 云计算服务
云计算服务
 服务器租用
服务器租用
 DDOS 防护
DDOS 防护
 虚拟主机
虚拟主机
 域名服务
域名服务
 基础设施
基础设施
 关于我们
关于我们
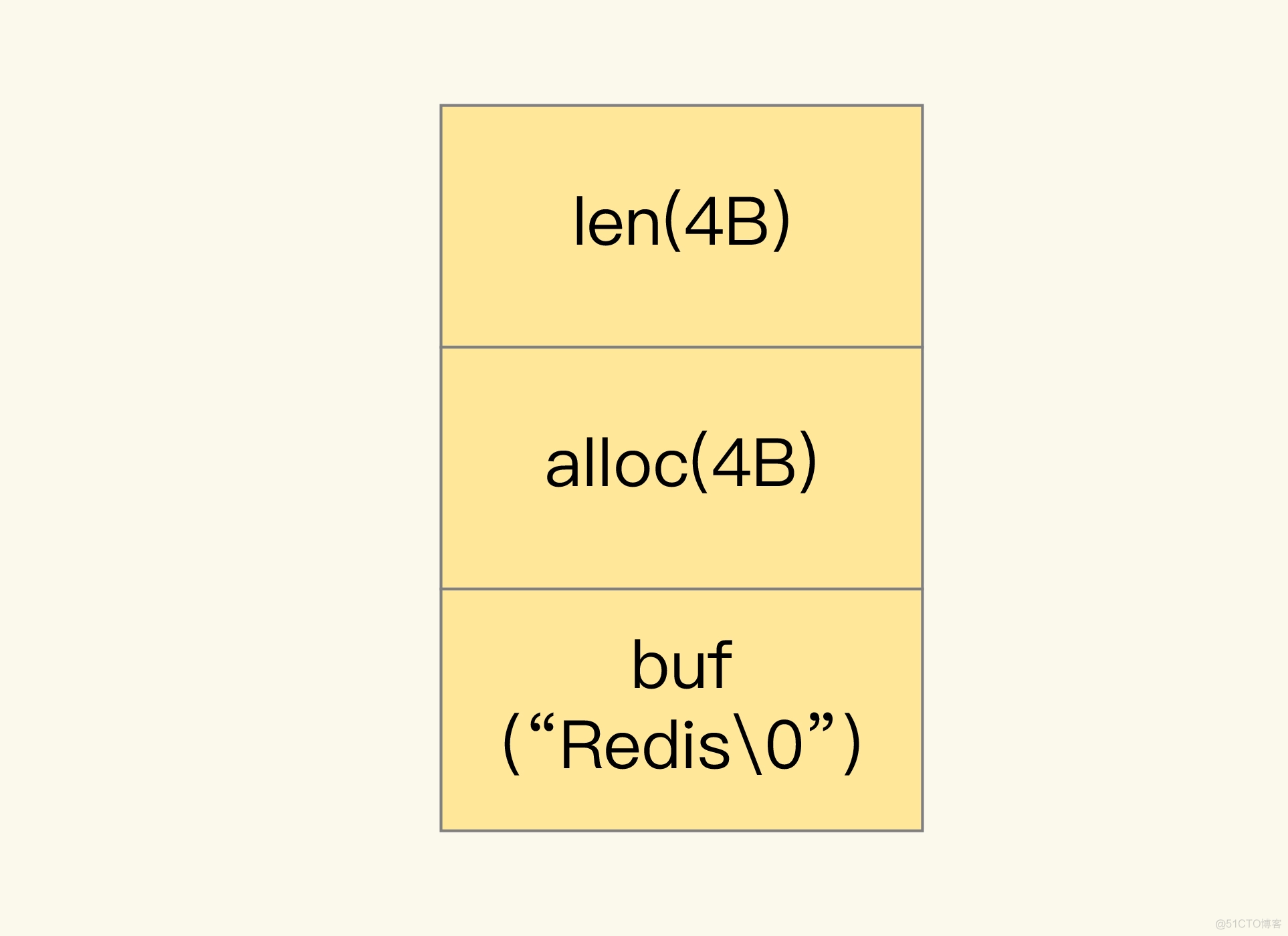
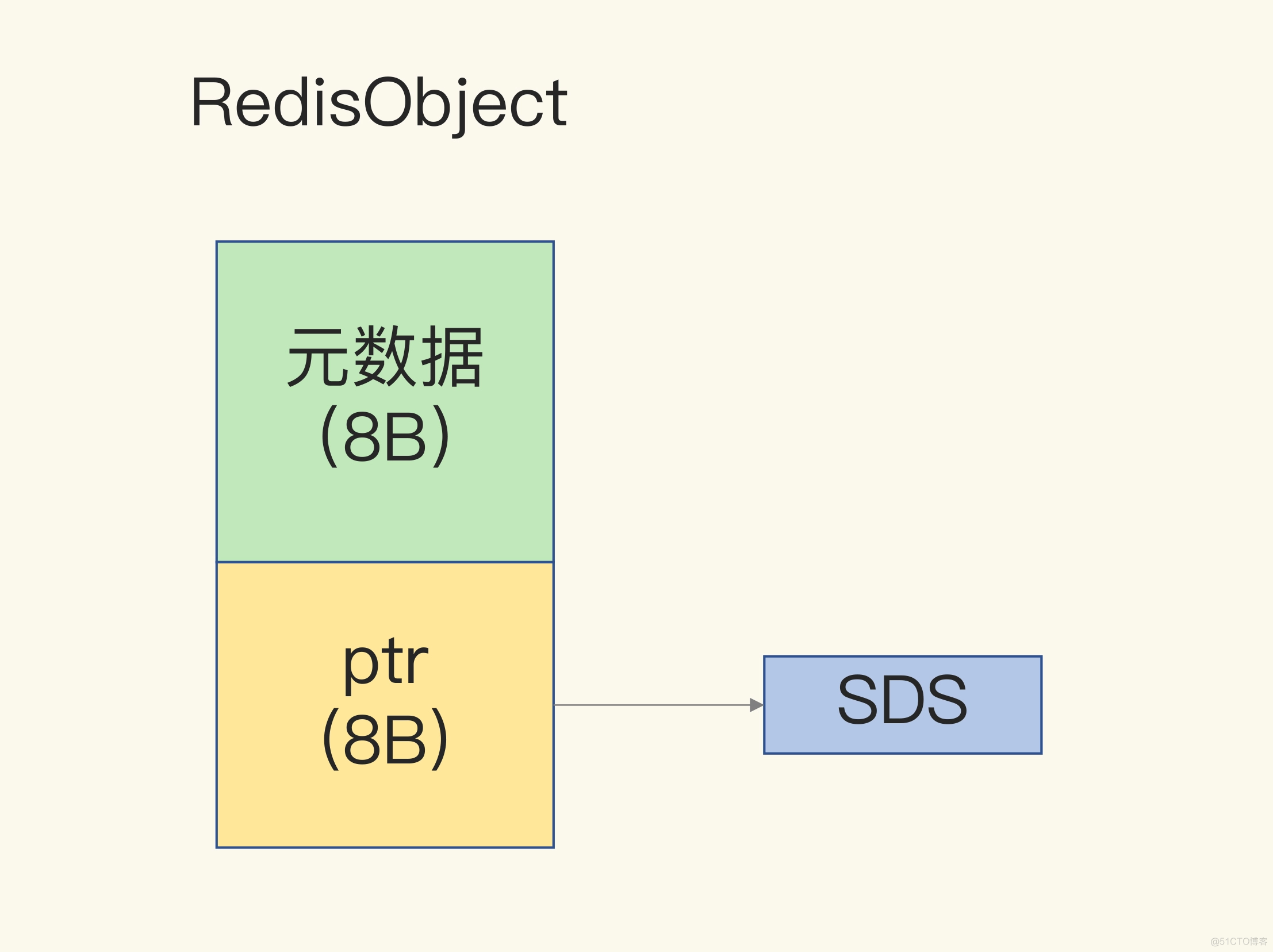
'\0',这就会额外占用 1 个字节的开销。len:占 4 个字节,表示 buf 的已用长度。alloc:也占个 4 字节,表示 buf 的实际分配长度,一般大于 len。RedisObject 结构体主要记录最后一次访问的时间、被引用的次数等信息,这些被称为元数据信息。