 云计算服务
云计算服务
 服务器租用
服务器租用
 DDOS 防护
DDOS 防护
 虚拟主机
虚拟主机
 域名服务
域名服务
 基础设施
基础设施
 关于我们
关于我们
简介
海量数据分析并不一定要用elasticsearch,但搜索一定要用elasticsearch。elasticsearch是基于文档型的数据结构。
百度是全文搜索引擎,搜索的内容不是固定的;京东淘宝是垂直搜索,有明确的搜索目的,站内搜索是垂直领域的一种。

搜索引擎包括NLP(自然语言分析处理)、大数据处理、网页处理、爬虫、算法、elasticsearch。
elasticsearch除了搜索之外,还可以做大数据分析,ELK就是使用的elasticsearch大数据分析功能。
搜索框架技术选型
redis不适合做大数据搜索和存储,它是一个内存型数据库。如果开启持久化,性能会下降。
•mongodbmongodb适合做大数据存储,可以做搜索引擎,但更适合对数据的管理,不适合做检索。
•eses更倾向于搜索。数据写入的实时性并不高。es不支持事务。es和mongodb都是基于文档型数据库。
•solr搜索这块,可以和es相比较的是solr,两者都是基于lucene。lucene是单点的。solr是技术比较老的框架。es稳定性不会随着数据量的增大而发生明显的改变,es天生就支持分布式的,solr不一样,并不是天生就支持分布式,需要自己去管理分布式集群,还要使用第三方中间件zookeeper管理集群状态。es也支持数据迁移,比如从solr迁移到es。
为什么mysql索引结构不适合做搜素引擎
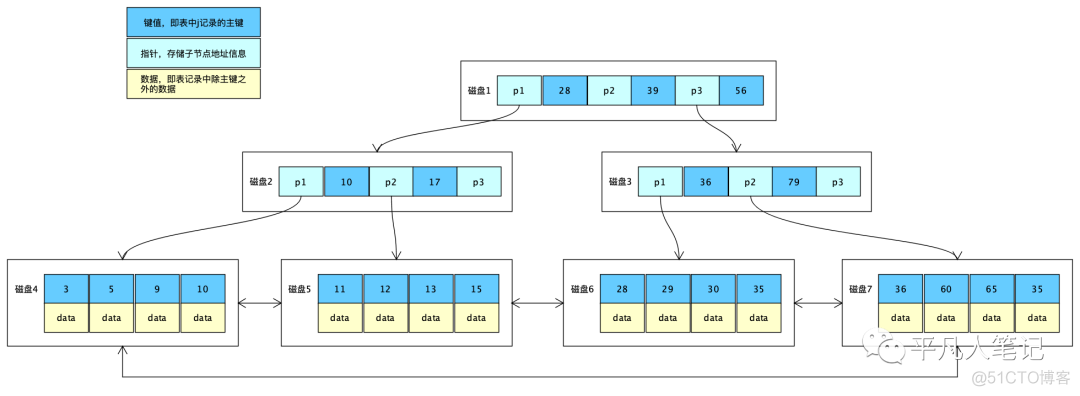
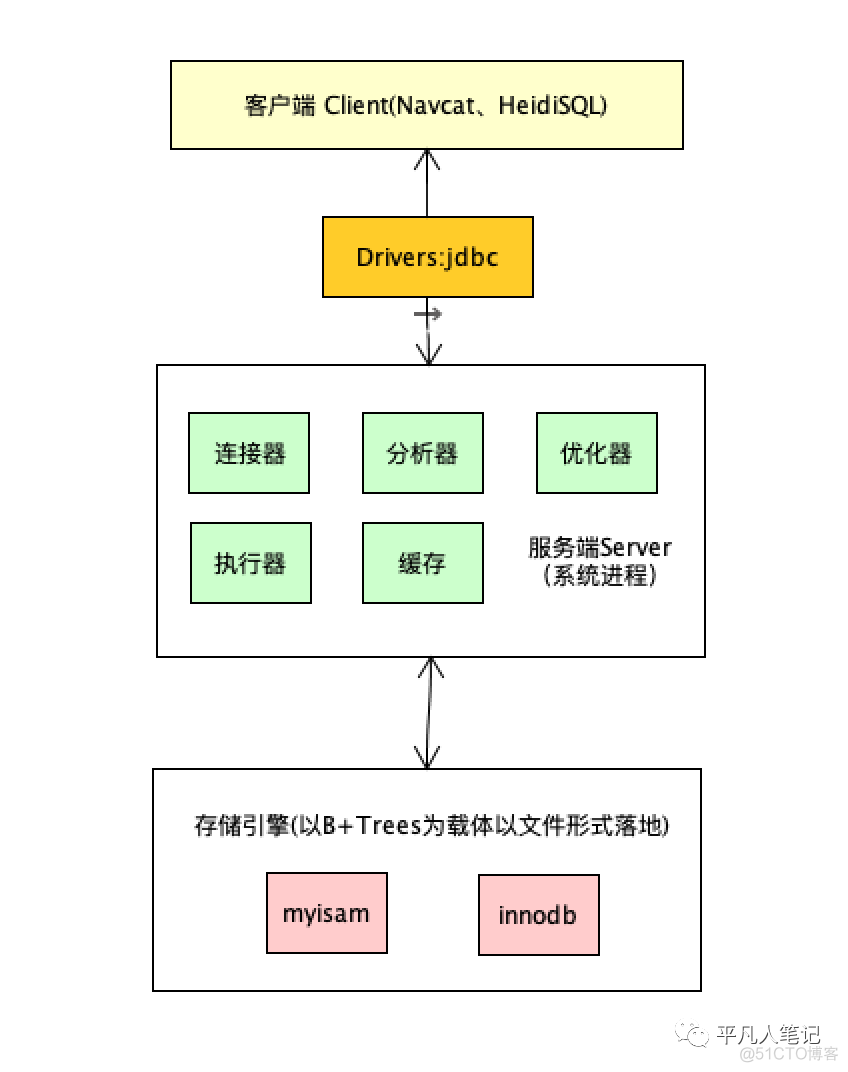 数据库组成结构
