 云计算服务
云计算服务
 服务器租用
服务器租用
 DDOS 防护
DDOS 防护
 虚拟主机
虚拟主机
 域名服务
域名服务
 基础设施
基础设施
 关于我们
关于我们
物理分代
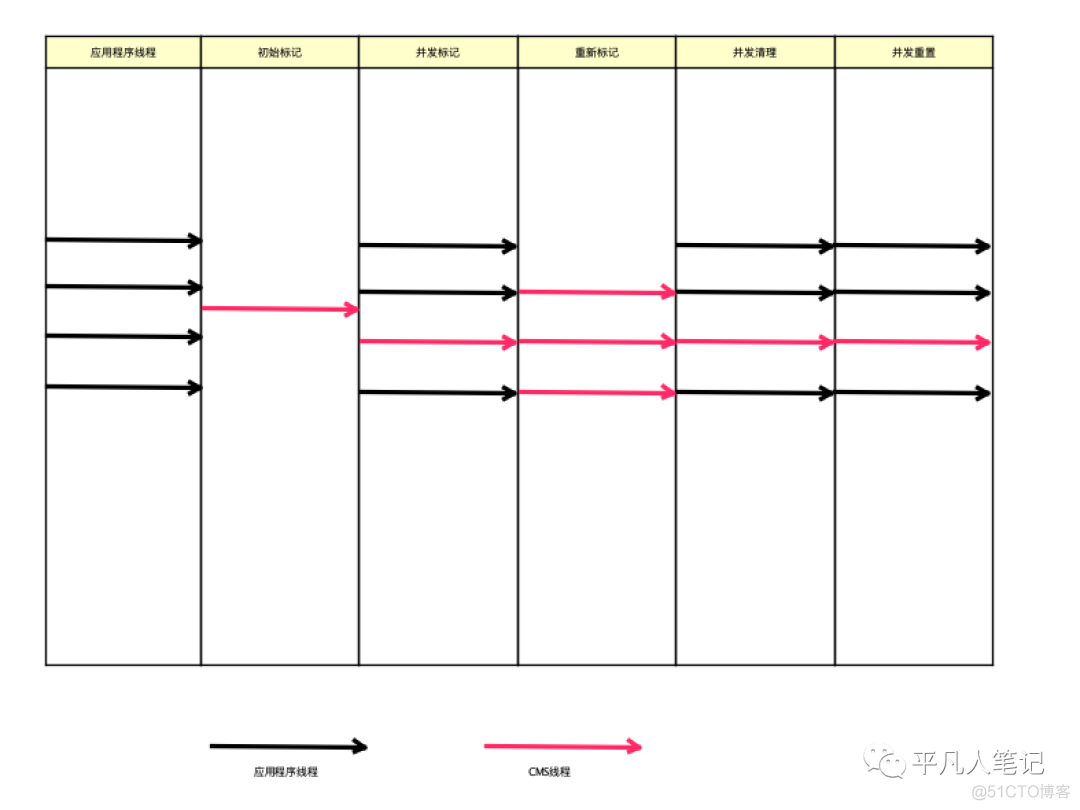

初始标记
并发标记
重新标记
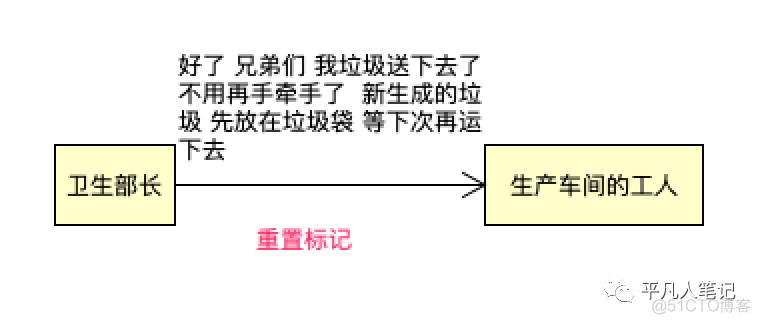
并发清理