一个 RedisObject 包含了 8 字节的元数据和一个 8 字节指针,这个指针再进一步指向具体数据类型的实际数据所在,例如指向 String 类型的 SDS 结构所在的内存地址。对于 String 类型来说,除了 SDS 的额外开销,还有一个来自于 RedisObject 结构体的开销。

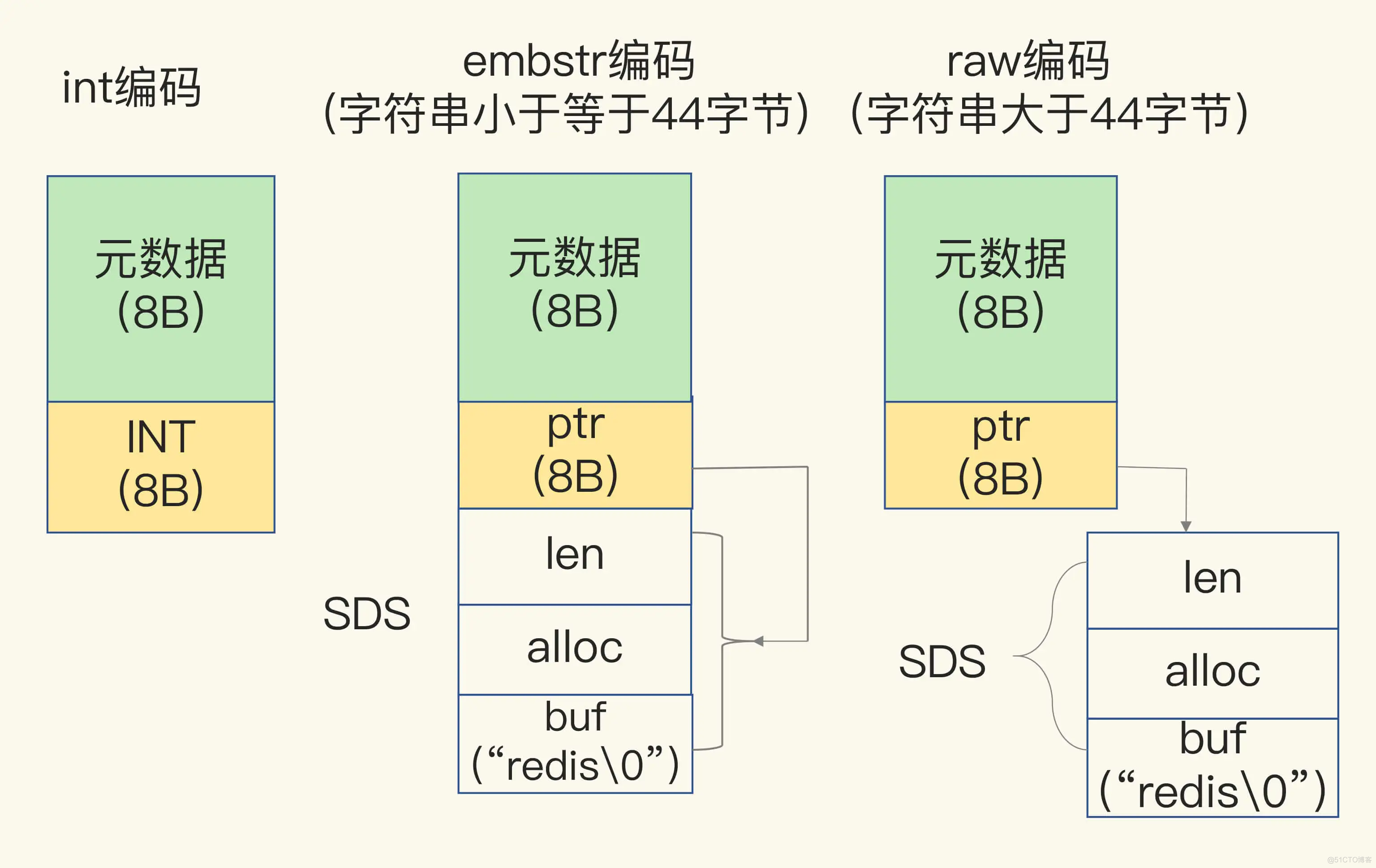
当保存的是Long类型整数时,RedisObject(元数据、指针)中的指针位置直接赋值为整数数据,节省指针空间。当保存的字符串 <= 44字节时,RedisObject (元数据、指针)和 SDS 结构体是一块连续的内存区域,可以避免内存碎片(embstr编码) 。当保存的字符串 > 44字节时,给 SDS 分配独立空间存储(raw编码)。Redis针对Long类型、SDS结构体 的内存布局的优化
