实就是一个token 代表好多不同的词素
在syntax词的层面 它们的作用是相同的
所以把它们理解为相同的token
token本身的含义就是代号的意思
在做语法分析的时候真正关心的是token 而不是词素
i++;
这个完全符合语法
意思是让i这个值 自增加1
这个里面有多少种token呢?
i是id,2个加号也是一个token,分号也是一个token
由三种token组成的句子 符合语法
•语义语法背后实际的含义
int i;
i=0;
i++;
这个代码语法没有问题,语义也没有问题,什么情况下语义有问题呢?
float i;
i=2.15;
i++;
这个时候i++就有问题了 不能对浮点数做自增计算
i++只能对int/char/char*(指针)做计算
浮点数指针也是可以的float*
相当于指针地址往后移一位
所以在语义层面i++是错误的
哪怕在语法层面符合规范
•文法 program文法是语法的合集 比如
s=as | bs' s'=a | 空符
|表示或的意思
S表示开始符
这个代码的整体就是S
要解析这段代码就从S开始
后面的每一行叫过程
a和b这些小写字母叫终结符
是不可再生的
可以简单理解为是一个token或词素
解析到它这就停了
文法把语言中所有的语法规则表示清楚了
根据文法表达式可以生成这个语言所有的可能的文本
即这个语言所有的可能的文本都可以通过这个文法解析
C4(c语言的子集)文法
enum {A,B,C};
char * a;
int add(int a,int b){
int ret;
ret=a+b;
return ret;
}
int main(){
int tmp;
tmp=add(3,4);
return 0;
}在语义层面必须要有main方法 但语法层面是无所谓的
根据这段代码来推导下它的文法是怎样的
program= {var decl} | {func decl}
全局变量的声明或函数的声明 也可能是多个
用{}表示一个或多个
这2个是没有带终结符的
如果直接通过这种方式调用的话 会有一些问题
需要用带终结符的定义替换掉 不带终结符的定义
让每一个规则都以终结符开头
这样每一层解析都至少会解析掉一部分的token
剩下的代码会越来越少 这样的话 递归会有一个尽头
上面代码中变量有2种情况 一个是枚举一个是普通的变量的声明
上面代码中没有结构体 没有数组 都是通过指针的方式去实现
var_decl = enum decl|type Id;
这个类型type不管是普通类型还是指针类型
这个是变量所有的可能性
func_decl= type Id(param){ statement }
param=...; statement=...;
所有函数都有返回类型、函数名、参数..
enum decl=enum[Id]{ Id[,Id] }
可能有Id即enum可能有个名字 {}里面可能有一个Id或多个Id
使用递归下降 根据文法解析代码
parse_S(token){
if token == 'a' {
parse_S(token++);
}else if token == 'b' {
parse_S'(token++);
}else{
print(sytax_error);
}
}
parse_S'(token){
if token == 'a' {
succ;
}else if token == 'end of file' {
succ;
}else{
print(sytax_error);
}
}在词法分析的基础上把文法分析出来了
拿到了token 看是否符合S的解析规则
如果符合的话 就逐步解析剩下的部分
剩下的部分也可能是一个S 那就递归的调用这个S的解析方法
去解析剩下的部分
由于每一层解析都至少调了一个终结符
每次都会处理调一个token
那么剩下的token会越来越少
即它的解析是有终点的
如果通过递归下降的方法 去解析一个代码
需要把文法里的每一个规则 都要写一个对应的parse_xx
的函数 把代码逐行解析每一个token 直到EOF
递归下降的文法
program = {global_decl}
program是一个开始符 它的定义是很多个全局定义
global_decl=var_decl | func_decl
全局定义有可能是变量的定义也可能是函数的定义
var_decl = type[* ] Id [','[*] Id]';'|enum
变量的定义可能包含这些;
func_func = type[* ] Id (param_decl) '{' { statement} '}'
param_decl = type[* ] Id [',' type ['*'] Id]
statement = if_stmt | while_stmt | return_stmt | empty_stmt | normal_stmt
normal_stmt = experssion ';'
type = char | Int
Id = ...
experssions = ...
最外层的parse须直接解析到enum或tpye开头的
然后再逐层解析
如果是var_decl就解析变量相关的
如果是func_decl就解析函数相关的
解析func_decl的过程中也需要解析param和statement