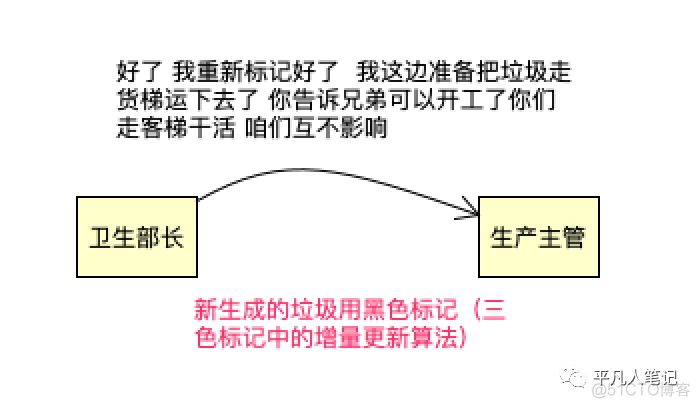
并发重置
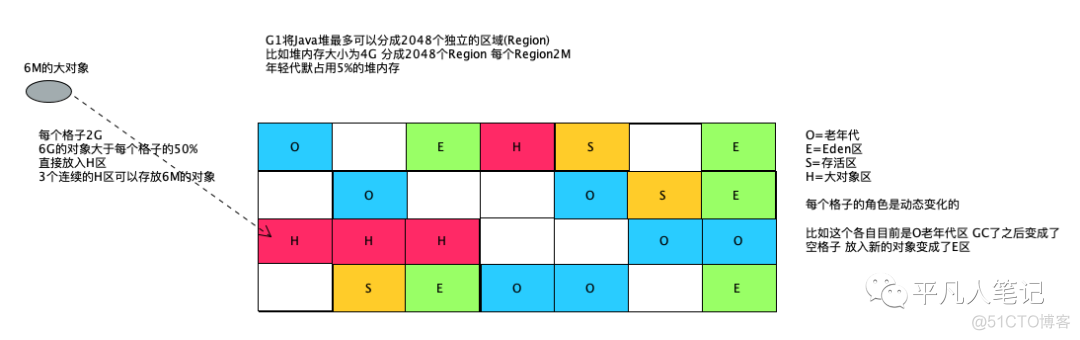
逻辑分代 非物理分代
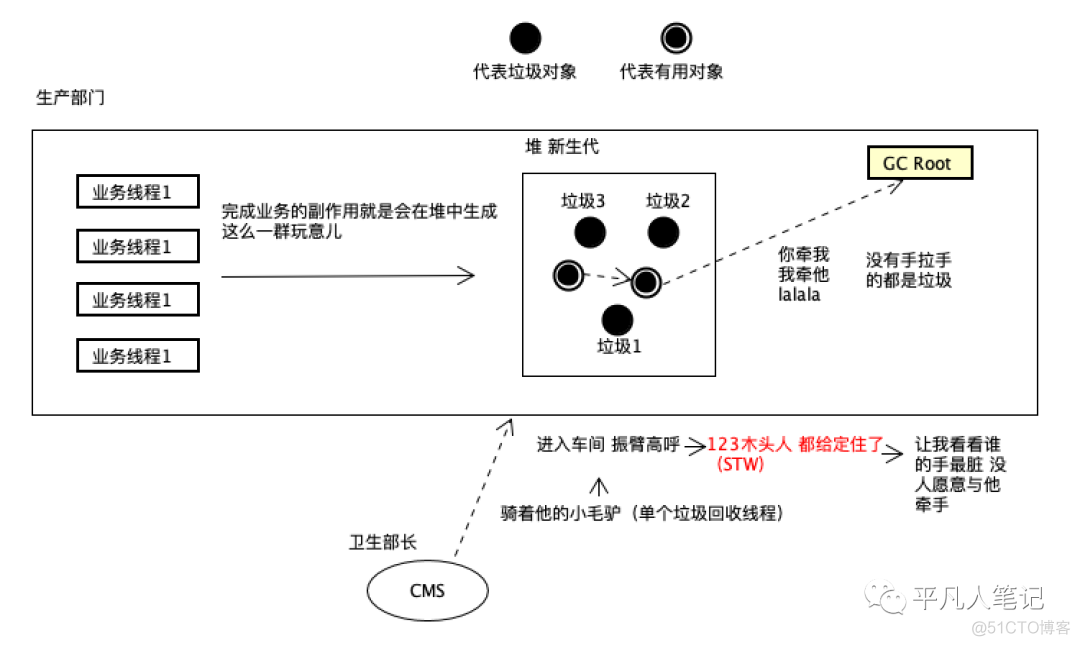
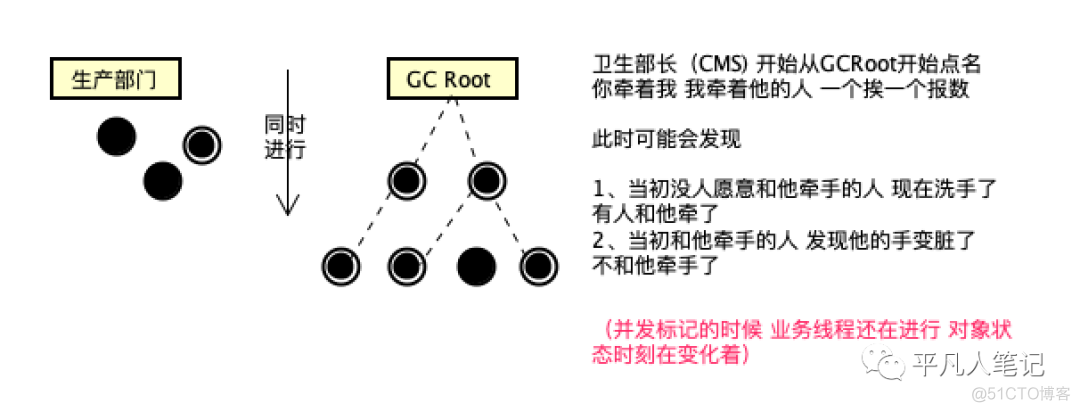
运作过程
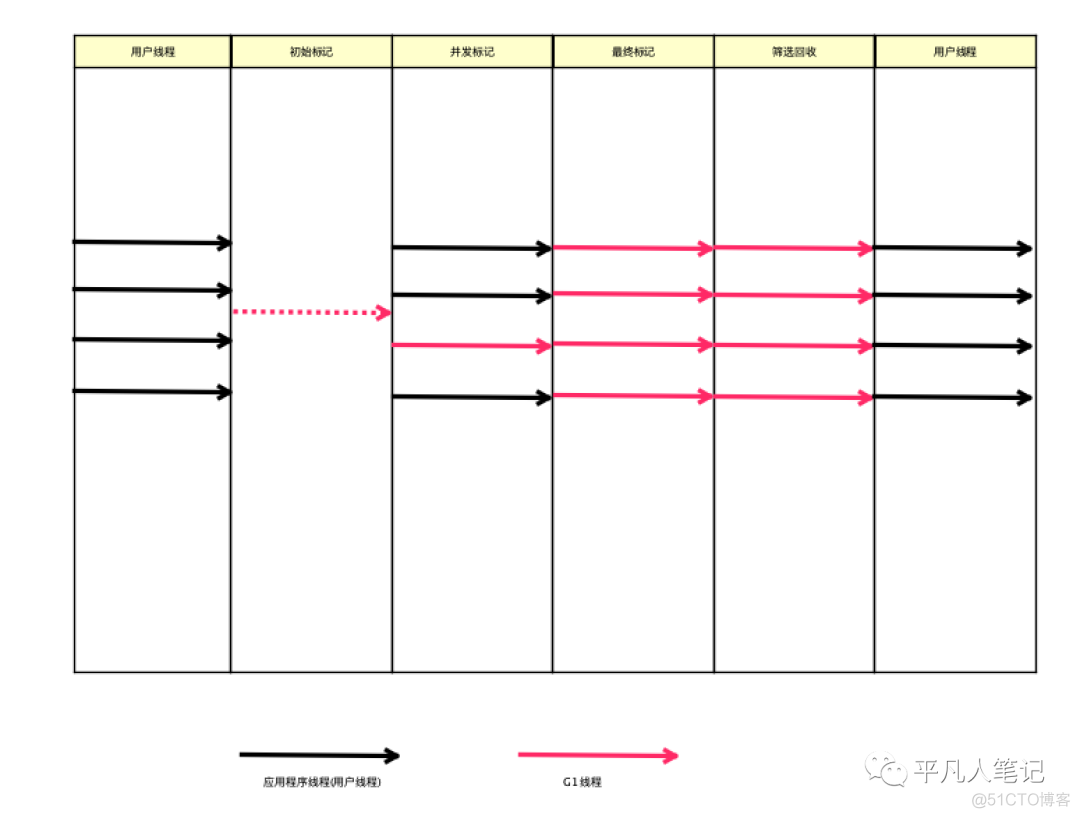