数据库组成结构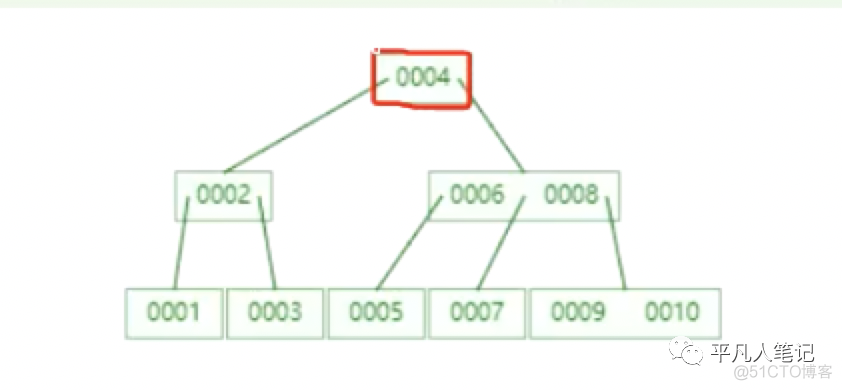 图1
图1
在mysql中这样的一个节点大小是固定的,节点就是寻址最小的数据单元即data page,默认大小是16KB。
假设这是一个磁盘,磁盘由很多节点数据单元组成,每个节点包含键值、指针和数据。
磁盘和内存之间数据交互的时候,一次性最小取这么一个单位的数据。
在图[1]中查找id=7的数据,需要做几次io操作?
首先把跟节点16KB放入内存中(在创建索引树的时候就会把根节点放入内存,这里先忽略这点),经过一次io,cpu判断id=7的数据不在这个节点里,根据当前004这个节点去磁盘中寻址,找到006~008这个节点,然后从磁盘加载到内存,这是第二次io操作,cpu判断得知数据在007节点,然后再寻址找到007节点,加载数据到内存,然后读取里面的数据,这是第三次io操作,那么该过程内存和磁盘之间一共产生了3次交互,计算结果就是16KB*3=48KB。
任何小的数据一旦用户量过大的时候都是不可以忽略的,所以要尽量减少磁盘io的次数。
树的深度不断增大的时候就意味着磁盘io的次数不断的增大。
B-Trees
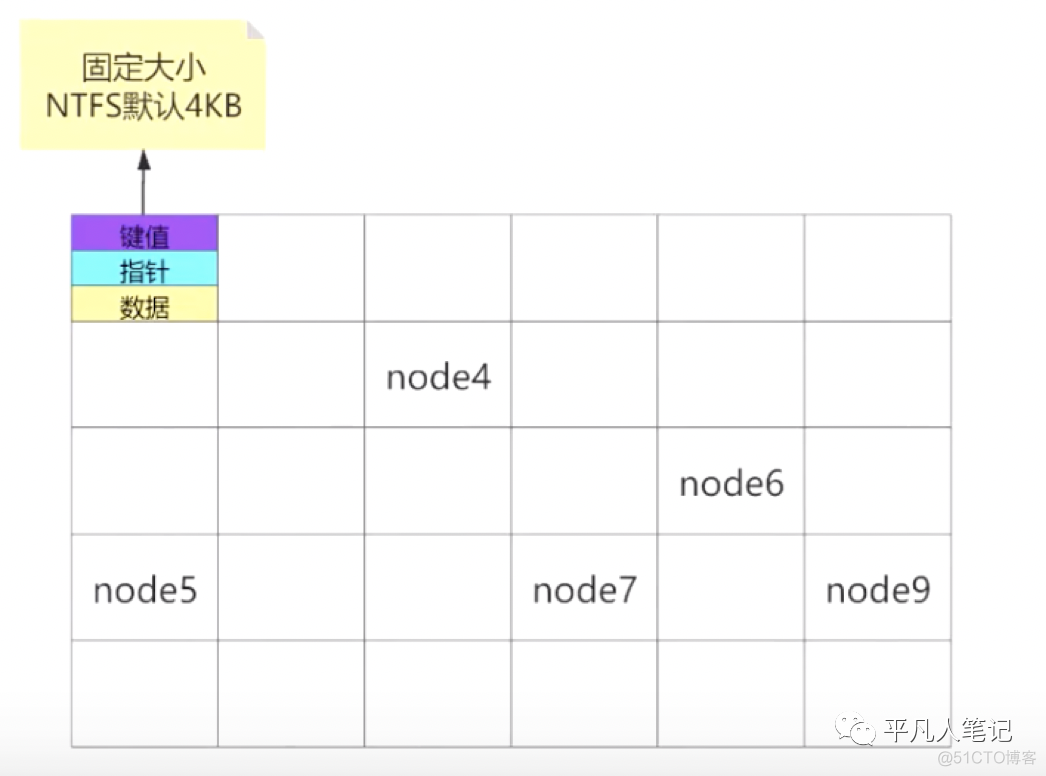
非叶子节点里面包含键值、指针和数据。单个节点的大小都是固定的,也意味着单条数据体积越大,单个节点所能装下的数据量越少,需要的节点数量越多,Max Degree是确定的即每一个节点的子节点数量是固定的,所以树的深度就越深,检索路径变长,检索效率越低。
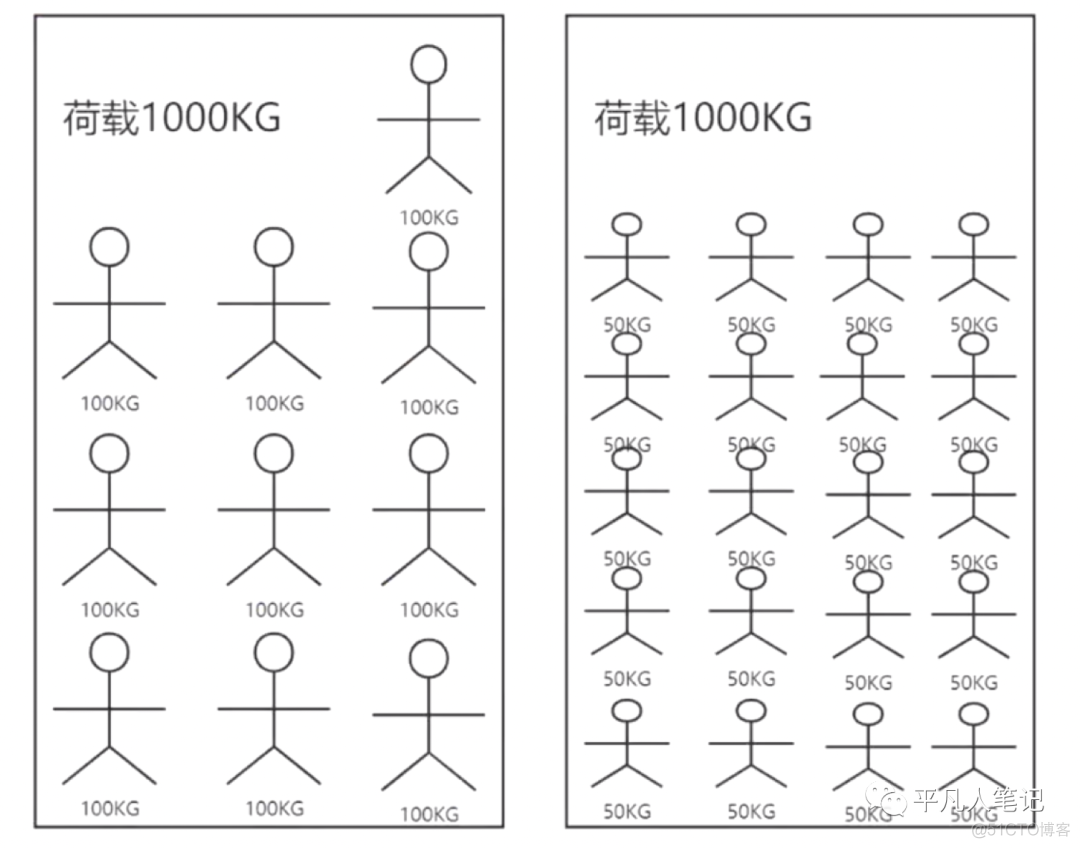
类比电梯,人越重,电梯里面装的人数量越少,那么需要的电梯数量越多。
