 云计算服务
云计算服务
 服务器租用
服务器租用
 DDOS 防护
DDOS 防护
 虚拟主机
虚拟主机
 域名服务
域名服务
 基础设施
基础设施
 关于我们
关于我们
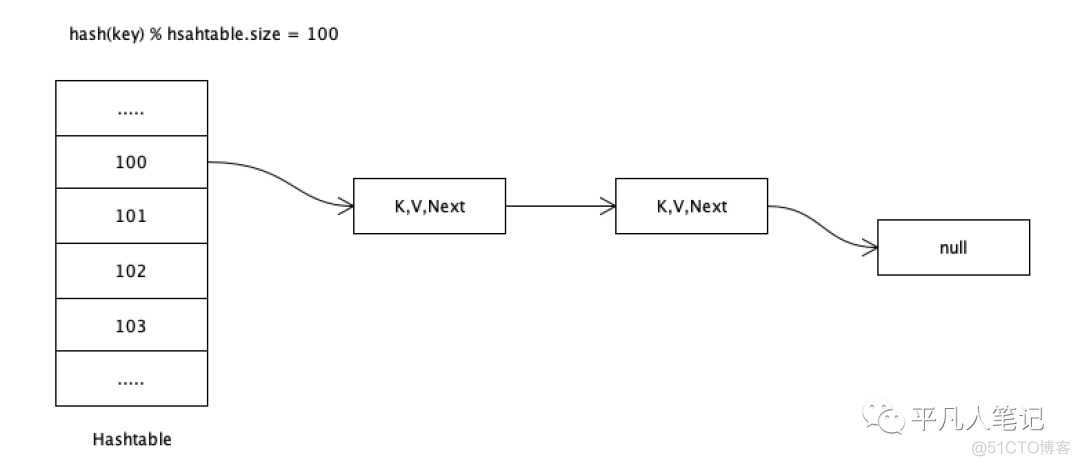
当链表越来越长,通过扩容的方式来减小链表长度
渐进式的搬数据

在搬数据的时候,每次都是获取老的hashtable中的第一个hash槽,然后按照该槽上的链表顺序一个一个的去搬。
redis通过后台轮循事件,每次搬数据的时候默认获取前100个hash槽,一次性搬有限个,目的是为了降低主线程的卡顿时间。
redis无论是多线程版本还是老的单线程版本,最终执行命令都是单线程,所以就不能一次性把数据搬完,而是渐进式的一点点搬。
同时存在2个hashtable怎么进行数据访问?
`redis可以存储的数据结构
•string•list•set•zset•hash•streamredis客户端可以把任意类型字面量的key传给服务端
redis的key可以是任意的数据类型,甚至可以是一个文件、音频、视屏。通过redis客户端把不同数据类型的key,传递给redis服务端,redis服务端把key转换成一个string对象即所有键都是string对象。
redis string源码怎么设计的在c语言中用char[] data数组来表示一个字符串,比如char[] data="pingfanrenbiji\0",c语言编译器还会在pingfanrenbiji后面加\0字符,作为字符串的结尾。但会有弊端,比如 data="dafasdasd\0dafadfa",正巧里面有一些特殊字符会导致数据直接截断,后面的就会被丢弃。