statement又需要解析到表达式expressions
递归下降的终点就是解析到表达式
但实际上没有使用递归下降来解析的 因为它的文法比较复杂
所以使用了C4的一个方法 叫优先级爬山
为了在递归下降的过程中解析到表达式停止
需要有一个方法叫 parse_express(){}
当递归下降发现后面是一个表达式的时候
调用parse_express去解析这个表达式
这个函数怎么实现的 递归下降不需要关心的
相当于把表达式当成了终结符
对于递归下降来讲 它遇到终结符就停止了
也相当于遇到表达式就停止了
表达式通过parse_express这个函数单独实现
这个函数使用了优先级爬上的算法
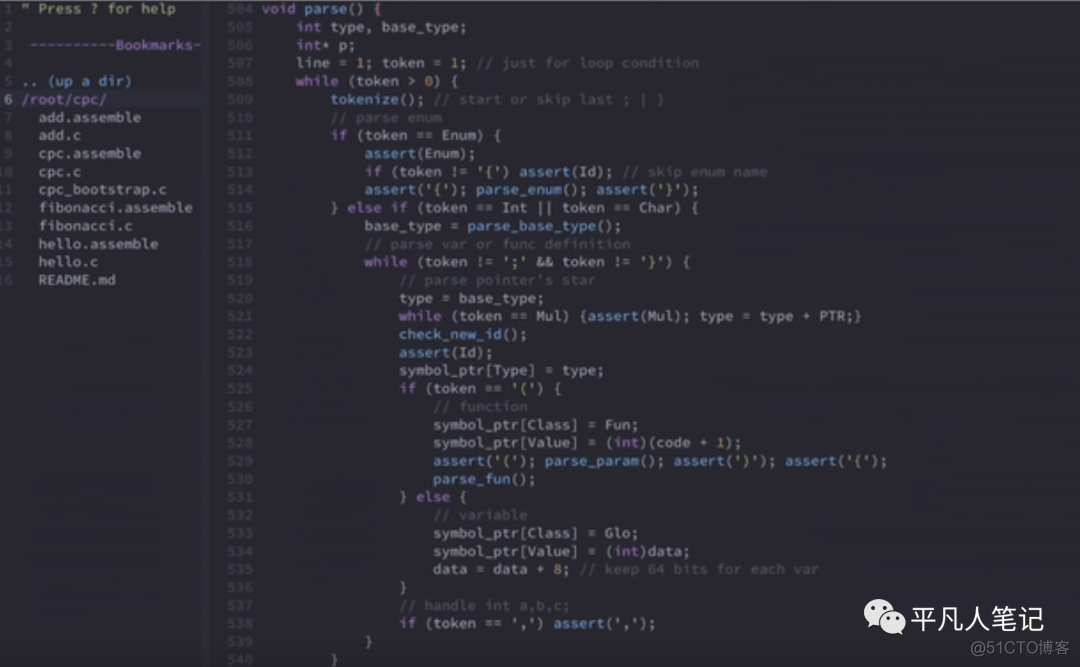
parse整个program
终结符要么是var_decl中的enum、type
要么是func_decl中的type
所以看上图代码
如果是enum的话 它可能有名字的
比如enum myenum{"A","B","C"}
如果没有名字 则接着就是{了
然后使用parse_enum解析A,B,C这些内容
如果不是枚举 那么就是类型开头的 要么是Int要么是Char
要么是指针类型 比如Int* 或 Int**(指针的指针)
这里的代码是先解析最基础的Int和char
先解析获得基础类型
如果token没有遇到;或}
就持续的解析
如果是变量的话 它的终结是;
如果是函数的话 它的终结是}
接着看代码
如果token是*号的话
就把类型转换为指针
如果后面还是* 即有很多个*
因为有可能是指向指针的指针
每多一个指针 就把这个类型多加一个指针的标识符PTR
有多少个PTR就有多少个指针
这样的话 类型就解析完了 可能是int、char、enum指针、指向指针的指针
接着检查token是否是一个identifier
且全局定义 不能重名
所以检查token是一个新的identifier
此时知道了它的名字 但还不知道是个变量还是个函数
如果接下来是一个{ 左括号的话
那么就解析函数
符号表中的class就可以明确定义为Fun
函数的地址就是目前code区的地址+1
然后把左括号处理掉 然后解析参数 然后处理右括号 然后左边大括号
然后就是函数体了
否则就解析这个变量
符号表中的class是全局变量类型
全局变量的value是data区的地址
局部变量的value是在栈的相对地址
地址赋了值之后 得往后移动一位
假设是64的空间 地址移动每次都会加8 即8个byte共64个bit
如果定义中有多个变量的话 比如int * a,b,c
用逗号处理掉
a是一个指向int的指针
b是一个变量
c也是int变量
通过逗号的方式 一层一层去处理
以上就是解析整个代码题program的过程
接着看下解析函数的分支
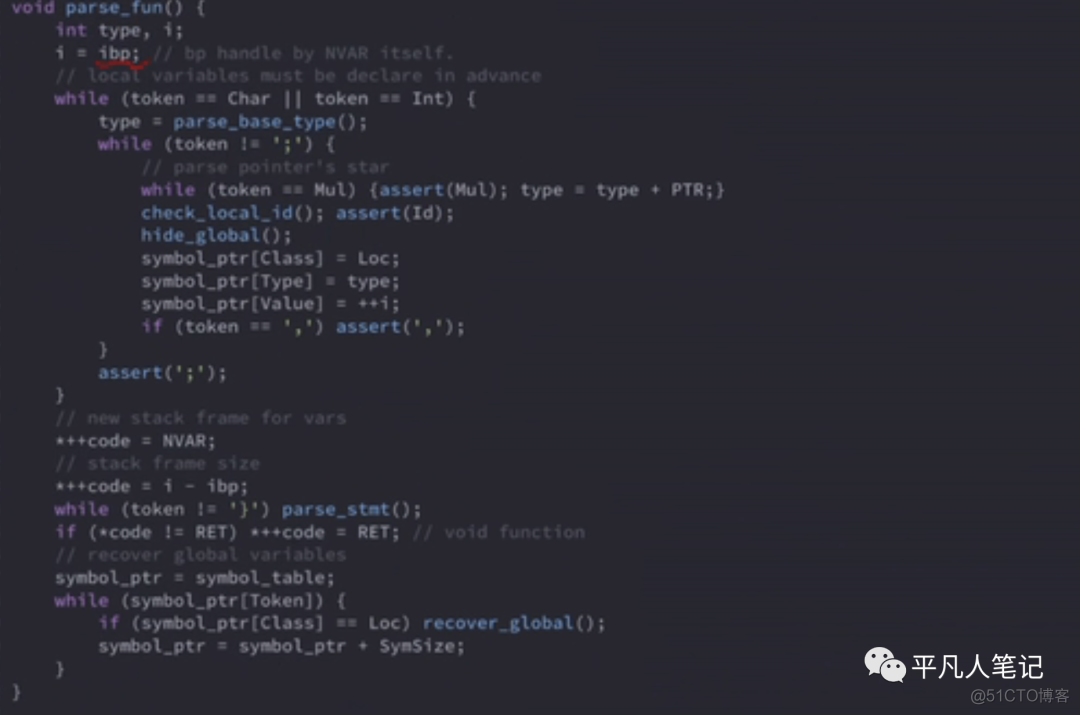
代码中有一个ibp 就是bp基栈的位置
通过ibp这个全局变量来保存它
因为在解析fun的过程中 会相应的生成vm指令
vm指令是根据栈的目前的位置来生成的
ibp就是目前这个函数base point基栈的地址
去解析0个或多个局部变量[local_var_decl]
然后解析代码体 {statement}
局部变量必须在函数的上面 因为是one pass过程
while循环里面是解析base类型 int|char
里面是处理局部变量
如果有同名的全局变量的话 需要hide下
class是局部变量
value是相对于bp的位置
bp的位置是ibp 所以value的值是ibp++
第一个就是bp+1
第二个就是bp+2
解析完了局部变量之后 就需要生成相应的代码了
需要为局部变量new stack frame
i-ibp 就表示有多少个局部变量
相当于是while循环执行的次数
代码区中就会有一个NVAR 2
在遇到}之前 就调用parse_stat函数不断的解析语句
解析完所有语句之后 进行return
但有可能语句本身是一个return语句
那么在语句里面就解析完了
如果这个函数返回是void
没有return语句 需要补充一个return语句
最后把前面遮蔽的全局变量恢复
解析语句的代码
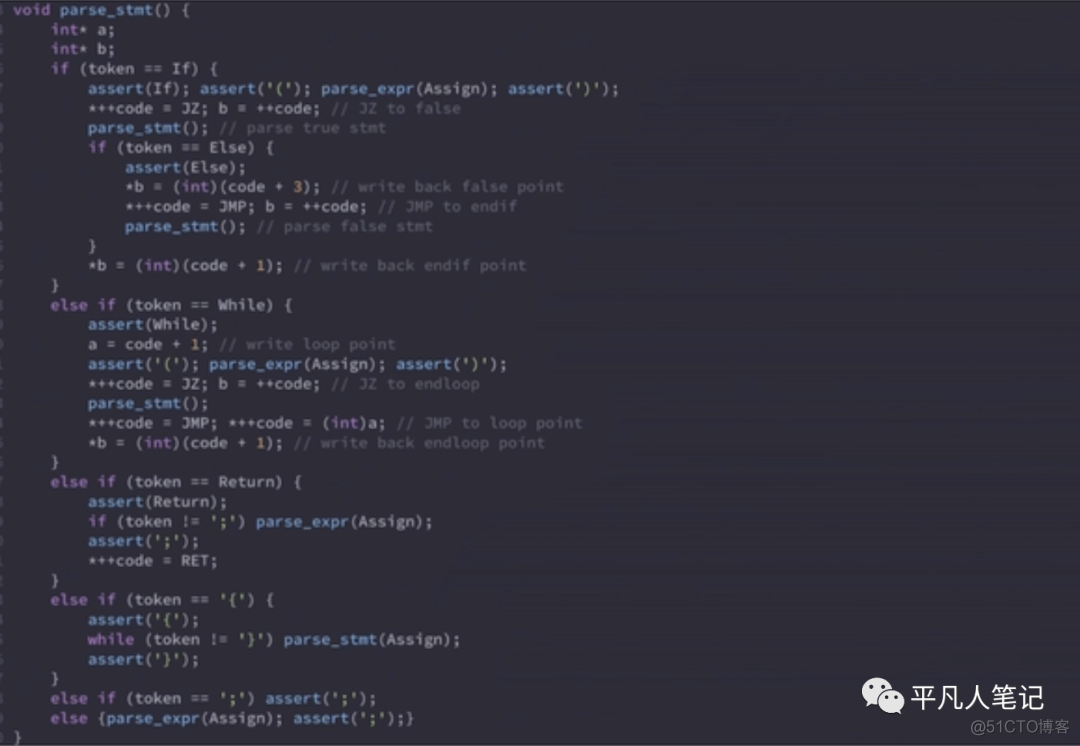
语句一共有6种可能:
if语句、while语句、return语句、{语句、一个分号;的空语句、纯粹的表达式只有个分号(比如a=3这是一个表达式只是不返回任何东西 所以就认为a=3是终结的语句)
表达式求值与优先级爬上•语句(statement)if else;while,return
语句是告诉计算机到底做什么事情
不返回值
•表达式(expression)2+3,4*5
表达式的目的是求值 有返回值
有一种情况很难说是语句还是表达式
a=3 把3赋值给a 即赋值语句
c语言语法:
if (a=3;!=0){
xxx
}else{
xxx
}
这个时候发现a=3其实是返回值了
返回的值是a变量本身的值
3!=0满足条件 会执行else中的代码
a=3这个赋值语句其实是一个赋值表达式 有返回值即a本身
操作符优先级3+4*3-5
在编译器做表达式求值的时候需要知道优先级以及通过优先级来实现求值
操作符分为3种
•一元(优先级最高)1 ++(前置++) --
2 + -
3 ~ !