int、embstr 和 raw 三种编码方式:
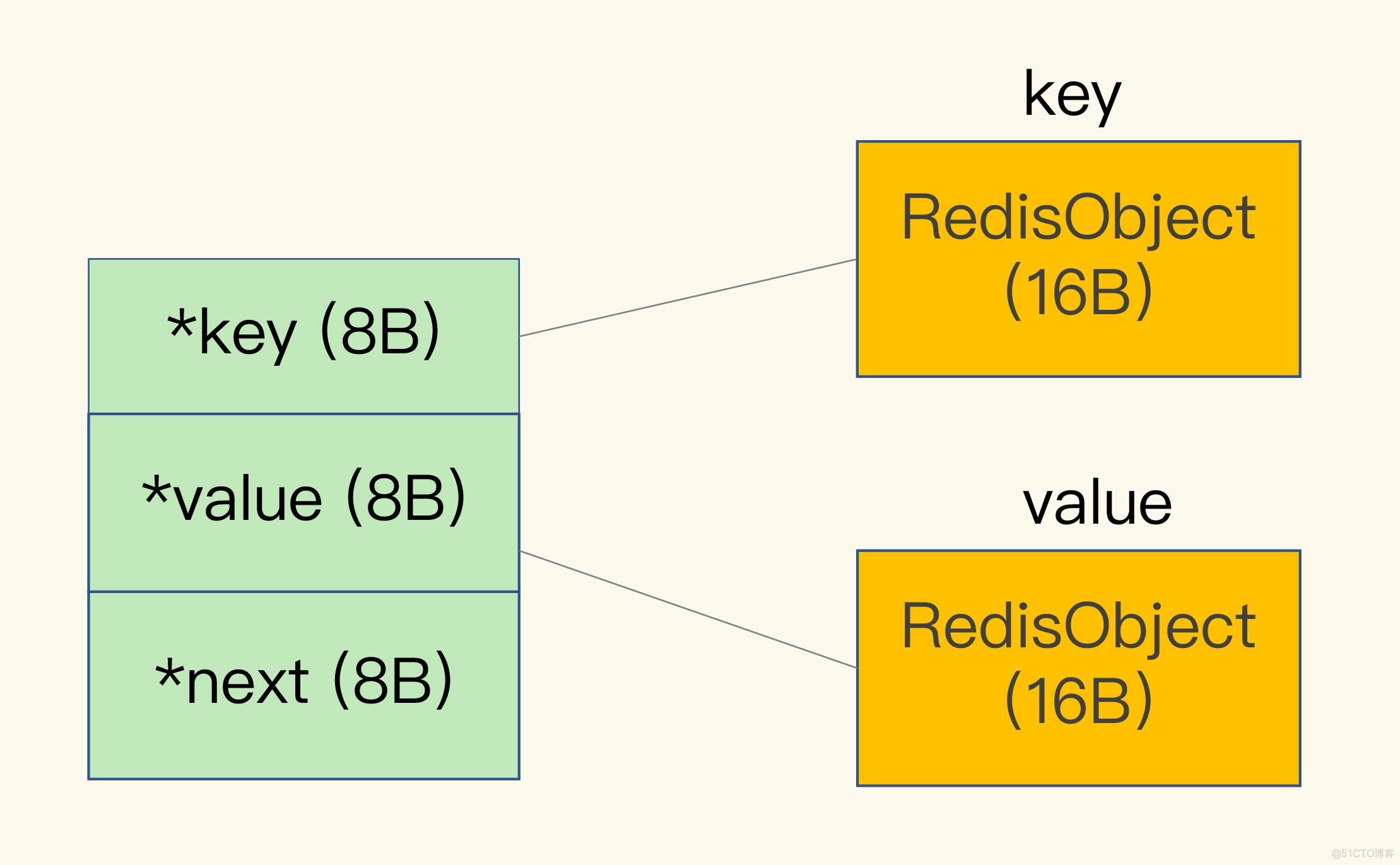
一个 dictEntry 需要24字节, 分别存储三个8字节的指针, 指向Key Value 对应的 RedisObject 和 下一个dictEntry。redis采用 jemalloc 分配库为这三个指针分配内存,jemalloc 分配的内存会比申请的字节数大,且小于临近的2的次幂(比如 24 —> 32 保存)Redis 会使用一个全局哈希表保存所有键值对,哈希表的每一项是一个 dictEntry 的结构体,用来指向一个键值对。
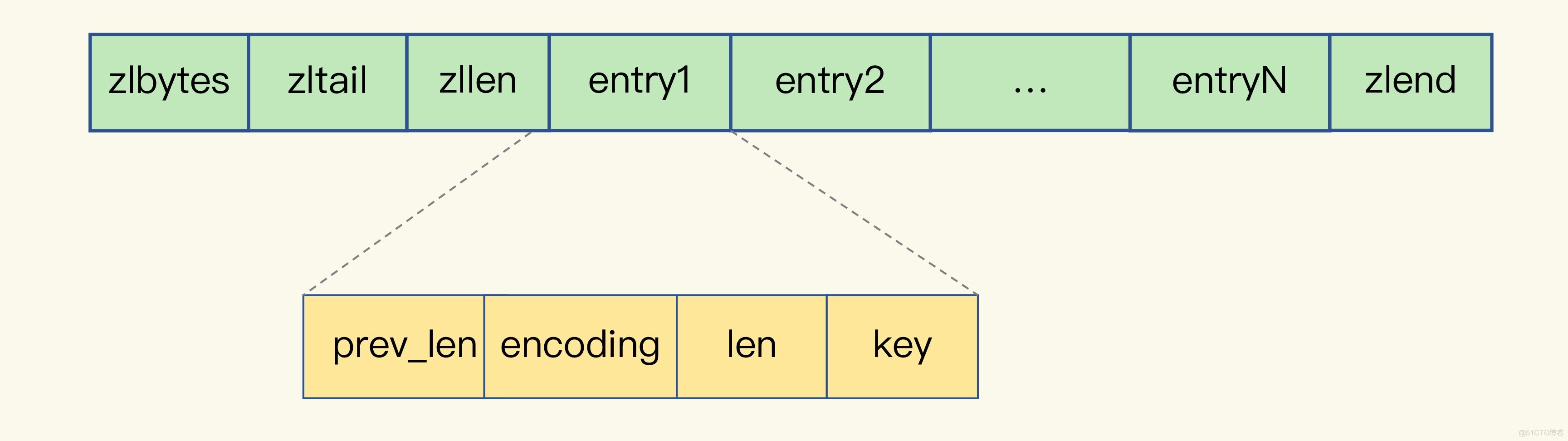