redis不是这种方式,而是自定义了一个数据结构SDS(simple dynamic string)
redis 3.2版本sds数据结构:
sds:
int len: 8
char[] buf="ping\0fan"
\0占一个字节
sds根据自定义长度来决定字符串是否结束,可以理解为这是一种二进制安全的数据结构。
int 占4个字节,无符号数据范围是2^32-1,这是几个亿的数据范围,在业务上根本不用上,所以有很大的内存空间的浪费。
redis 6.x sds数据结构
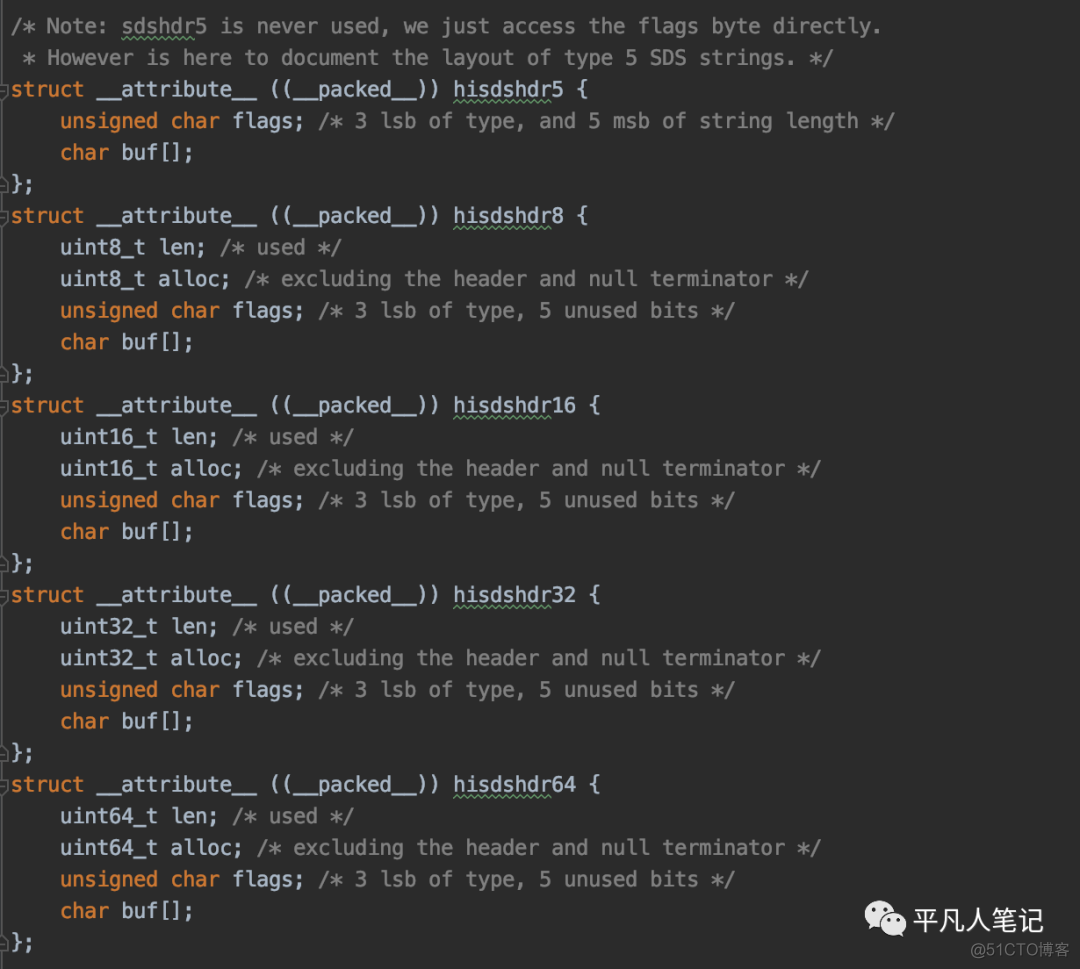
使用相对更小的空间去描述数据。
hdr是头部数据的意思,比如unsigned char flags;uint8_t len;这些都是头部数据,是用来描述真正业务数据的长度,不是真正的数据,而是一些描述信息。
char类型在c语言中占1个字节,在java中占2个字节。
真正的数据长度封装在了flags中
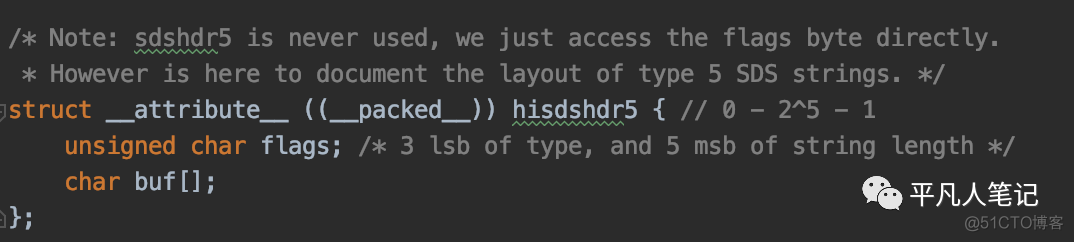
一个字节有8个bit位,其中后面5个bit位用来描述数据长度,前面3个bit作为数据类型。
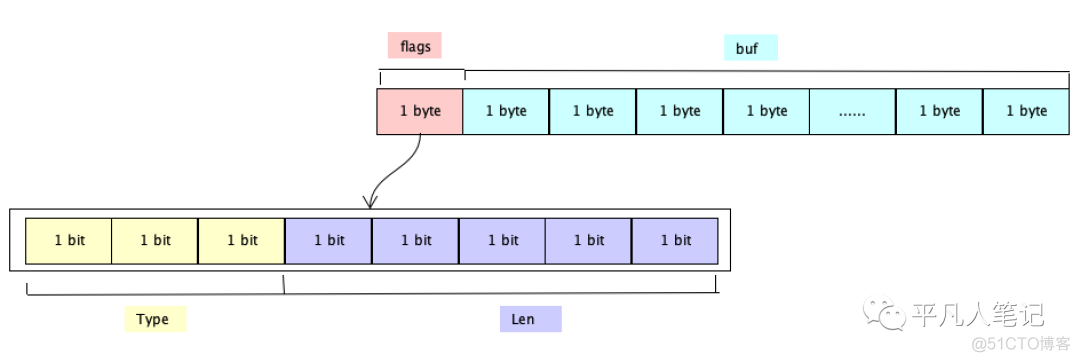
Type
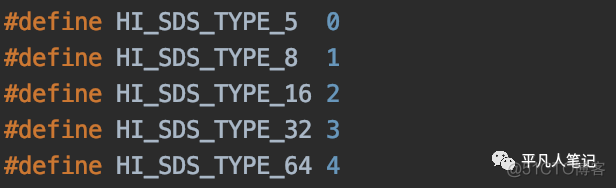
hisdshdr8
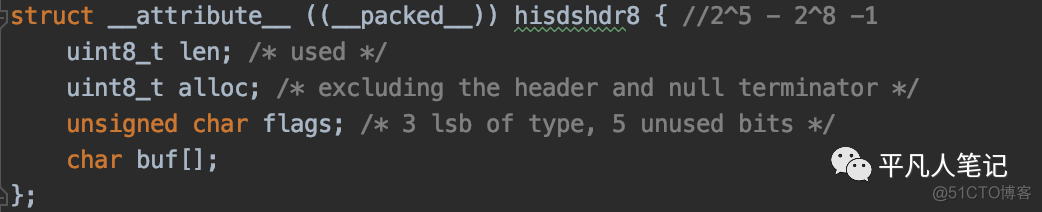