G1的初始标记和并发标记和CMS类似
G1的最终标记和CMS的重新标记类似
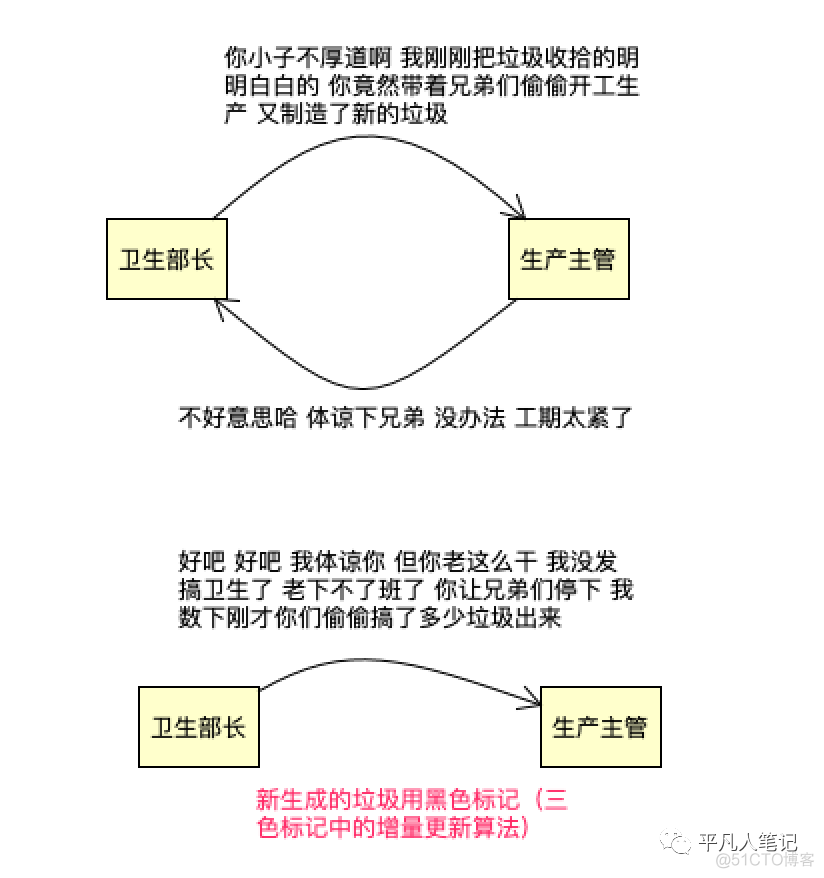
G1和CMS解决漏标算法区别
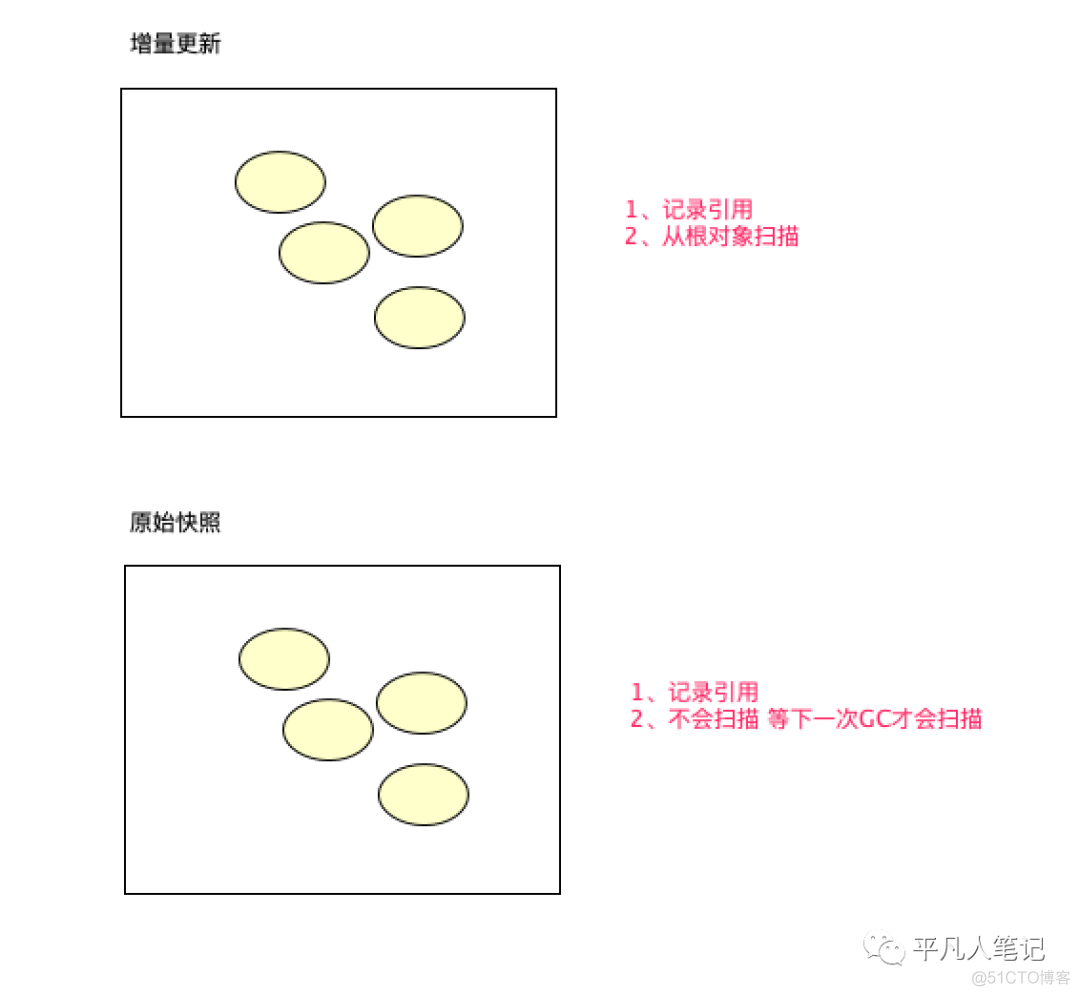
G1有很多分区 在GC Root扫描的时候会涉及到很多的跨代扫描
所以尽量不去扫描 等下一次GC再去做
CMS就年轻代和老年代 没有那么多跨代扫描的问题