所以尽量避免单个节点的数据过大。节点中包含键值、指针和数据。指针即索引,单个索引长度越小越好。

键值就是第一列的id数据,除了第一列其他的都是数据即data。
如果节点中data不存在的话即节点只包含键值和指针,那么节点中存储的数据个数就会变多,所需要的节点数量就会越少,树的深度也会越小。
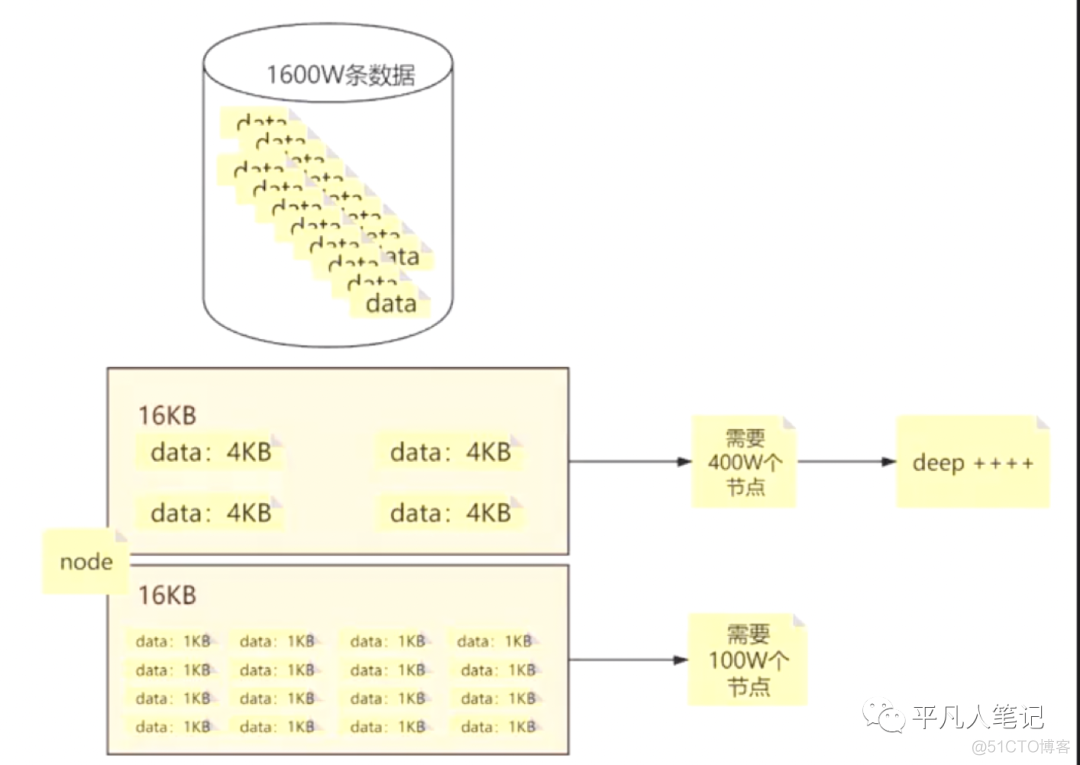
一个节点空间是16KB,一条数据4KB,可以存储4条数据,1600万的数据需要400万个节点,树的深度越深;若一条数据1KB,那么一个节点可以存储16条数据,1600万的数据需要100万个节点,树的深度变浅。
B+Trees
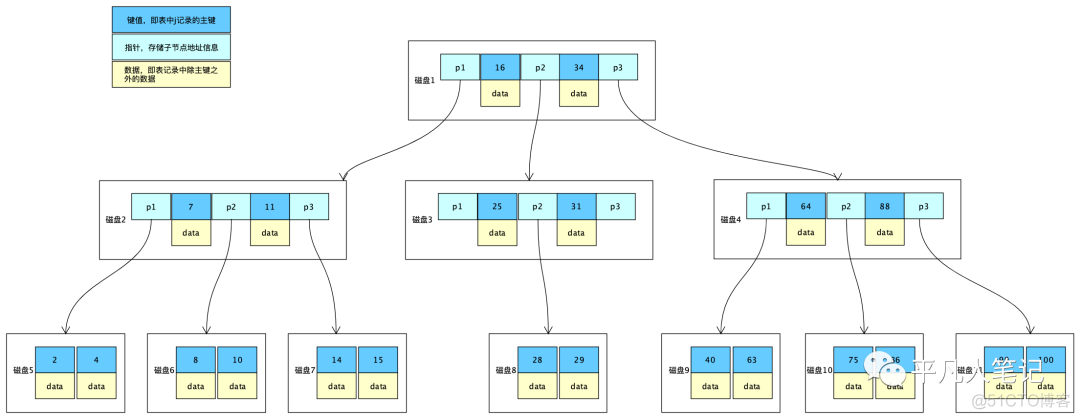
B+Trees相比于B-Trees,把非叶子节点中的data部分去掉了,只留下键值和指针,这样做的好处就是每个非叶子节点中就可以存储更多的数据,从而减少树的深度,提高检索效率。数据都放在了叶子节点中。
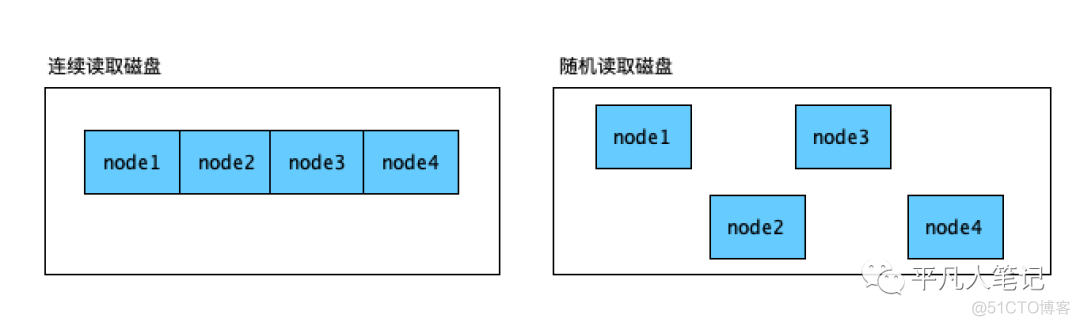
如果磁盘的数据在往u盘中拷贝的时候,如果拷贝的是源码,比如上千个文件,每秒传输速度只有几KB,本来100多M的大小,却需要10分钟或更久。如果只是一个zip压缩包,就会很快,因为zip包是一个文件,一个文件在磁盘中占用的空间是连续的。多个文件在磁盘中的位置是随机分布的,在拷贝的时候会不断的产生io。如果是连续的数据,可以从开始位置读取到结束为止。连续读比随机读要快的多。
当对大数据文本做检索的时候B+Trees的性能会直线下降。