4 & *
5 ()
前4个优先级是一样的 第5个优先级最高
例如 *++a
对于一元的操作符来说 哪个最贴近符合所修饰的变量
就会先处理它即++先处理 再处理*号
即一元操作符按出现顺序的逆顺序来的
第2个 + - 不是二元中的+ - 而是正负号的意思
比如-++a 先对a进行++ 然后取负号
•二元(优先级次之)1 = 优先级最低
2 ?: || (逻辑运算)
3 | & ^ (位运算)
4 == > < >= <= << >>
5 + -
6 * / %
7 [] 求值 比如a[3] 优先级最高
这7种情况 优先级依次递增
比如赋值表达式(优先级最低)的求值过程
-*&++a++ = xxxxx(比如这个是很复杂的表达式)
先求前面的表达式-*&++a++ 它是一个地址空间
= 赋值符号后面是表达式会求出一个值
地址空间的类型和值的类型需一样
整个表达式的最终结果就是这个地址空间中的值
•三元?:条件操作符 类似简写的if else
优先级爬山算法3+3*4-5
在解析表达式的时候会把遇到的数据和操作符缓存下来
直到遇到的操作符比缓存下来的操作符优先级更低
比如已经缓存了操作符+ *和数据3、3、4
遇到一个-(减号) 这个优先级比*号低
就把目前缓存中的操作符比目前-号更高的即*
拿出来处理掉即 4和3的操作符是*乘号 结果是12
12这个数据又被放入栈中
此时栈中的数据是3和12
符号是+
-和+号的优先级在同一个层级
但-号比+号的优先级更高
所以把-号放入缓存 此时操作符就有了+-
然后把5放入数据栈
此时表达式结束了 就把操作符做出栈处理
12和5 和 - 操作符 出栈 相减是7
此时数据是7和3 操作符是+
再把7、3数出栈 操作符+出栈
最后的结果10在放入栈中
再举一个复杂的例子
++a++=i==0?2+3:45
看优先级爬上算法怎么处理这个表达式
第一个操作符是一元操作符根据顺序的反方向处理
先把*放入操作符栈中
++也是一元操作符也入栈了
第一个num是a变量 放入数据栈中
此时数据栈中是a ,操作符栈中是*和++
假设这个a变量是int *a
a指针
假设i==0
a后面的操作符是++
比缓存即操作符栈中的操作符优先级更低
所以在这操作符入栈之前需要把操作符栈中的优先级更高的
操作符出栈 即操作符栈中的++出栈
数据栈中只有一个a 对于一元操作符来说只需要从数据栈中出一个
所以先处理++a
假设a在内存中的位置是230230
假设地址是8个bytes 64 bit的地址空间
a+1其实就是加8 变成了230238
a的位置从230230变成了230238
此时数据栈中是新地址的a、符号栈中是*
后置++ 比*的优先级还要低
然后把*拿出来(pop)
对a的地址求值
此是操作符栈中就空了
数据栈中就是a这个地址代表的内存空间
然后后置++进入操作符栈
然后遇到赋值操作符=
比操作符栈中的++优先级低
先把操作符栈中已有的优先级更高的操作符出栈
然后对内存地址230231中的值由0变成1
所以此时数据栈是*a这个地址中的值变成了1
然后赋值操作符入栈 此时操作符栈中就只有一个赋值操作符
然后下个是数据i 放入数据栈
然后是相等操作符==
它的优先级比赋值=更高 可以放入操作符栈
接下来数据0放入数据栈
然后是?: 三元操作符
它的优先级比=更低
不能直接入操作符栈
需要先把0和i数据出栈
==操作符出栈 比较
此时结果是true 入数据栈
三元操作符入栈
那此时数据栈中还剩a和true
操作符栈中还剩=和?:
此时true和?:出栈
那么结果是2+3表达式
将2 入数据栈
+优先级比=高 入栈
3入数据栈
此时整个表达式就结束了
把2、3和+出栈计算
将5入栈
此时数据栈还剩5和a
操作符栈是=