G1的筛选回收和CMS的并发清理类似 区别是G1会ST
G1为了满足用户体验
可以设置一个MaxGCPause参数 最大停顿时间
比如设置为200ms
即代表不会让三个stw的过程(初始标记、最终标记、筛选回收)
gc时间不会超过200ms
怎么做到的呢?
就是在筛选回收阶段可以回收一部分垃圾对象
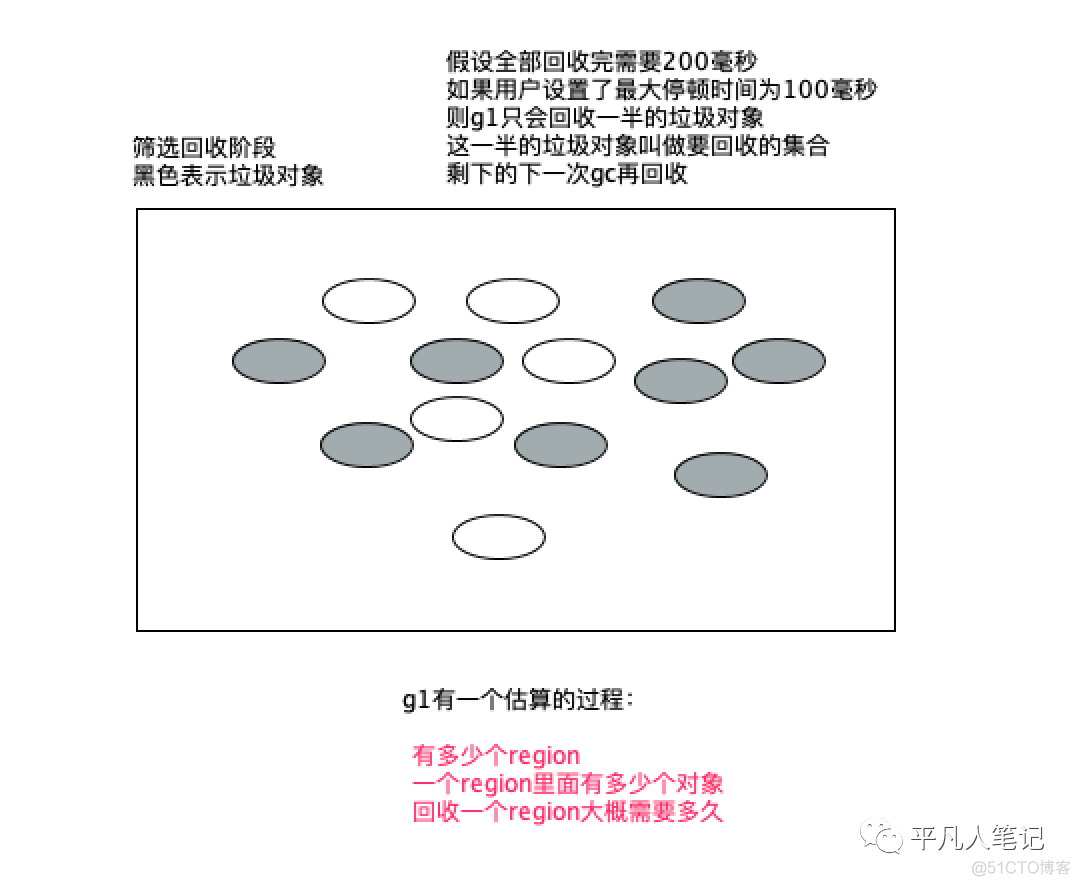
使用复制算法进行回收