你检索的这段可能是这种长文本字段,需要对title和content两个字段创建索引。因为B+Trees的要求是单个索引长度尽量小,所以这种场景就没有办法使用B+Trees了,因为当建立索引的字段都是文本字段,可能一个索引就会占用很多个节点,就会导致树的深度无限深,iO次数无限多,性能极差。索引可能会失效。精确度也很差。所以MySQL索引是不能解决大数据检索问题的。
全文检索
索引系统通过扫描文章中的每一个词,对其创建索引,指明在文章中出现的次数和位置,当用户查询时,索引系统就会根据事先创建的索引进行查找,并将查找的结果反馈给用户的检索方式。
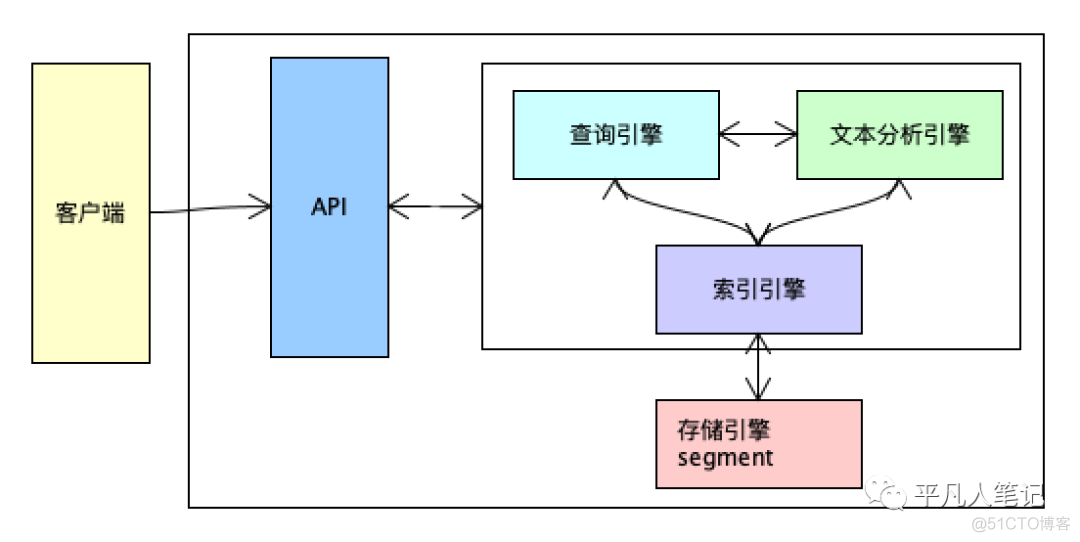
倒排索引原理
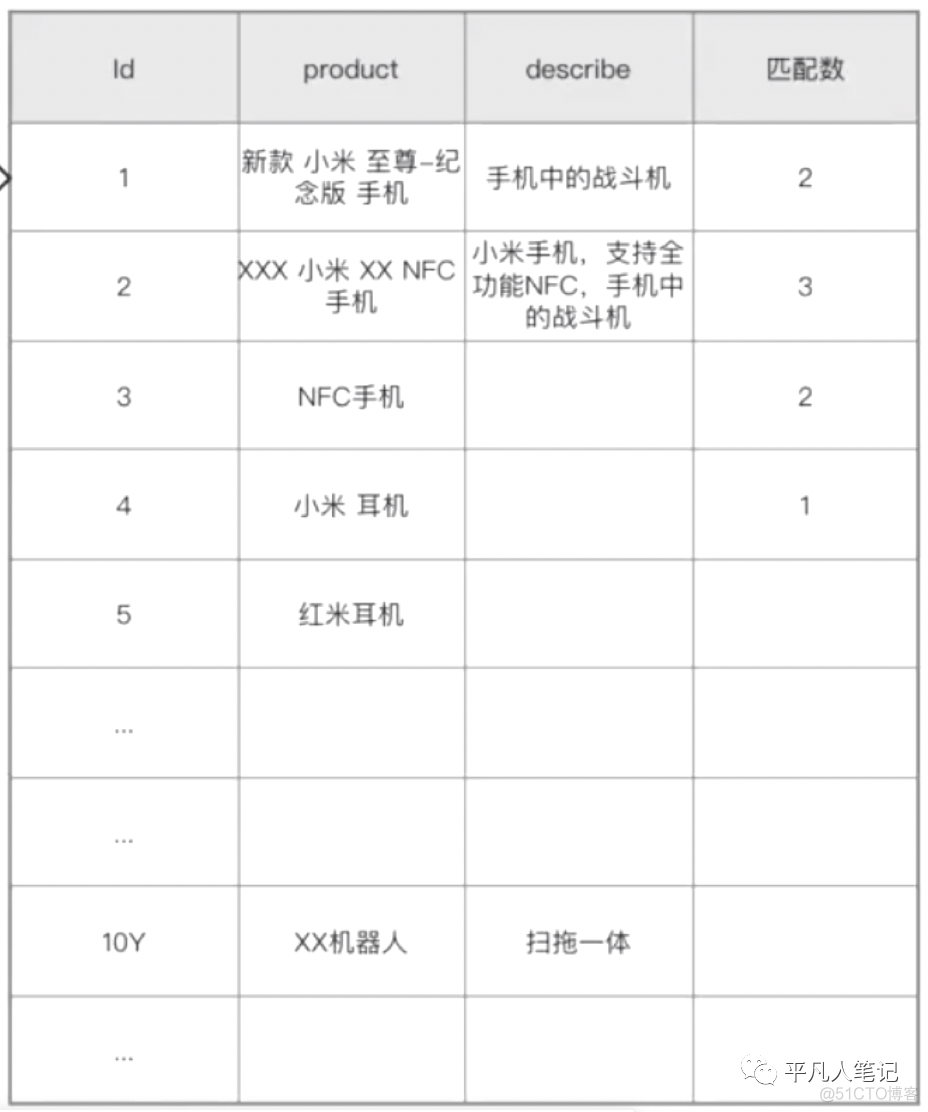
假设这是一张10亿数据量的表(实际开发过程中10亿的数据不会用数据表的方式存储,这里只是为了说明原理 )。

执行这个模糊查询,对product字段进行检索,会造成全表扫描。
这种查询的弊端:索引效率慢,准确度差(上面的查询语句,id=2的那条数据查询不出来)
建立倒排索引数据表
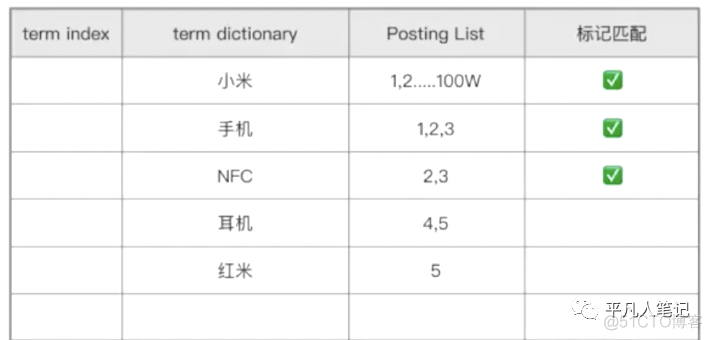
term dictionary:词项字典,这里面存放的是对索引字段product切词、规范化、去重、字典顺序之后的词项。
Posting List:存放的是当前词项所在的数据的id集合,id是由小到大有序的。
查询需求是"小米 NFC 手机",切词之后得到的第一个词项是小米,去词项字典中检索,第一个数据就命中了小米,就得到了小米所在数据的id集合,然后再获取对应的原始数据。这里面有10亿条数据,我只查询了一次就知道了这10亿条数据里面有哪些数据包含了这个词项。命中索引之后,就做一个标记,标记为命中,这就是倒排索引,当前分别对3个词项进行检索的过程,就是全文检索。百度就是全文检索引擎。