把a地址中的值由1变成5
此时数据和操作的缓存栈都是空的
整个表达式求解完了
接下来看代码实际怎么实现的这个过程
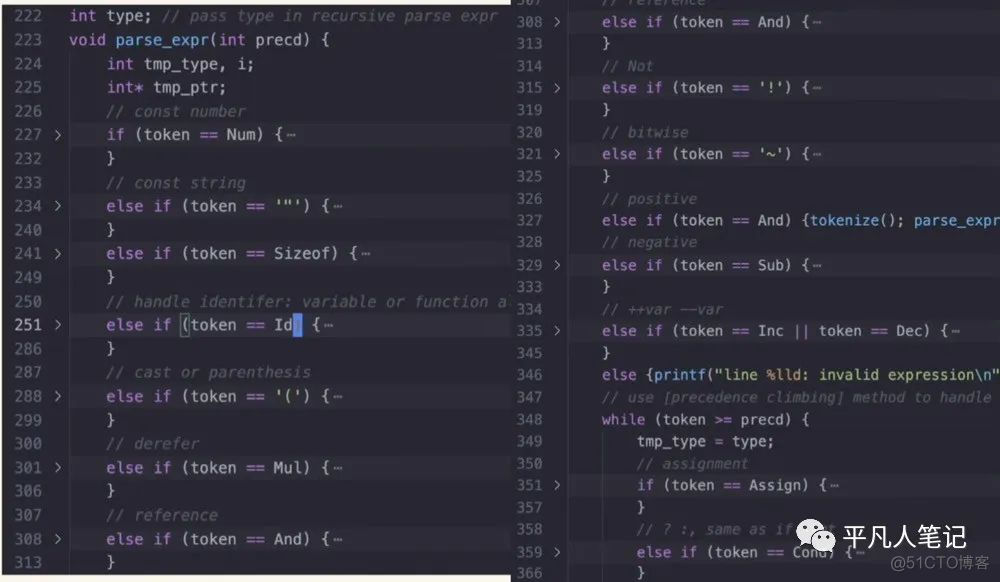
递归调用parse_expr
传入一个优先级即目前操作符栈栈顶的优先级是个数字
先判断是否为一个数据 比如num或字符串
sizeof也是一个数据 返回整数值
或者是identitify 比如变量
或者是函数调用 function call
无论是什么 它返回的是一个数据
然后把数据存在ax寄存器中
如果数据压栈的话 就会压在真正的内存stack空间里面
这样就实现了数据栈 data stack
操作符压栈是通过递归调用的函数栈实现的
处理完数据之后 再处理优先级最高的符号(
然后是*和&和!和~(位的取反)
然后是正号和负号
最后是前置的++和--
以上是一元操作符的处理过程 然后递归的调用该过程
+正号其实什么都不需要做 直接忽略即可
处理完一元操作符就会处理二元操作符即上图while循环
通过优先级爬上的算法来处理
假设遇到的token是比已经在栈上的更大的
新的优先级更大才能进入while循环
否则先把栈里面的操作符先处理掉
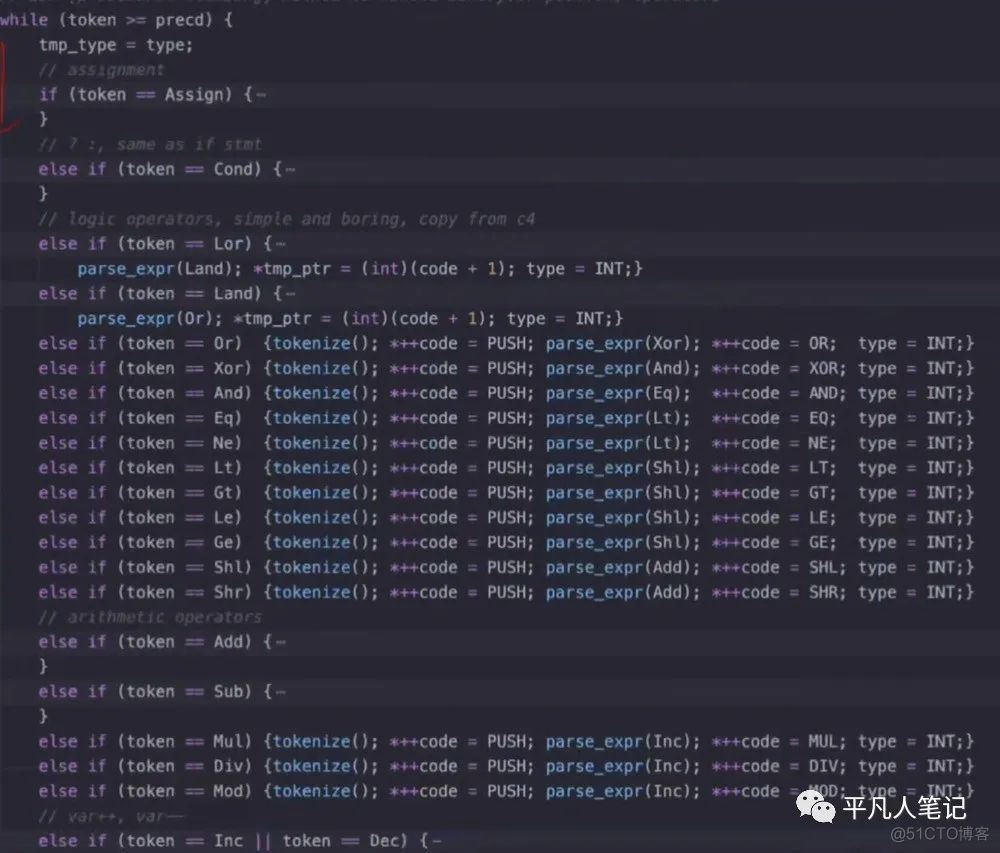
如果新的比操作符栈顶的操作符优先级更高
进入while循环内部 根据二元操作符的顺序来处理具体的内容
假设表达式是a=3+5
一开始是a变量 进入parse_expr
先处理a变量 结果放入ax寄存器
ax是数据栈data statck的栈顶
然后发现是=赋值操作符 入栈
即取a的地址 然后把地址压栈
然后通过调用parse_expr 解析3+5
先处理num 3
ax就变成3了
然后+优先级比赋值符更高 所以进入while循环
while循环里面就会找到+(And)
此时数据栈中是a和3
操作符栈中是=和+
然后是5 入栈 ax即数据栈的栈定为5
此时数据栈中是a和3和5
然后把操作符中的+出栈pop
数据栈中的3和5出栈 调用add命令
然后结果放入ax为8
然后把栈中的地址(比如data区230230)拿出来 把ax中的值存入地址中去
代码生成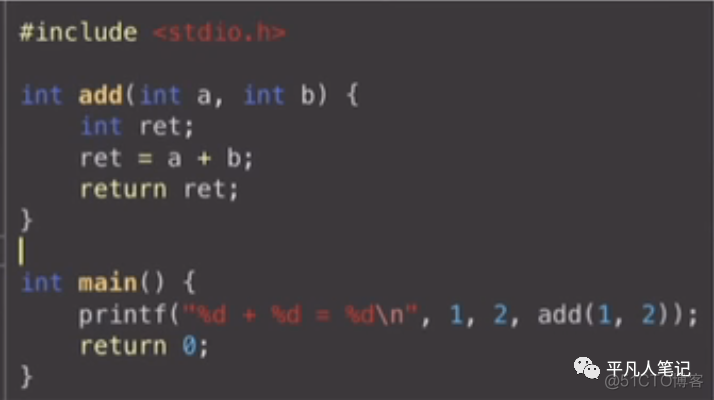
c语言通过各种函数和全局变量组成
通过函数的定义以及函数的调用来理解整个函数代码生成逻辑
main函数涉及到整个程序的入口和出口问题
通过它来理解参数和局部变量是怎么定义和使用的
上面的代码中没有全局变量
定义一个全局变量int global;
在main函数中赋值 global=1;
基于这样的例子来理解代码生成的核心思想:
解析完了源代码
生成了相应的vm指令之后
在正式开始执行代码之前
会得到
1、在code区中有要执行的指令即源代码
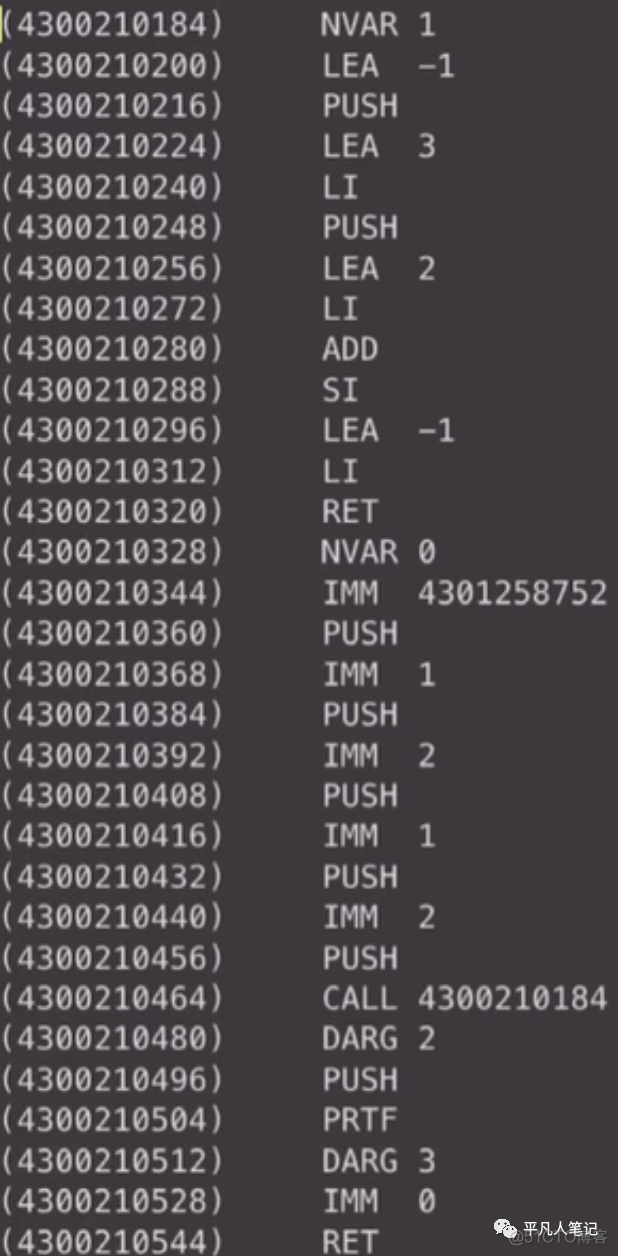
2、还有data区的数据
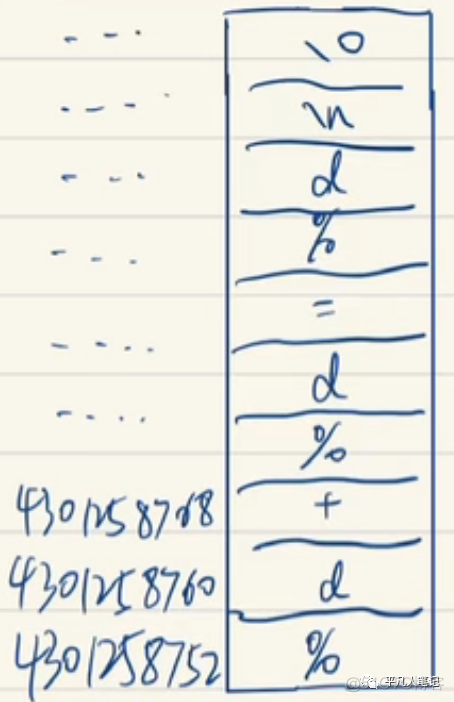
除此之外 其他的都处于初始化的状态即还没有数据的状态
比如stack区和register 这些都是在代码执行之后才开始有数据的

还有一个就是symbol table

symbol table在代码解析(生成)完成之后就没有任何作用了
它的作用在代码的定义和使用这2部分衔接生成的过程
比如int add() 这行代码是add函数的定义
int ret 这行代码已进入add定义的解析的过程
在解析这行的时候就已经完成了parse到gencode的过程
但是在使用add的时候是在第10行
这个时候关于解析需要的中间数据就存放在symbol table中
当把整个代码全部解析完 sybmot就没有用了