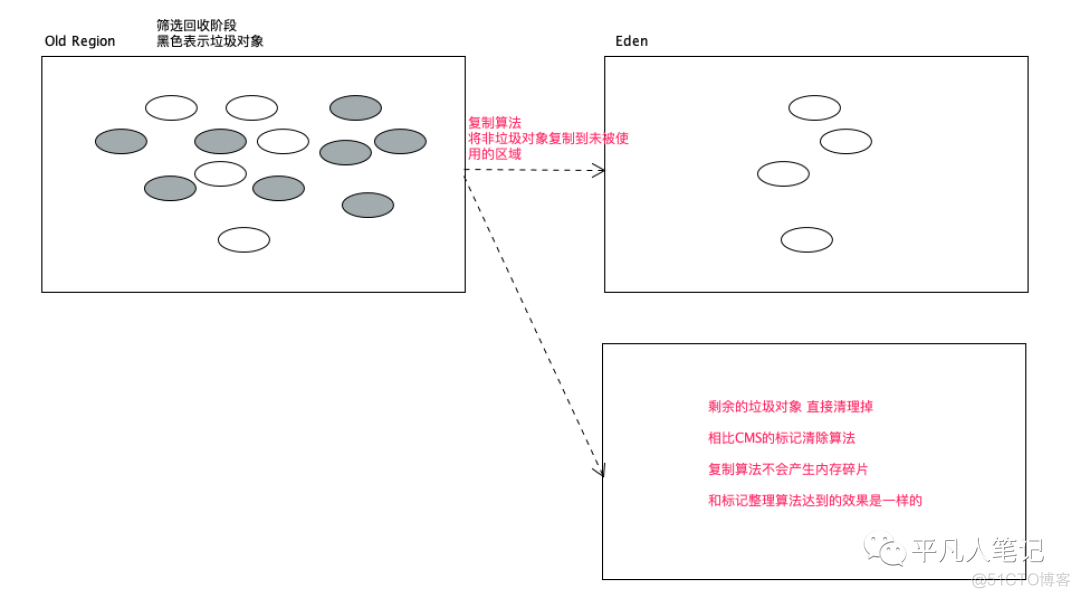
G1回收集会维护一个优先级列表
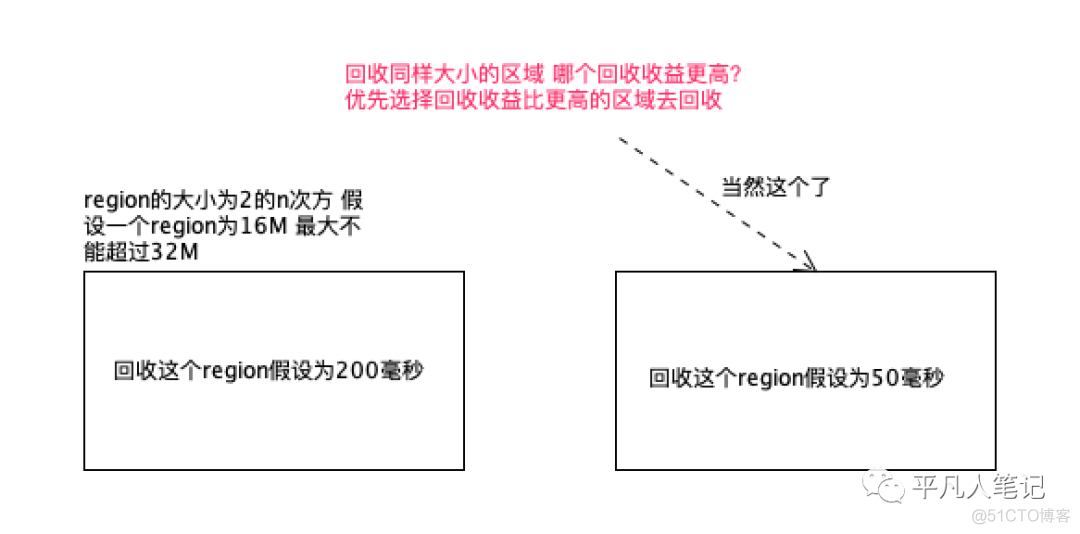
按照回收收益比排序 收益比更高的优先回收
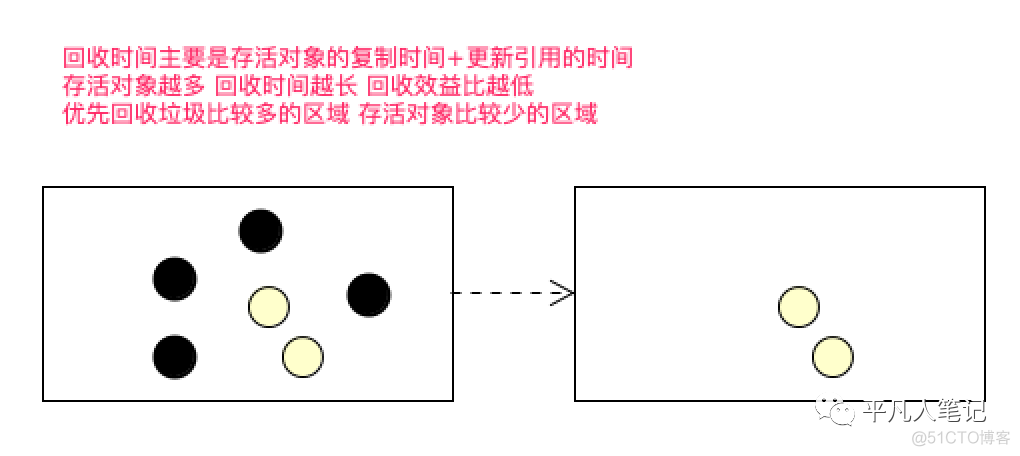
每个区的回收时间是由这个区的存活对象复制到空白区域的时间来决定的
回收时间
停顿时间设置的太短有什么影响?