prev_len:表示前一个 entry 的长度。prev_len 有两种取值情况:1 字节或 5 字节。取值 1 字节时,表示上一个 entry 的长度小于 254 字节。虽然 1 字节的值能表示的数值范围是 0 到 255,但是压缩列表中 zlend 的取值默认是 255,因此,每个 entry 的元数据包括下面几部分:
就默认用 255 表示整个压缩列表的结束,其他表示长度的地方就不能再用 255 这个值了。所以,当上一个 entry 长度小于 254 字节时,prev_len 取值为 1 字节,否则,就取值为 5 字节。len:表示自身长度,4 字节。encoding:表示编码方式,1 字节。content:保存实际数据。这些 entry 会挨个放置在内存中,不需要再用额外的指针进行连接,这样就可以节省指针所占用的空间。
如何用集合类型保存单值的键值对 ?在保存单值的键值对时,可以采用基于 Hash 类型的二级编码方法。以图片 ID1101000060 和图片存储对象 ID3302000080 为例,我们可以把图片 ID 的前 7 位(1101000)作为 Hash 类型的键,把图片 ID 的最后 3 位(060)和图片存储对象 ID 分别作为 Hash 类型值中的 key 和 value。Hash 类型设置了用压缩列表保存数据时的Redis Hash 类型的两种底层实现结构,分别是压缩列表和哈希表。那么,Hash 类型底层结构什么时候使用压缩列表,什么时候使用哈希表呢 ?
