 云计算服务
云计算服务
 服务器租用
服务器租用
 DDOS 防护
DDOS 防护
 虚拟主机
虚拟主机
 域名服务
域名服务
 基础设施
基础设施
 关于我们
关于我们
持之以恒,贵在坚持,每天进步一点点!
前言本篇是flink 的「电商用户行为数据分析」的第 7 篇文章,为大家带来的是市场营销商业指标统计分析之页面广告分析的内容。通过本期内容,我们可以实现页面广告点击量统计和黑名单过滤的功能。


页面广告分析
电商网站的市场营销商业指标中,除了自身的APP推广,还会考虑到页面上的广告投放(包括自己经营的产品和其它网站的广告)。所以广告相关的统计分析,也是市场营销的重要指标。
对于广告的统计,最简单也最重要的就是页面广告的点击量,网站往往需要根据广告点击量来制定定价策略和调整推广方式,而且也可以借此收集用户的偏好信息。更加具体的应用是,我们可以根据用户的地理位置进行划分,从而总结出不同省份用户对不同广告的偏好,这样更有助于广告的精准投放。
页面广告点击量统计接下来我们就进行页面广告按照省份划分的点击量的统计。在src/main/scala下创建AdStatisticsByGeo.scala文件。同样由于没有现成的数据,我们定义一些测试数据,放在AdClickLog.csv中,用来生成用户点击广告行为的事件流。
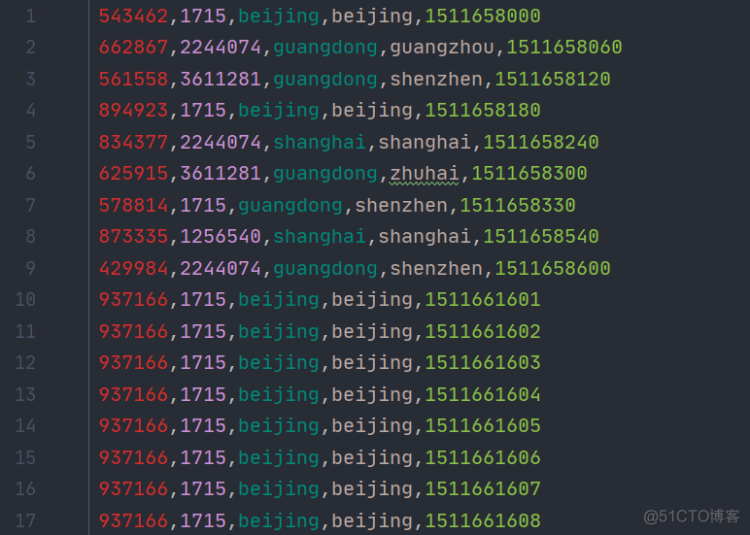 AdClickLog.csv
AdClickLog.csv
在代码中我们首先定义源数据的样例类AdClickLog,以及输出统计数据的样例类CountByProvince。主函数中先以 province 进行 keyBy ,然后开一小时的时间窗口,滑动距离为5秒,统计窗口内的点击事件数量。具体代码实现如下:
import java.sql.Timestamp运行结果
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
/*
* @Author: Alice菌
* @Date: 2020/12/11 10:52
* @Description:
页面广告点击量统计 (开一小时的时间窗口,滑动距离为5秒)
*/
object AdStatisticsByGeo {
// 定义输入数据样例类
case class AdClickEvent(userId:Long,adId:Long,province:String,city:String,timestamp:Long)
// 定义输出数据样例类
case class AdCountByProvince(province:String,windowEnd:String,count:Long)
def main(args: Array[String]): Unit = {
// 设置流处理的环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 设置程序的并行度
env.setParallelism(1)
// 设置时间特征为事件时间
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.readTextFile("YOUR_PATH\\AdClickLog.csv")
.map(data => {
// 样例数据:561558,3611281,guangdong,shenzhen,1511658120
val dataArray: Array[String] = data.split(",")
AdClickEvent(dataArray(0).toLong,dataArray(1).toLong,dataArray(2),dataArray(3),dataArray(4).toLong)
})
.assignAscendingTimestamps(_.timestamp * 1000L) // 添加水印
.keyBy(_.province) // 按照 province 分组
.timeWindow(Time.hours(1),Time.seconds(5)) // 设置窗口的大小为1h,滑动距离为5s
.process(new AdCount) // 开窗聚合统计
.print() // 输 出 结 果
// 执行程序
env.execute("ad analysis job")
}
class AdCount() extends ProcessWindowFunction[AdClickEvent,AdCountByProvince,String,TimeWindow]{
override def process(key: String, context: Context, elements: Iterable[AdClickEvent], out: Collector[AdCountByProvince]): Unit = {
// 因为我们是按照 province 进行分组
// 所以这里直接根据 key 就能获取到 province
val province: String = key
// 将 窗口结束的时间戳 转换为 String 时间字符串
val windowEnd: String = new Timestamp(context.window.getEnd).toString
// 获取窗口元素的个数
val count: Int = elements.size
// 输出元素