代码生成其实就是生成code区和data区这2个区的数据
对应到x86的汇编asm里面的两块区域
一个text 这里面有很多指令 比如mov add
另一个是就是data 里面有全局变量、字面量的内容
这2块区域就对应着code区和data区
想要把c4改造成像x86一样生成text和data文件 然后在加载文件也是可以的 即虚拟机是一块单独的代码 编译器也是一块单独的代码
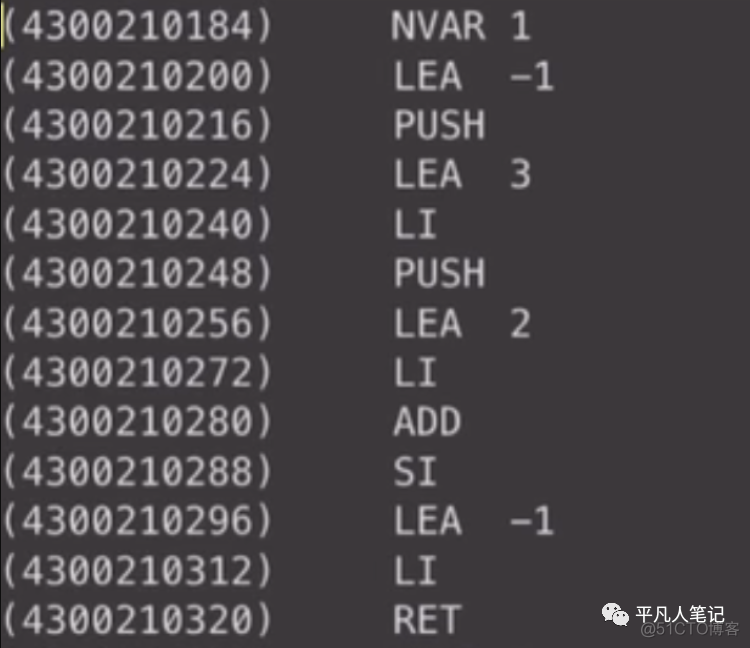
add函数的代码
main函数的代码
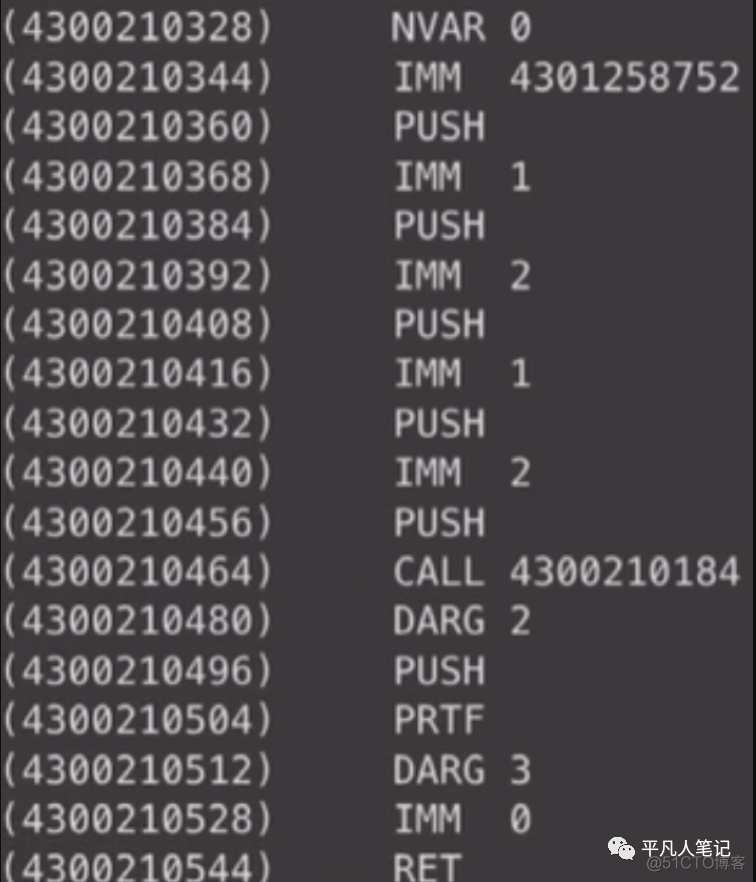
如果有全局变量的定义 也不会对生成的代码区的指令有影响的
变量名叫什么是不重要的 只要在使用的时候能找到定义的变量在data区所对应的地址即可
code区生成的东西其实就是函数定义
函数定义内部其实就是各种语句 各种逻辑
对于代码中的字面量以及全局的变量都会定义在data区
对于局部变量的定义完全是没有任何代码对应的
LEA -1 对应到ret = a+b 左半部分
main函数开始调用add函数的指令是:
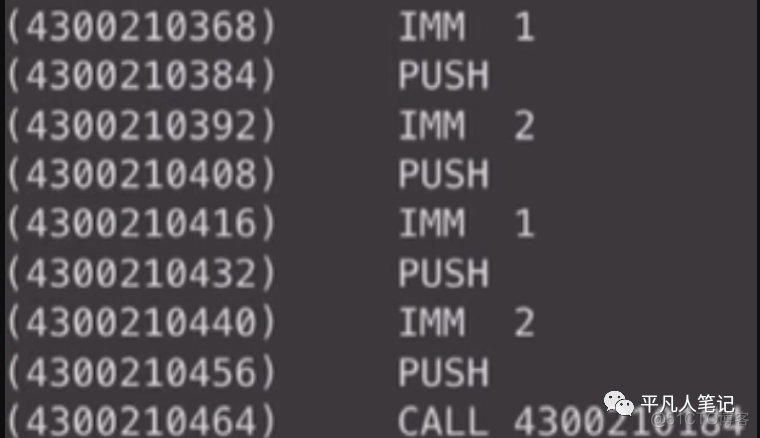
从准备参数开始 第一个参数1 第二个参数2
call add函数对应的地址
解析到add的时候会通过符号表找到对应的地址
就可以精确的生成call add地址这样的指令
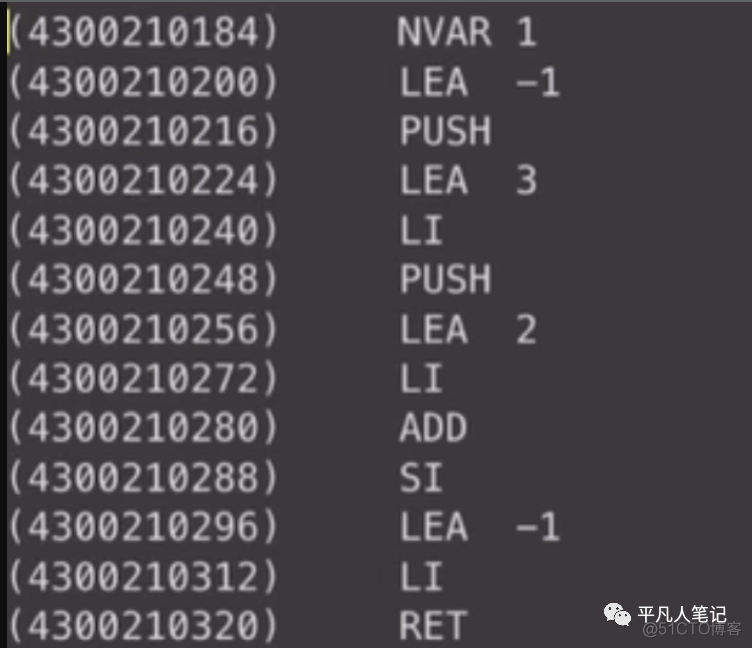
然后看add生成的代码 它其实就是保存ret的地址
因为它是局部变量 保存它跟栈相对的位置
比如是全局变量 比如global
这里就不会用lea了
因为lea是基于bp地址
如果是全局变量的话 可以指定load immediatily一个地址
然后push到栈里面 等待后面去存储
把结果存储到这个地址中去
LEA 3是第一个参数1 把它装到栈里面去
LEA 2是第二个参数2
然后把栈里面的1和ax=2相加
把结果存在目前栈保存的地址中去
这个地址就是前面存起来的ret的地址
相当于现在的结果就在ret里面了
return的时候是返回的第一个局部变量即LEA -1
然后把结果存在ax中
return就是把ax数据返回给了上一层
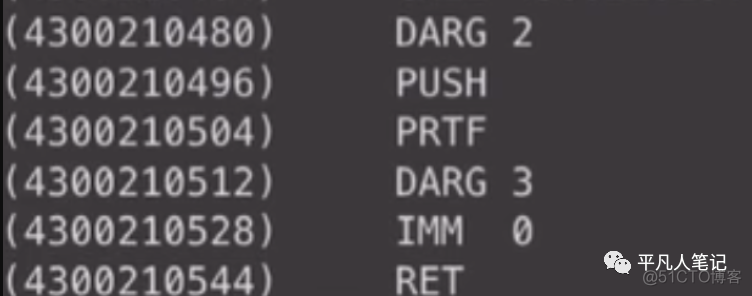
然后回到这里去清理参数
main也是一样的逻辑
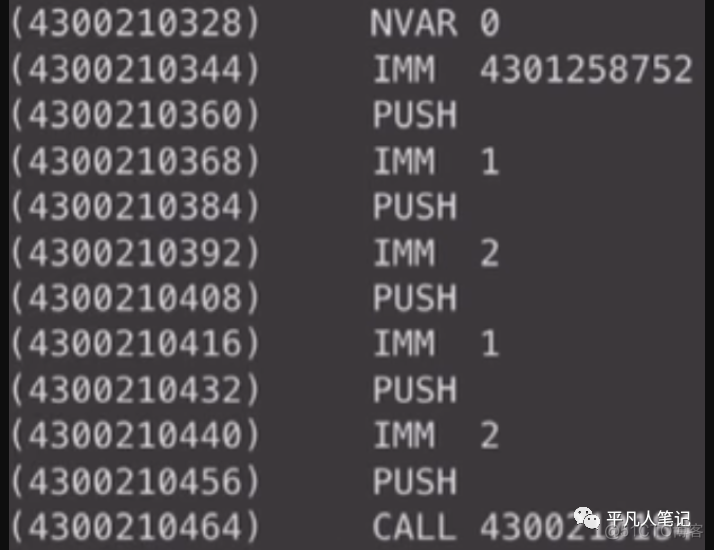
首先会加载一个string(c语言中是char*,char指针 它的数据其实是一个地址)在data区的地址
然后准备printf的参数
然后准备add的参数
然后调用add
这个就是要生成的代码区的所有数据
然后来详细讲一下
定义部分和使用部分代码解析和生成的细节

这个符号表中包含了前面代码中所有会遇到的符号
包含if、else、while关键字
类型关键字 int、char
语句关键字return
native call关键字 比如 printf
然后是代码自定义的关键字
main是在预处理关键字的时候就会把它存储进去
因为要提前记住main在symbol table的地址
回头根据这个地址就可以找到main的函数入口
再开始执行最终生成的代码
接着就是在函数定义、全局变量定义写进symbol table的
比如在解析到add指令的时候 就会把add写入symbol table
如果发现它是一个function 会把目前的地址写入
这个地址其实就是在生成的过程中 code区
所处的指针位置是什么 那么函数地址就是什么
比如code区是空的(0~max) 在解析第一个函数的时候