默认是200毫秒 如果设置为10毫秒
停顿时间设置过短 一次清理的垃圾比较少
垃圾就会越积越多 就会触发FGC
停顿时间就会失效
G1垃圾收集分类
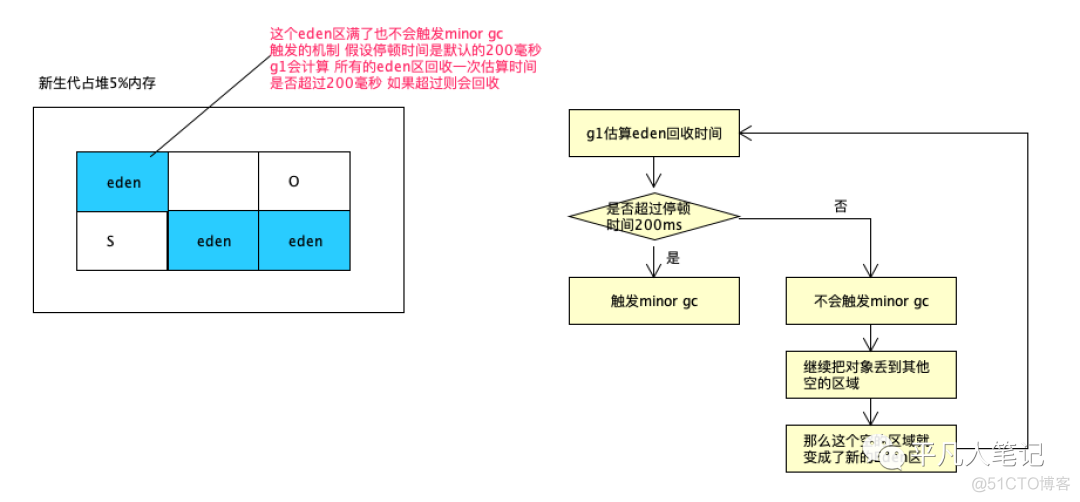
在触发minor gc之前会计算下当前的eden区回收时间是否会超过最大停顿时间MixedGC
如果接近就会触发
如果不接近 就不会触发 继续加eden区域空间
eden区空间最多不会超过设置的值 默认是60%
触发FGC场景
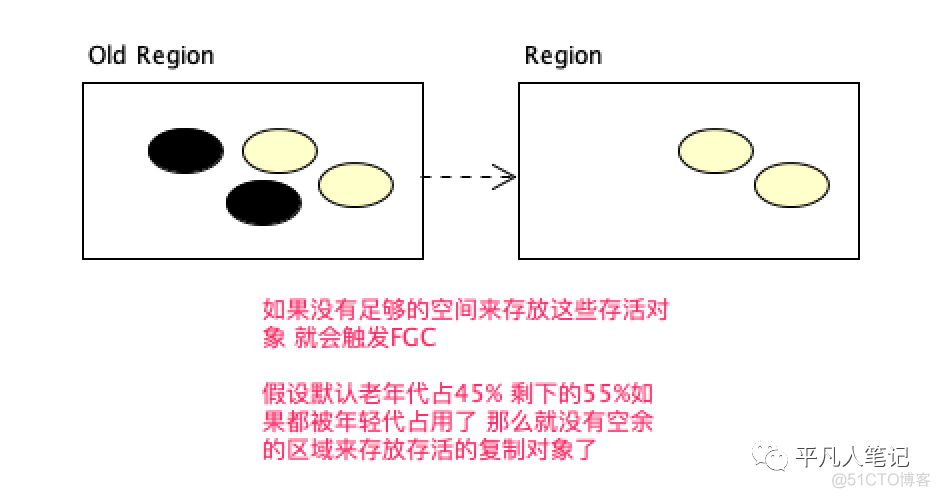
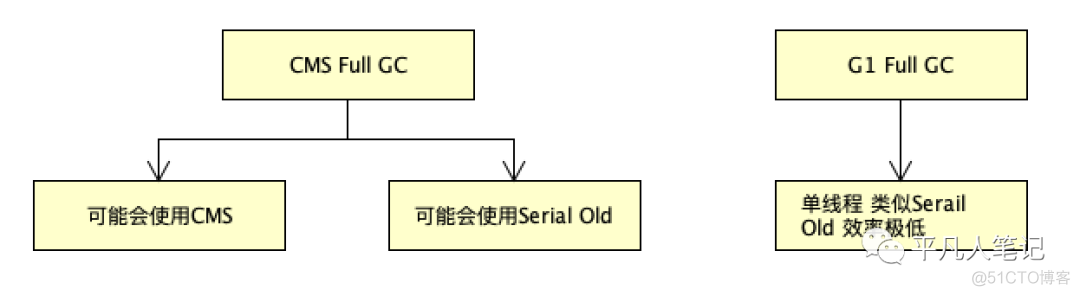
G1&CMS FGC垃圾收集器的选择 对比
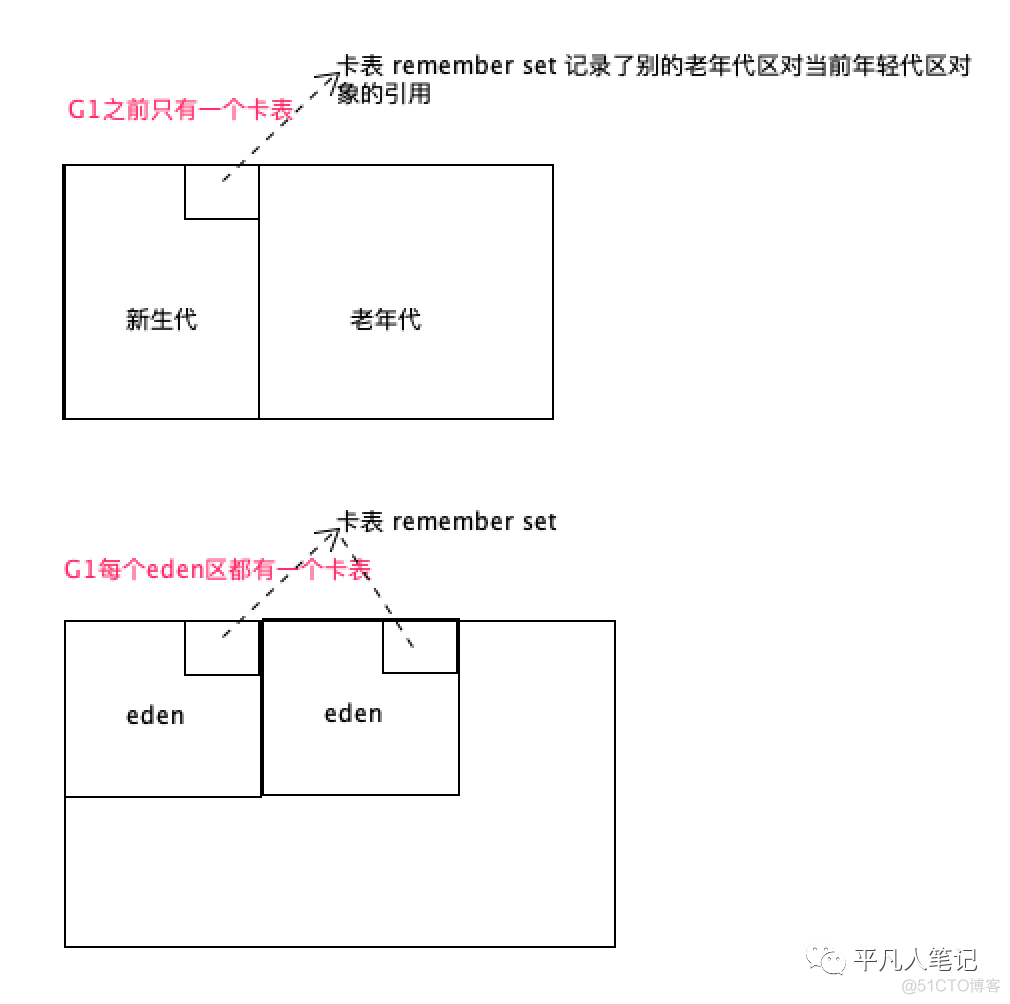
卡表
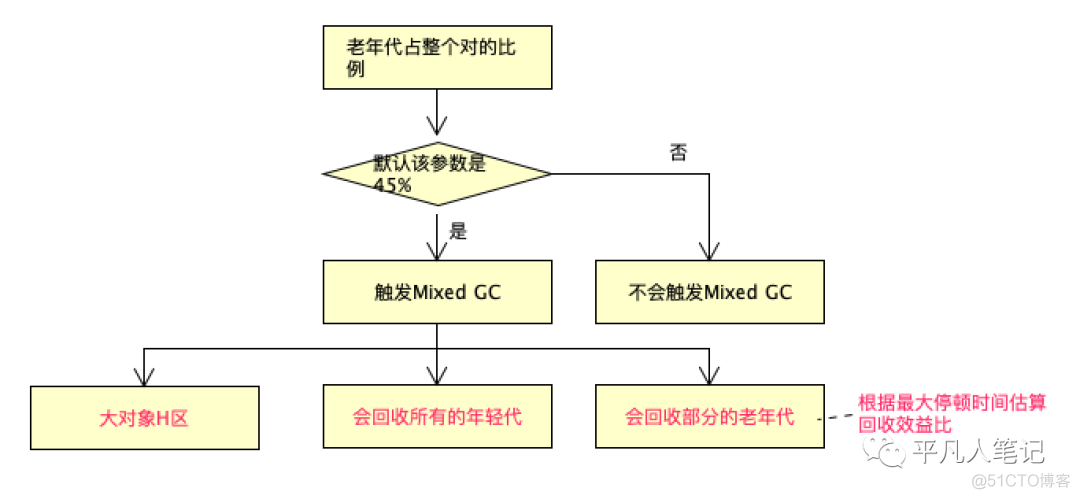