out.collect(AdCountByProvince(province,windowEnd,count))
}
}
}
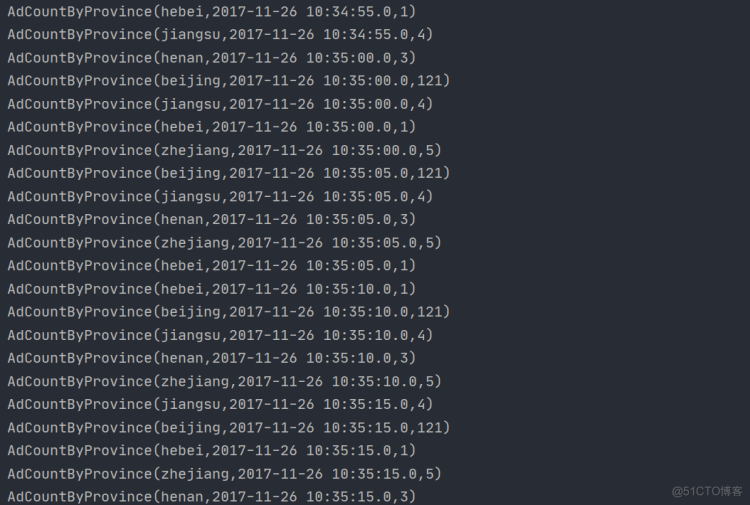 部分结果截图
部分结果截图
上节我们进行的点击量统计,同一用户的重复点击是会叠加计算的。在实际场景中,同一用户确实可能反复点开同一个广告,这也说明了用户对广告更大的兴趣;但是如果用户在一段时间非常频繁地点击广告,这显然不是一个正常行为,有刷点击量的嫌疑。所以我们可以对一段时间内(比如一天内)的用户点击行为进行约束,如果对同一个广告点击超过一定限额(比如100次),应该把该用户加入黑名单并报警,此后其点击行为不应该再统计。
具体代码实现如下:
import java.sql.Timestamp运行结果
import org.apache.flink.api.common.functions.AggregateFunction
import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor}
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.KeyedProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.WindowFunction
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
/*
* @Author: Alice菌
* @Date: 2020/12/11 11:37
* @Description:
黑名单过滤
*/
object AdAnalysisByProvinceBlack {
// 定义输入输出样例类
case class AdClickEvent(userId:Long,adId:Long,province:String,city:String,timestamp:Long)
case class AdCountByProvince(province:String,windowEnd:String,count:Long)
//定义侧输出流报警信息样例类
case class BlackListWarning(userId:Long,adId:Long,msg:String)
def main(args: Array[String]): Unit = {
// 定义流处理环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 设置并行度
env.setParallelism(1)
// 设置时间特征为事件时间
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val adLogStream: DataStream[AdClickEvent] = env.readTextFile("YOUR_PATH\\AdClickLog.csv")
.map(data => {
// 样例数据:561558,3611281,guangdong,shenzhen,1511658120
val dataArray: Array[String] = data.split(",")
AdClickEvent(dataArray(0).toLong, dataArray(1).toLong, dataArray(2), dataArray(3), dataArray(4).toLong)
})
.assignAscendingTimestamps(_.timestamp * 1000L ) // 设置水印
//定义刷单行为 过滤操作
val filterBlackListStream: DataStream[AdClickEvent] = adLogStream // 设置水印
.keyBy(data =>(data.userId, data.adId)) // 按照用户 和 广告id进行分组)
.process(new FilterBlackList(100L))
// 按照 province分组开窗聚合统计
val adCountStream: DataStream[AdCountByProvince] = filterBlackListStream
.keyBy(_.province)
.timeWindow(Time.hours(1), Time.seconds(5)) // 设置窗口大小为1h , 滑动距离为5s
.aggregate(new AdCountAgg(), new AdCountResult())
// 打印结果
adCountStream.print()
// 打印测输出流的数据
filterBlackListStream.getSideOutput(new OutputTag[BlackListWarning]("blacklist")).print("blacklist")
// 执行程序
env.execute("as analysis job")
}
// 实现自定义 ProcessFunction
class FilterBlackList(maxClickCount:Long) extends KeyedProcessFunction[(Long,Long),AdClickEvent,AdClickEvent]{