生成的第一个指令就是要为局部变量生成栈空间
比如有一个局部变量就会生成NVAR 1指令
后续就是这个函数的执行逻辑 一直到ret
这个函数里生成的第一条指令就是就是函数在symbol table中value的值
如果要call这个函数的时候 就是把pc call到这个地址执行NVAR 1指令即可
在函数定义的时候 关键要存储这个函数的初始地址
在使用(call)的时候 只需要找到add这个identity对应的token value地址即可
全局变量在定义的时候留一个地址
那这个地址就是data区为它分配的一个地址
比如解析到int global变量的定义
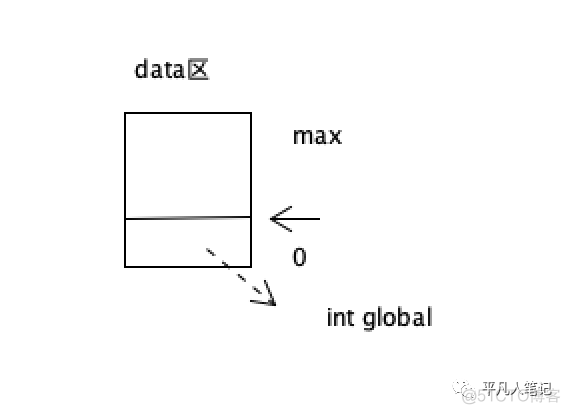
0到pc指针之间就是为global预留的空间
为了能在使用的时候精确找到这个地址 就把它存在symbol table中
在使用的时候 只需要把地址加载到ax里面即可(IMM 430128744)
ax就指向了这个地址空间
如果给这个地址空间存储东西 或者 想调用它的值
都可以通过SI\LI(int)或SC\LC(char)等这些基础的指令根据这个地址对global的变量做一些操作
对局部变量解析的时候 比如add中的ret 也是需要知道它的地址就可以了
地址是相对于它在栈基的位置
使用的时候是以bp为分割点的
bp之前有函数的返回地址和参数定义
bp下面是局部变量的地址 比如ret
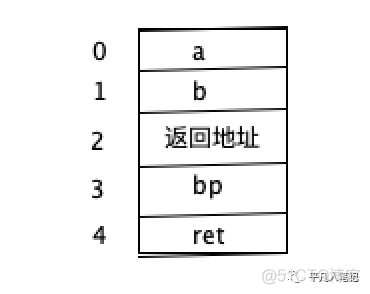
就可以知道每个局部变量在栈中和bp的相对位置
在symbol table中存的就是这样的原生序号
比如参数a存的就是0
参数b存储的是1
使用的是LEA 基于bp位置 ,用bp的位置减去序号
比如第一个参数a 3-0=3
LEA 3就可以调到第一个参数
对于第一个局部变量ret ,3-4=-1 即LEA -1
具体看下如何用代码实现上述定义和使用的过程
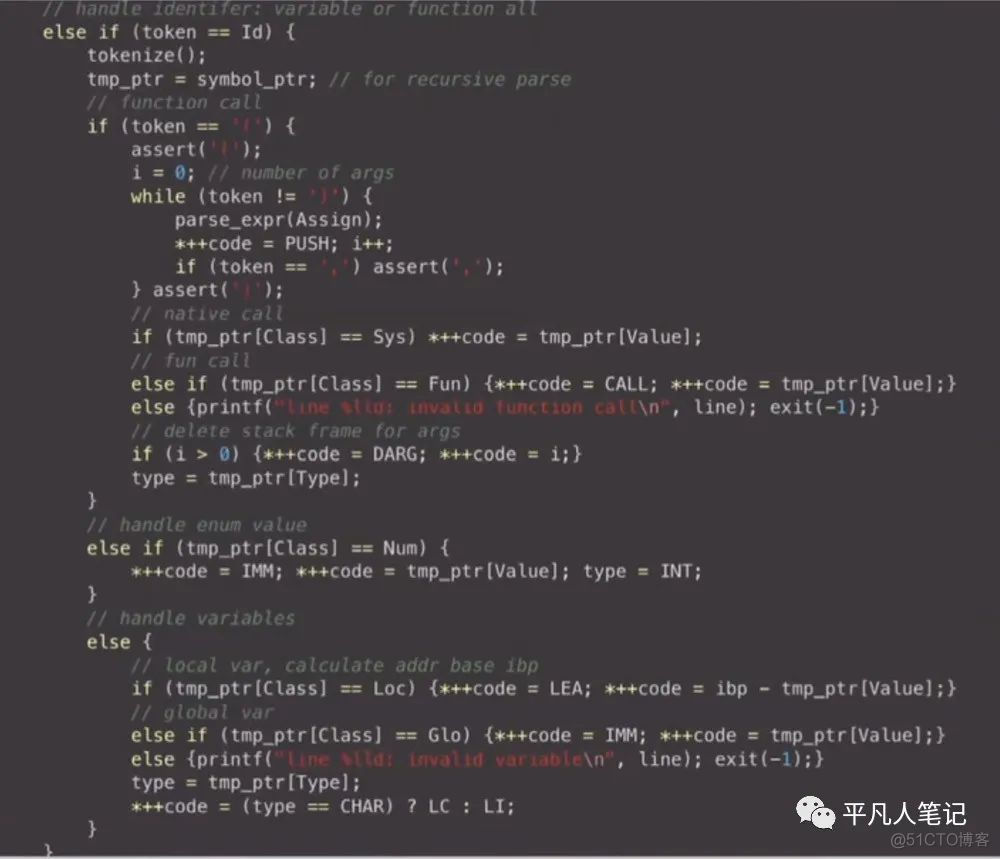
当token为{的时候 那么是函数调用
先处理参数 ,参数也是一个表达式
add(1,2)这种情况参数是字面量
add(add(1,2),2) 这种情况参数又是一个表达式
所以递归调用parse_expr 求表达式值
这个值在ax寄存器中
然后把值push到栈中
准备一个参数列表 有多少个值 就push多少个
while循环之后 就把值push到栈中了
接下来是两种情况
一个是native call 那么就用对应的指令 直接调用
对应的指令就是symbol table中的value
那么就直接生成代码对应的指令就好了
如果是定义的函数function
那么代码区就会call identitfiy对应的token value即function的地址
call里面就会存返回值即call完了之后的地方
然后又会处理bp
处理完之后 pc指针又会回到被调用的地方
调用完之后 就会执行清理的代码
把栈中的参数清理掉即栈里面的1、2就会被清理掉
DARG i ,i是有多少个参数i就是几
如果是num 就会当作一个字面量来处理
字面量生成代码直接是LOAD IMM
就直接加载到ax中去
然后就是处理非枚举变量(局部变量和全局变量)
如果是局部变量就是LEA bp的序号-局部变量的序号
如果是全局变量 就是Load IMM 全局变量的地址
在使用的时候就需要根据类型
如果类型是char 就load char 把char加载进来
如果是整数 就load int
如果是指针 就什么都不用load ,ax里面就应该是它的地址
Load IMM这个地址之后 这个指针里面拿到的就是地址
parse stmt怎么做代码生成的