倒排索引中的三个数据结构
倒排表,包含了当前词项的每个数据的id,这是一个int类型的数组,不管id原先是什么类型,这里是int类型。
•词项字典词项字典里面存储的就是创建索引字典的每个词项。
•term index这是一个抽象的数据结构,为了加速当前词项检索的,底层是用的FST数据结构。
每一条数据如果拆分成若干个词项,每个词项在索引里面是一个新的数据,假如一条数据拆分成5个索引数据行,10亿条数据,索引的行数甚至有可能大于原数据的行数,假如这个索引检索了10亿次还没有查到,所以本身检索也是一个问题。
假如包含小米这个词项的数据有100万个数据,一个索引项有100万数据,怎么存储Post List这些数据,本身就是一个问题。
Post List是一个int数组,一个int是4个字节Byte,也就是32个bit,如果100万个id就是100万*4B=400万个字节即一个索引所带来的存储成本约等于3.8M。十亿数据就是10亿 * 3.8,所以如何解决这个存储问题呢?
怎么节省存储空间,提高检索性能?
•硬件层面访问量高的用SSD,可读可写;访问量不是那么高的用HDD机械硬盘,只读;访问量再低的,就用COLD冻结索引,快照的形式存放,7.x版本的es就支持可搜索快照。
当然这个不能解决主要问题。
•软件层面软件层面要节省存储空间,需要考虑的是怎么解决压缩数据的问题。
一个int类型占4个字节,也就是32个bit比特,一个bit位就是8个01组成。
一个字节8个bit,如果要存一个0,就是8个0;存一个1就是00000001;存一个2就是00000010(进一位)。
一个bit能存储的数据就是2的8次方-1,这也是为什么int类型的范围是2的31次方-1,为什么是31呢,因为有一个bit是用来存储+-号的。