// 定义一个状态,需要保存当前用户对当前广告的点击量 count
lazy val countState:ValueState[Long] = getRuntimeContext.getState(new ValueStateDescriptor[Long]("count",classOf[Long]))
// 定义一个标识位,用来表示用户是否已经在黑名单中
lazy val isSendState:ValueState[Boolean] = getRuntimeContext.getState(new ValueStateDescriptor[Boolean]("is-sent",classOf[Boolean]))
override def processElement(value: AdClickEvent, ctx: KeyedProcessFunction[(Long, Long), AdClickEvent, AdClickEvent]#Context, out: Collector[AdClickEvent]): Unit = {
// 取出状态数据
val curCount: Long = countState.value()
// 如果是第一个数据,那么注册第二天0点的定时器,用于清空状态
if (curCount == 0){
val ts: Long = (ctx.timerService().currentProcessingTime() / (1000*60*60*24) + 1) * (1000*60*60*24)
ctx.timerService().registerProcessingTimeTimer(ts)
}
// 判断 count 值是否达到上限,如果达到,并且之前没有输出过报警信息,那么则报警
if (curCount > maxClickCount){
if (!isSendState.value()){
// 侧输出数据
ctx.output(new OutputTag[BlackListWarning]("blacklist"),BlackListWarning(value.userId,value.adId,"click over"+maxClickCount+"times today"))
// 更新黑名单状态
isSendState.update(true)
}
// 如果达到上限,则不再进行后续的操作,即此后其点击行为不应该再统计
return
}
// count 值 + 1
countState.update(curCount + 1)
// 输出数据
out.collect(value)
}
// 0 点触发定时器,直接清空状态
override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[(Long, Long), AdClickEvent, AdClickEvent]#OnTimerContext, out: Collector[AdClickEvent]): Unit = {
countState.clear()
isSendState.clear()
}
}
// 自定义预聚合函数
class AdCountAgg() extends AggregateFunction[AdClickEvent,Long,Long]{
override def createAccumulator(): Long = 0L
override def add(value: AdClickEvent, accumulator: Long): Long = accumulator + 1
override def getResult(accumulator: Long): Long = accumulator
override def merge(a: Long, b: Long): Long = a + b
}
// 自定义窗口函数,第一个参数就是预聚合函数最后输出的值,Long
class AdCountResult() extends WindowFunction[Long,AdCountByProvince,String,TimeWindow]{
override def apply(key: String, window: TimeWindow, input: Iterable[Long], out: Collector[AdCountByProvince]): Unit = {
out.collect(AdCountByProvince(key,new Timestamp(window.getEnd).toString,input.head))
}
}
}
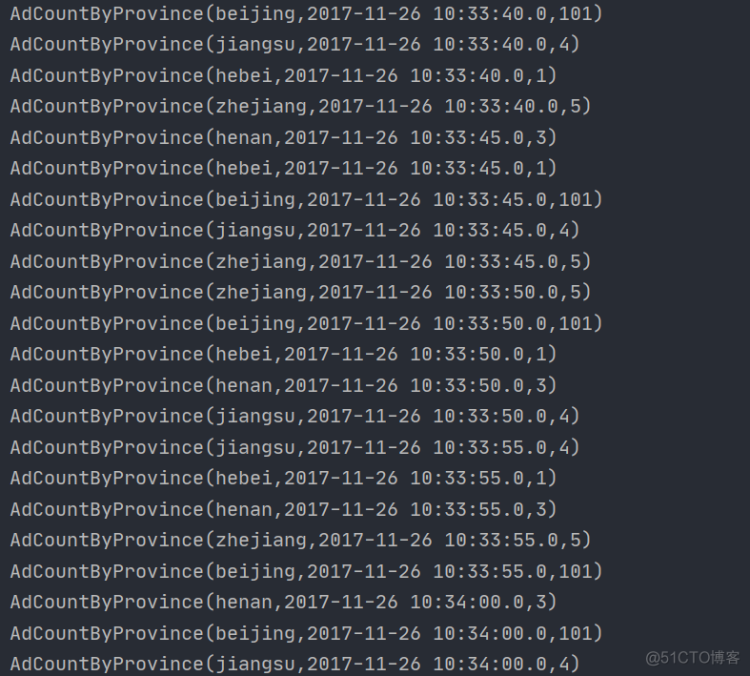 部分结果截图
部分结果截图
小结
本期关于介绍flink 电商用户行为数据分析之页面广告分析的文章就到这里,考虑到部分小伙伴对于中间的部分代码有疑问,所以我每行都写上了注释,因此详细的过程笔者就不在这里详细赘述了。看了注释仍有疑惑的小伙伴们欢迎添加,互相学习,共同进步!你知道的越多,你不知道的也越多,我是Alice,我们下一期见!
受益的朋友记得三连支持小菌!
文章持续更新,可以微信搜一搜「 猿人菌 」第一时间阅读,思维导图,大数据书籍,大数据高频面试题,海量一线大厂面经…期待您的关注!








.png)

.png)