eden存活对象超过85%(该参数可以设置) 回收意义不大
一次回收过程中默认做8次筛选回收
筛选回收阶段 为了提升用户的体验 可以设置一次gc过程筛选回收的次数
假设有80%的垃圾需要回收
默认停顿时间200ms
g1不会一次性回收完
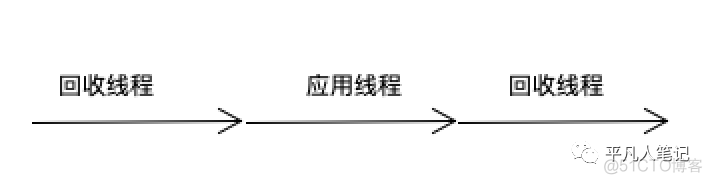
回收一次 回收线程暂停下 让应用线程执行
然后回收线程再执行
该过程是串行的 不是并发的
如果垃圾比较多的情况下 有必要把这个参数设置的大些
这样stw的时间就会短一些 用户体验会好一些
最大停顿时间设置
根据一次gc之后 有多少个对象可以存活 避免存活对象太多、太快进入老年代
垃圾收集器选择
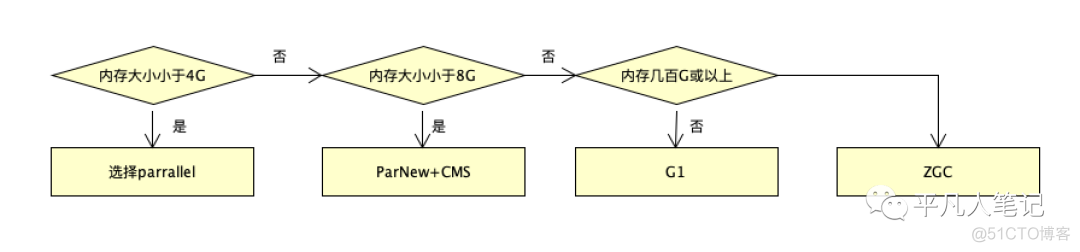
如果内存大小在4-8G JDK1.8用CMS效率是比G1要好