如果100万个id就是100万*4B=400万个字节即一个索引所带来的存储成本约等于3.8M
FOR压缩Frame Of Reference
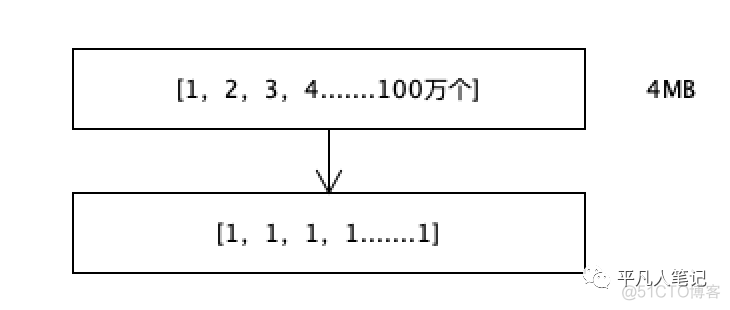
假设int数组中有1,2,3,4....直到100万个数字,大约占4MB的空间。
每个数字都存储它和前一个数字的差值,差值都是1,一个数字1的话可以用一个bit存储,因为一个bit的存储范围是0-1,本来用32个bit存储一个数字,现在用1个bit来存储。100万个数字只用100万个bit,原本是3200万个bit,压缩倍率是32倍。
如果数据量是32T,压缩之后就变成1T了,从1T中检索的效率是从32T中检索效率的32倍。
这是一个极端特殊的情况,因为实际中id不会重复且不会连续,如果不是连续的,那么差值就不是1。
倒排表里面存储的是id,这里面数字不是连续的,但一定是有序的,从小到大的,在索引创建的时候排好的序。

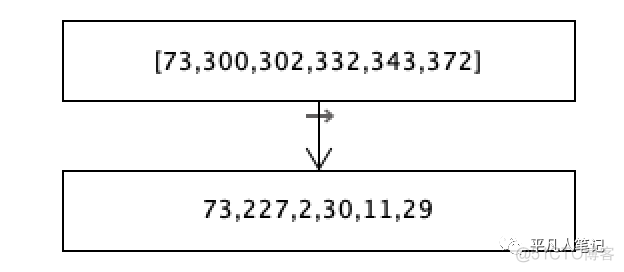
6个数字,一个数字占4个字节,也就是会占用24个字节。
计算差值,得到的差值列表是
1个bit取值范围是0-1;2个bit是0-3,能存储4个数字;3个bit,就是2的3次方为8,取值范围是0-7。

8个bit能存储256个数字。
自定义类型来存储数字。
看差值列表中最大的数字是227,用7个bit是否可以存储,7个bit能存储的数值最大是127,显然存储不下227,只能用8个bit来存储,因为8个bit最大能存储255。
当前这个数组中的每个数字只用8个bit来存储就可以了即6个数字,48个bit,6个字节。
原本这6个数字需要24个字节,现在只需要6个字节,压缩为原本的1/4。
继续优化...