两个阈值,一旦超过了阈值,Hash 类型就会用哈希表来保存数据了。这两个阈值分别对应以下两个配置项:hash-max-ziplist-entries:表示用压缩列表保存时哈希集合中的最大元素个数。hash-max-ziplist-value:表示用压缩列表保存时哈希集合中单个元素的最大长度。如果我们往 Hash 集合中写入的元素个数超过了 hash-max-ziplist-entries,或者写入的单个元素大小超过了 hash-max-ziplist-value,Redis 就会自动把 Hash 类型的实现结构由压缩列表转为哈希表。一旦从压缩列表转为了哈希表,Hash 类型就会一直用哈希表进行保存,而不会再转回压缩列表了。为了能充分使用压缩列表的精简内存布局,我们一般要控制保存在 Hash 集合中的元素个数。Redis 开销测试工具(推荐)Redis容量预估-极数云舟
压缩列表有什么缺点吗 ?Hash和Sorted Set 底层都是使用压缩列表和哈希表进行存储的。当采用ziplist方式存储时,虽然可以节省内存空间,但是在查询指定元素时,都要遍历整个ziplist,找到指定的元素。所以使用ziplist方式存储时,虽然可以利用CPU高速缓存,但也不适合存储过多的数据(hash-max-ziplist-entries和zset-max-ziplist-entries不宜设置过大),否则查询性能就会下降比较厉害。整体来说,这样的方案就是时间换空间,我们需要权衡使用。当使用ziplist存储时,我们尽量存储int数据,ziplist在设计时每个entry都进行了优化,针对要存储的数据,会尽量选择占用内存小的方式存储(整数比字符串在存储时占用内存更小),这也有利于我们节省Redis的内存。还有,因为ziplist是每个元素紧凑排列,而且每个元素存储了上一个元素的长度,所以当修改其中一个元素超过一定大小时,会引发多个元素的级联调整(前面一个元素发生大的变动,后面的元素都要重新排列位置,重新分配内存),这也会引发性能问题,需要注意。另外,使用Hash和Sorted Set存储时,虽然节省了内存空间,但是设置过期变得困难(无法控制每个元素的过期,只能整个key设置过期,或者业务层单独维护每个元素过期删除的逻辑,但比较复杂)。redis 中什么数据类型适合当做数据库使用,什么数据类型适合当做缓存使用 ?在选用Hash和Sorted Set存储时,意味着把Redis当做数据库使用,这样就需要务必保证Redis的可靠性(做好备份、主从副本),防止实例宕机引发数据丢失的风险。而采用String存储时,可以把Redis当做缓存使用,每个key设置过期时间,同时设置maxmemory和淘汰策略,控制整个实例的内存上限,这种方案需要在数据库层(例如MySQL)也存储一份映射关系,当Redis中的缓存过期或被淘汰时,需要从数据库中重新查询重建缓存,同时需要保证数据库和缓存的一致性,这些逻辑也需要编写业务代码实现。






.png)

.png)