G1在jdk1.8版本算法性能不是最优
G1使用场景
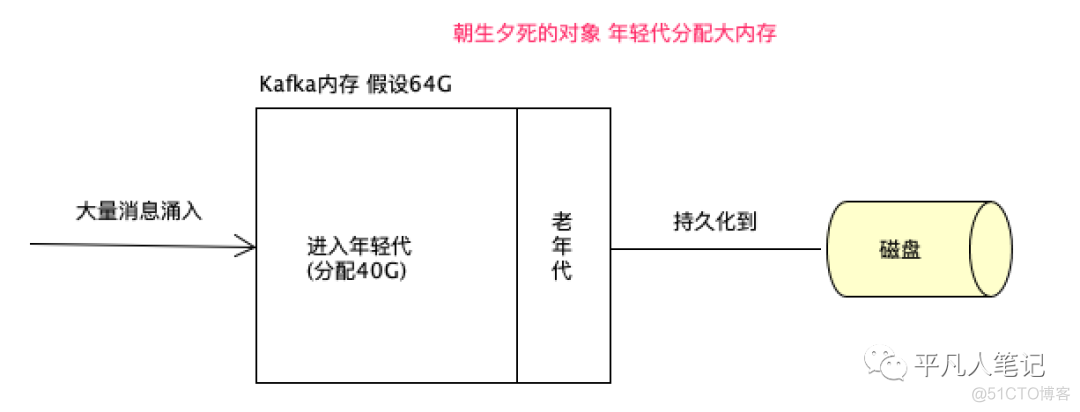
比如Kafaka 单机可以处理 上百万/s 并发
底层也是基于JVM
或者秒杀系统 一定得是大内存去部署 且使用G1垃圾收集器
Kafka线上推荐使用64G内存
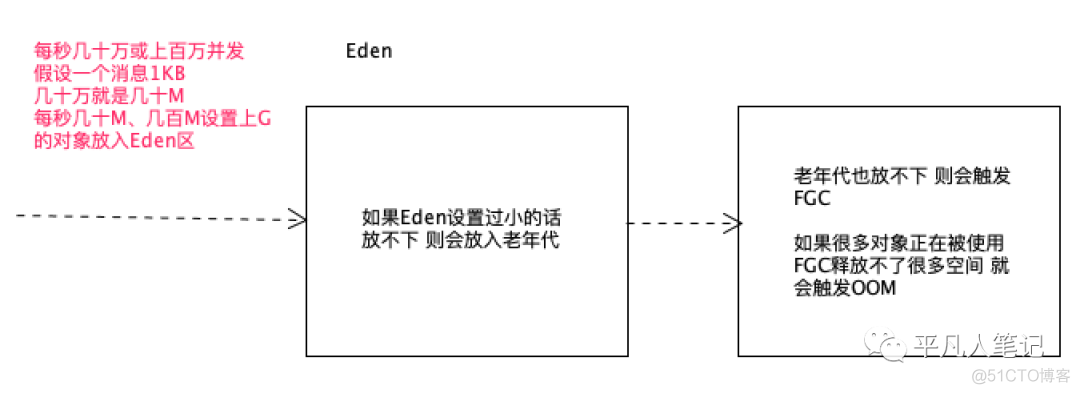
对于朝生夕死的对象 年轻代分配大些
对于Kafka来说 大部分对象在Minor GC都会被回收
Minor GC效率是否高?
对于几十G年轻代的Minor GC不一定比老年代的GC快
虽然老年代的收集算法比年轻代还要慢些
对于这种场景来说 不用G1,STW时间会很长
如果用G1则可以设置停顿时间 比如50毫秒 那每次可以回收几个G 边接受请求 边收集 用户体验会好很多 不会导致客户端发送消息超时的情况






.png)

.png)