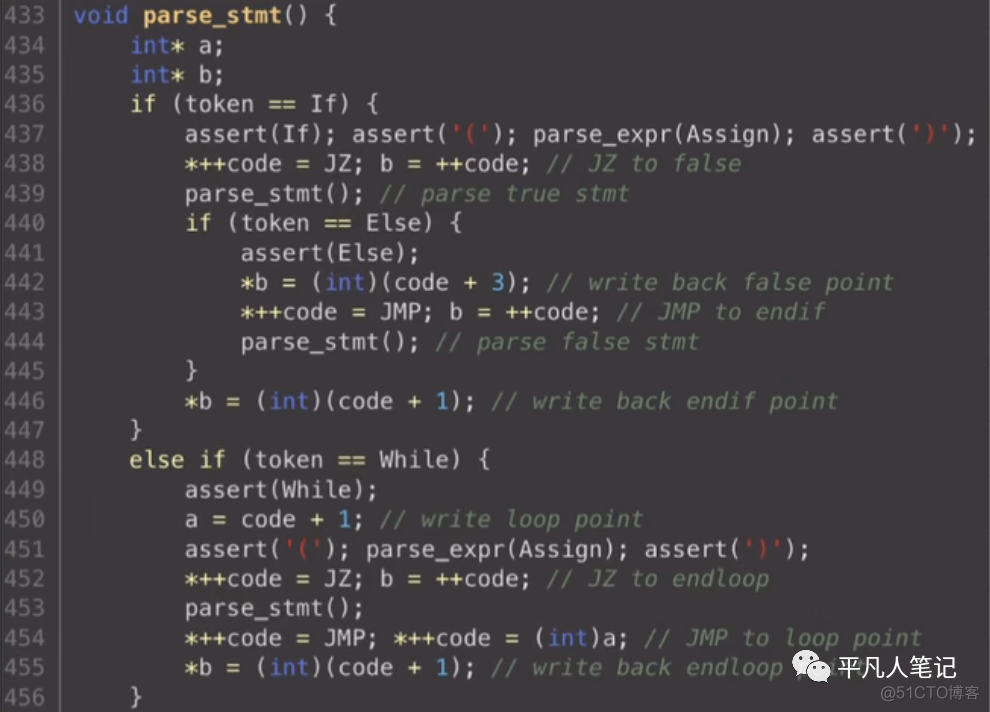
前面说了如何用指令来表示if while逻辑的过程
但是在代码解析的过程中 如何生成对应的指令呢
如果解析的是if语句 if(a<0){}else{}
parer_expr 解析if后面表达式的值 存放在ax中
根据ax中的值 来决定跳转的位置
如果ax是0 则这个表达式是false
如果是false的话 则跳转到else的位置来执行
首先在代码区生成的指令是JZ
第二个就是JZ到false这个点位
但目前还不知道false点位
因为还没有解析if{}中的逻辑
不过没有关系 先用变量b把这个点位存储起来
等后面再确定这个点位 再回写到这个地方先空着
parse_stmt去解析if{}语句快
然后把true相关的指令就全部都执行完了
如果a是大于0的 if(a>0){}else{}
JZ不会跳转 直接执行true的指令
如果true指令执行完了之后 不能接着执行 因为下面就是flase的指令了
需要直接跳转到if结束的地方即JUMP一个位置
这个位置是哪个 还不知道 因为false还没有解析
还是要把要JUMP的地方先空出来 存一个变量c
空出来之后 就进入了false的解析地址了
就知道了fasle的点位在哪里 就是JUMP之后的地方
这个就是false语句开始的地方
所以这是时候把code的位置存回变量b
假设这个位置是430430 那么JUMP b就是JUMP 430430
然后开始解析false的statement
false解析完之后 就是代码退出的地方
退出的地方假设是430450
那么这个位置就是true statement直接JUMP的位置
这个时候就会这个end if的点位存回变量c
以上就是if的parse和codegen的过程
if之后再说下while
while(a>0){}
在判断了while token之后
先把这个时候 code区的点位存储下来 存到变量a中
为什么需要存储这个 因为循环没有结束的话 需要跳转回来
所以code区的最后一个指令肯定是一个JUMP a的位置
这样才能有一个循环
然后开始解析while里面表达式的值
每次都要parse 因为a每次都在不断的变化 否则就while死循环了
解析表达式的值存ax
如果这个时候ax的值为0了
while就结束了 需要跳转出while循环
即JZ end while 那个点位 但目前还不知道
先存在变量b中
while里面的语句块也是通过同样的方式 parse_stmt解析
最后JUMP a的位置
假设是430430
JUMP完之后code的位置假设是430450
然后把430450回写到变量b
以上就是关键语句的解析
最后是表达式求值的代码生成过程
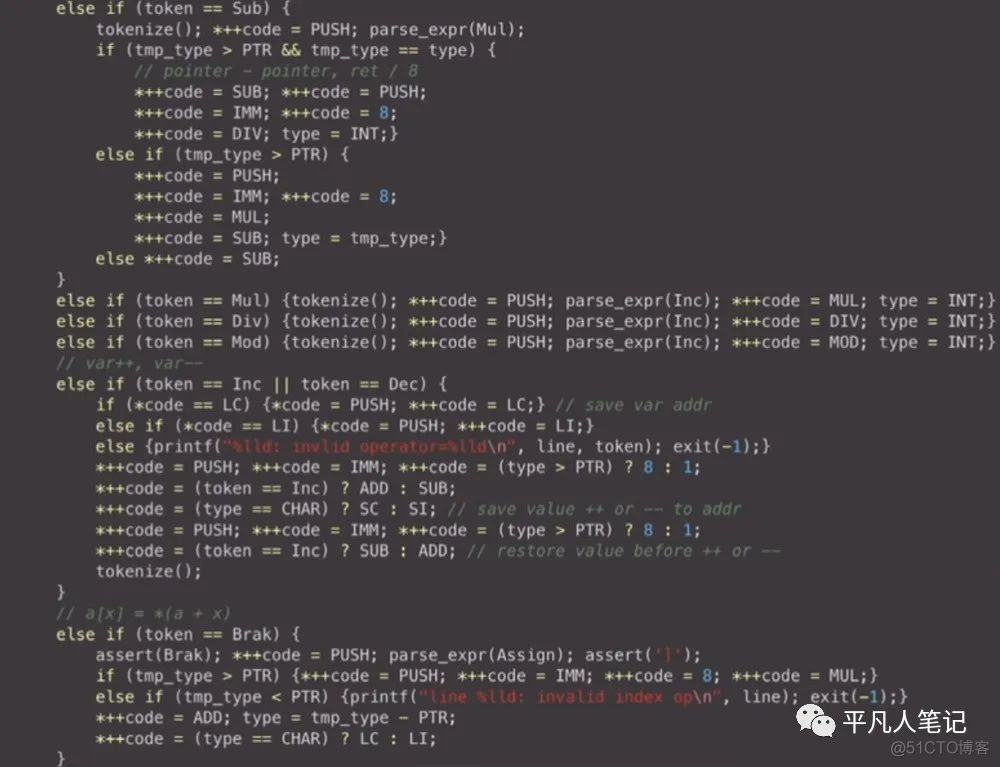
首先看下减法 a-b的形式
因为已经解析到-减法这个符号了
-前面的已经解析好了并且在ax里面了
在解析的过程中是这么个顺序
然后把减号忽略掉
然后把ax中的值push到栈里面
假设a的值是5 把5push到栈中
然后去解析第二个参数
第二个参数也是一个表达式 不管是单独的变量还是字面量或者是函数调用返回的结果
解析这个表达式
如果解析的表达式它的优先级大于或等于乘号
假设是a-b*5
先把b*5解析完了 然后再做减法
根据优先级爬山算法
首位的符号是乘号
b的值在ax中 假设是3
那么在生成的代码中除了刚刚的那个push之外
然后就是解析-减号后面的代码
解析完了 然后相减
这里有一些跟类型系统相关的一些逻辑
包括后面的++和{}都有这样的问题
如果说是两个指针相减 point-point
相当于求2个指针地址的相对位置
由于地址是8个byte 64位的