227用8个bit存储,但是2用2个bit存储就可以了,因为2个bit存储范围是0-3。
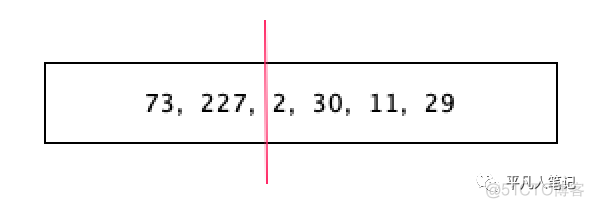
把这个数值切开,前面的大数用8个bit来存储,后面的小数用4个bit来存储。先别管从哪里切,就看哪边的数字间隔比较大,比如前面的数字由227一下子到了2,后面的数字都比较小,前面的数字用8个bit存储,后面的数字取决于它的最大值。
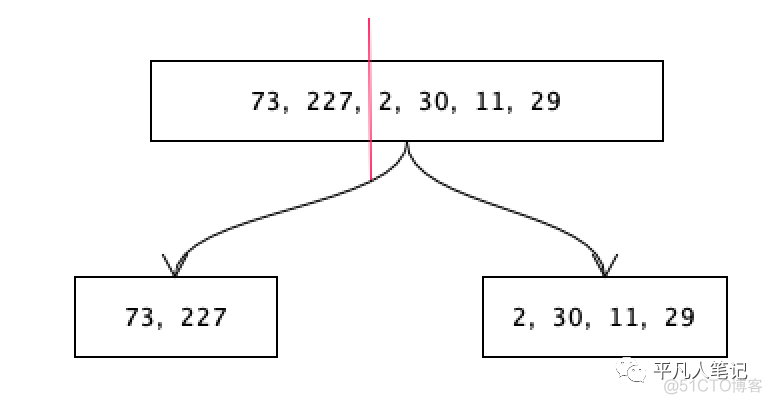
后面的数最大是30,5个bit(取值范围是0-31)可以存储的下,也就是后面的数组每个数字用5个bit就可以存储。
截止目前将一个大的数组拆分成了2个小的数组,前面的数组每个数字用8个bit来存储,后面的数组每个数字用5个bit来存储。
jdk中定义了用32个bit来存储一个int类型的数据,用64个bit来存储一个long类型的数据。
自定义定义一个用5个bit来存储的类型叫α,定义一个用8个bit来存储的类型叫β,类型的定义也要占用一个字节的空间。如果对每个数字都定义一个类型,那么定义的类型就太多了,就会占用很多的空间。假如说73和227都用8个bit的α来存储,本身α这个类型就占用一个字节。
接下来计算下这个差值列表[73,227,2,30,11,29]一共占多少空间?
73和227使用8个bit的自定义类型β来存储,β类型占1个字节,每个数字占8个bit即1个字节,2个数字占2个字节,共占3个字节。后面的数组2,30,11,29,用5个bit存储的自定义类型α来存储,α类型占1个字节,每个数字占5个bit,4个数字是20个bit即3个字节,共4个字节,所以这个数组一共占3+4=7个字节。
按照每个数字都用一个自定义类型来存储看看会占用多少空间?
73用7个bit来存储(在计算机操作系统层面,数据存储的最小单位是字节,一个字节是8个bit,这里使用7个bit,其实并没有省出空间来,实际占用的还是8个bit,这里就假设占用7个bit),这个定义类型占1个字节;227用8个bit来存储,自定义类型占一个1字节;那么[73,227]这个数组共占用1B+7b+1B+1B共3个字节+7个bit,也就是说不但没有节省空间,反而浪费了好几个bit空间,也就是说这个数组没有必要拆分的那么细,把这些数据浮动不大的数字放在一起,把这些数据较小的放在一起,是最适合的。