求出相减之后的结果需要除以8
假设地址相差2位 相减结果就相差16个byte
把ax=16 push到栈中
这个时候把栈中的16除以8
ax=2
2就是a-b的结果
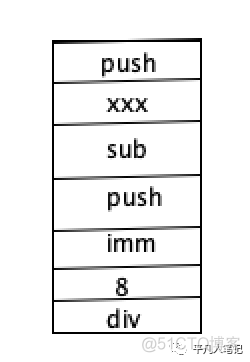
如果指针减一个正常的整数呢
即需要指针往后挪几位
挪的这个位数最终在地址值中相应的乘以8
比如指针的值是430430
加1位 下一位的地址是430438
真正加之前需要把加的值乘以8
这个就是指针加减比如字面量的过程
两个正常的整数相减 直接sub一下就完了
把第一个参数push到栈中
第二个参数b在ax中了
然后直接sub
就可以得到ax结果了
后置的加加相当于目前ax里面的值加1
加完1之后再存回ax中去
中括号[]左边的值一定是一个地址
比如a[3]相当于这个地址加3之后
再给它求值 *(a+3)
对指针做一个相应的加
加完之后再把值load进来
最后看下cpc源码的main函数
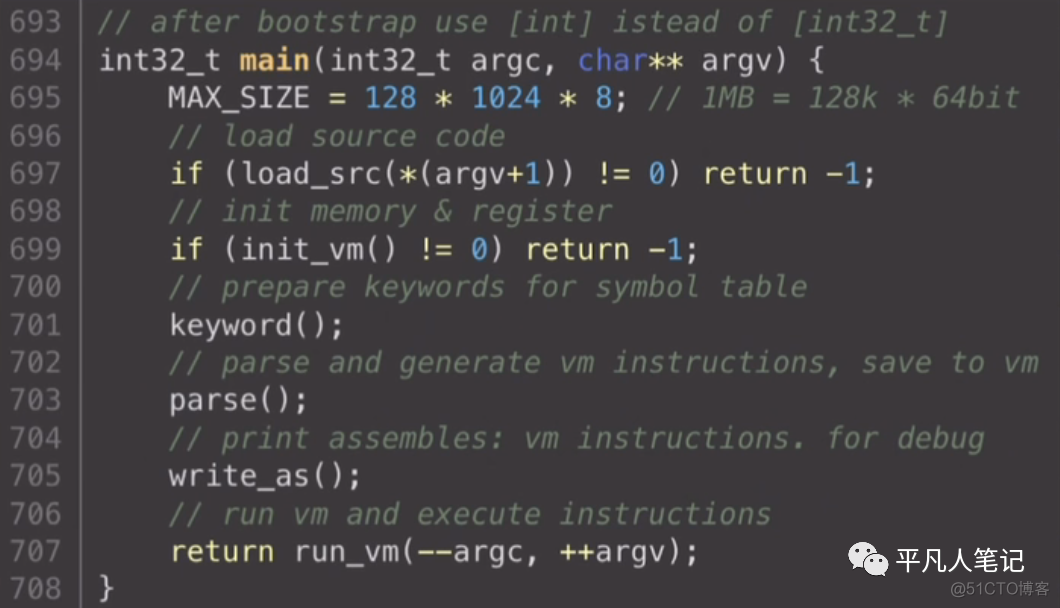
看下编译器主干逻辑
首先需要加载所需要编译的源码
比如cpc hello.c
然后把虚拟机做初始化 主要是内存和寄存器
该申请内存的申请内存
该设置为0的设置为0
然后准备cpu这个语言所需要的所有的关键字
这里面包含了main
然后就是parse方法
这里面会处理全局定义
包括变量和函数
变量就直接处理了
函数会调用两个子函数 一个是parse_params 参数列表
另一个是parse_function函数体
parse_function会调用一个很关键的parse_statement
处理各种功能语句
语句里面调用parse_expr做表达式求值
这个就是整个parse和codegen的过程
在这样的一个调用链中完成的
调用parse函数完成之后 就生成了code区所有指令
以及data区的所有的全局变量也好各种字面量也好
write_as把code区的所有指令输出
最后执行code区的所有指令
然后看下怎么找到main函数的入口
因为main入口并不是在code区0的位置
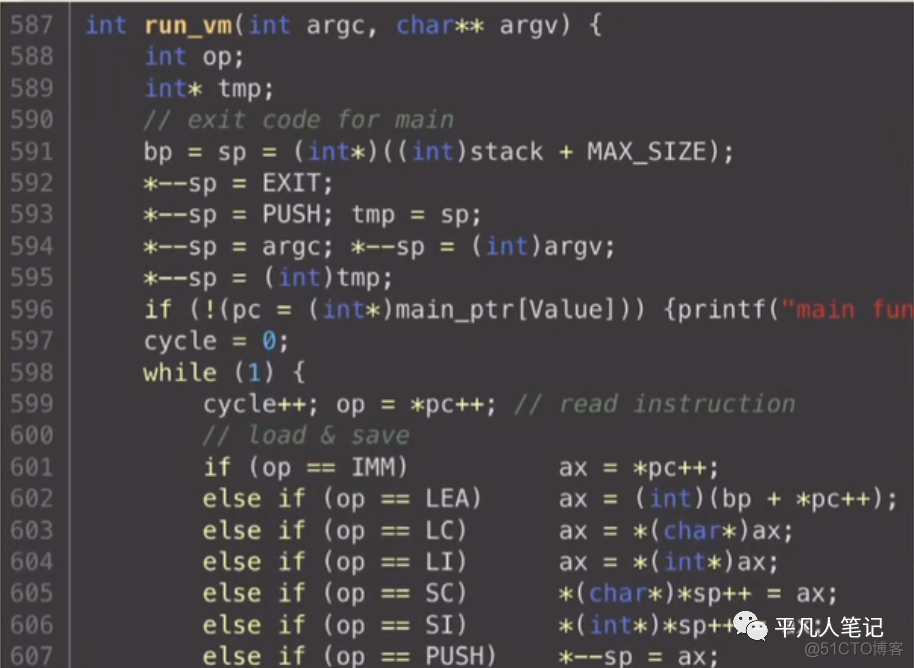
在做keyword解析的时候会拿到main在symbol table的指针
它的value就是main在code区的地址
pc先指向这个位置 后续执行的时候就是从main的入口位置开始执行的
main的参数怎么传进来的呢
cpc hello.c xx xx xx
cpc编译器源码第一个参数之后的位置就是所编译代码的main参数
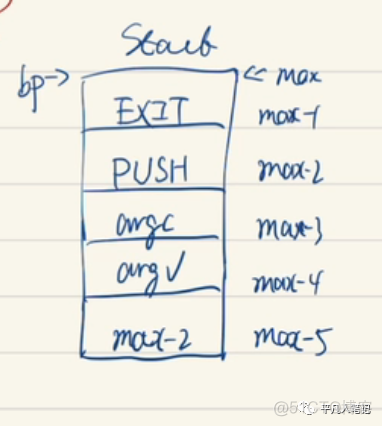
返回值是stack区max-2的位置
return了之后 pc就会修改成这个地址
这个地址按理说是一个地址 但它实际上是一个push指令
那么就会执行push即把ax push到stack中
最终调用exit命令
exit命令就是把栈里面的值当作exit的参数退出
整个程序就是这么退出的
所以在栈的最开始初始的时候
存入exit、push、main参数、main的返回地址
再接着就是main的函数栈
当main的函数栈结束之后就可以退出代码了
现在就知道了整个函数的入口和出口
整个过程就是把pc指令拿出来
然后跟着指令是什么做对应的操作
pc是不断的++的
如果有JMP pc也会有一些跳转
这个就是代码生成之后运行的主干逻辑
结尾最近三篇文章介绍了:
C语言编译器概要设计思路一
虚拟机指令集&栈与函数调用
从最开始的虚拟机指令集以及函数调用的实现逻辑
到parse逻辑(词法分析、语法分析、表达式求值)
最后是代码生成核心的思想和逻辑






.png)

.png)