倒排索引的过程
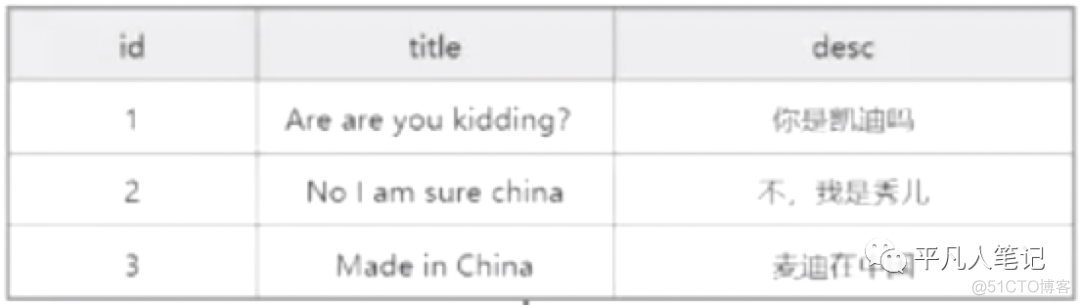
先进行切词,英文的切割规则就是按空格来切,切完之后,得到若干个词项。

然后对当前词项进行规范化(比如大写字母开头的Are转换成are、China和chinese转换成china(这是两个词,希望转换成一个词,降低检索成本)、's转换成is、过去分词转换成现在分词(made转换成make、kidding转换成kid))、去重、字典排序(按照abc..),最终的结果存在词项字典(term dictionary)
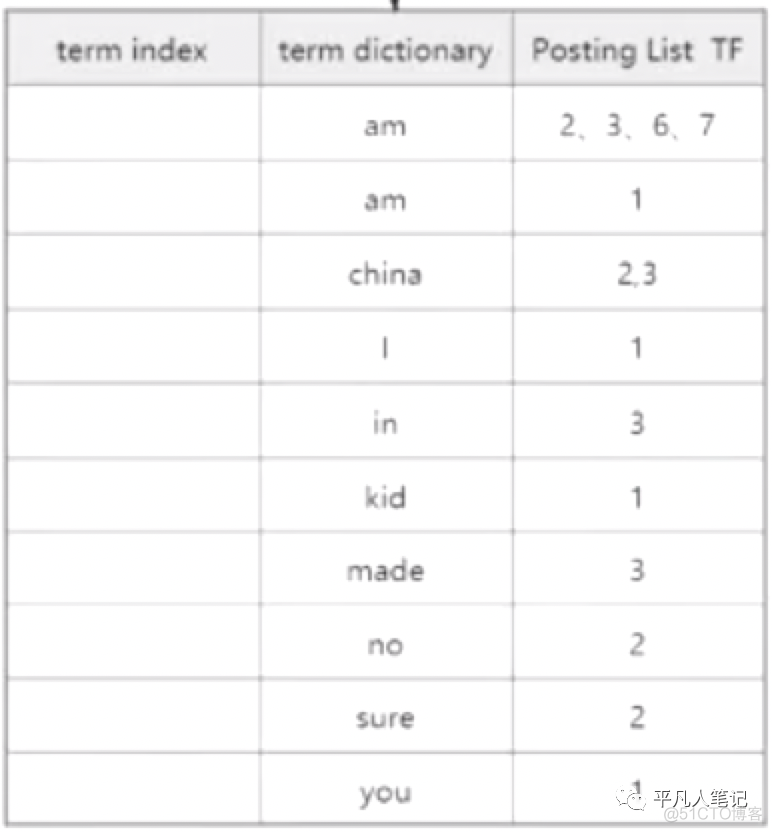
有序的词项字典,存储的是所有去重之后的结果,当然存储并不是按照二维表格的方式存储的。
Posting List 是倒排表,存储的是包含了当前词项的id集合。
TF是该词项出现的频率。
磁盘格式化
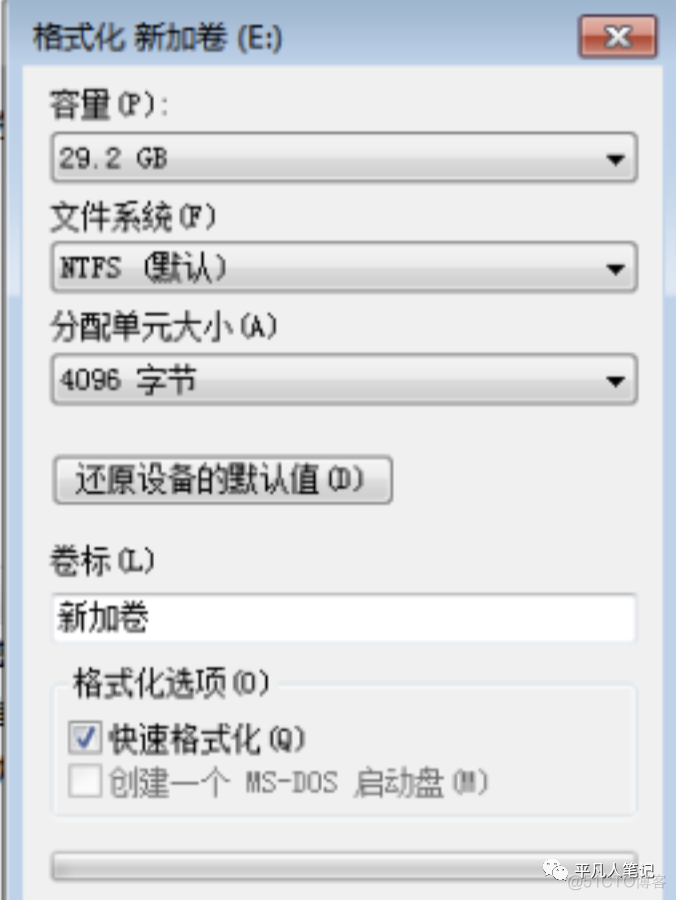
1、容量是选择要格式化的磁盘。
2、文件格式:
•exFAT格式windows、linux、macos都有该文件格式,缺点就是每个格子都比较大,
使用该格式,如果是大文件还可以,如果是小文件,就会占用大量的磁盘空间。
•NTFS格式3、单元就是一个data page空间大小,exFAT默认是128KB,NTFS默认是4KB
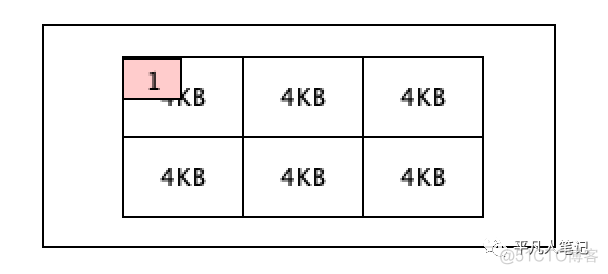
一个文件大小若为1KB,没有占满一个4KB大小的格子,该文件占用空间也是4KB。

内存检索数据的时候,最少读取磁盘中一个格子的数据,磁盘中一个格子占用空间是4KB,所以内存从磁盘中读取最小的数据单元就是一个4KB大小的格子。
搜索引擎的相关指标
全文检索的搜索引擎包括百度、搜狗、谷歌;垂直搜索的搜索引擎包括汽车之家、小米有品。
•快高效的压缩和快速的编码和解码
•准确(相关度)两种相关度评分算法 BM25和TF-IDF
•召回率召回率是返回数据丰富度的衡量指标,返回的越多,召回率越高。
搜索和检索的区别
搜索是要么符合条件,要么不符合条件,没有说部分符合;但检索是有相关度的。

这个查询示例中,查询"小米 NFC 手机",id=1的数据中包含2个词项,相关度为2;id=2的数据中包含3个词项,那么id=2的数据和查询需求的相关度更高。






.png)

.png)