uint8_t代表占8个bit位一个字节。alloc是为了满足一种特殊的需求:
buffer数组一旦定义,空间大小不可变
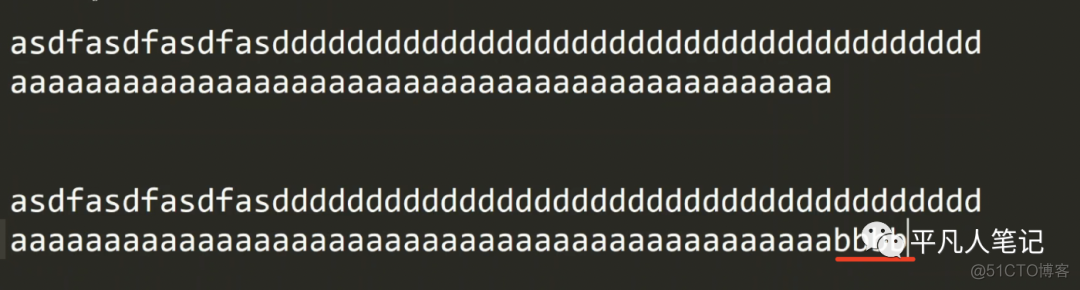
在上面那个字符串的基础上追加bbbb,需要重新开辟一个内存空间,再把数据拷贝过来,然后再追加字符串,这是一般的方法,很浪费内存空间,在redis 3.版本的sds中定义了一个int free字段和redis 6.x版本的uint8_t alloc含义是一样的,有了该字段就可以适用不同长度需求。
redis 3.2版本sds数据结构:
sds:
int len: 6
int free: 0
char[] buf="pingfa\0"
追加一个1
pingfa -> pingfa1
redis会自动分配6+1=7,7*2=14即一次性开辟14个空间
buf[14]=pingfa1
用掉了7还剩7即free=7
sds:
int len: 7
int free: 7
buf[14]=pingfa1
再追加23
pingfa1-> pingfa123
变成了
sds:
int len: 9
int free: 5
buf[14]=pingfa123
这样的话,不需要重新分配内存空间,数据量比较大的情况下,直接追加,效率提升很明显。
alloc分配多少空间,减去使用的,就是剩下的free。
动态字符串,自动的去扩容。
char[] buf="pingfa123\0"
redis编译器自动加上\0字符,尽量兼容c语言本身的函数库。
通过redis源码了解数据库设计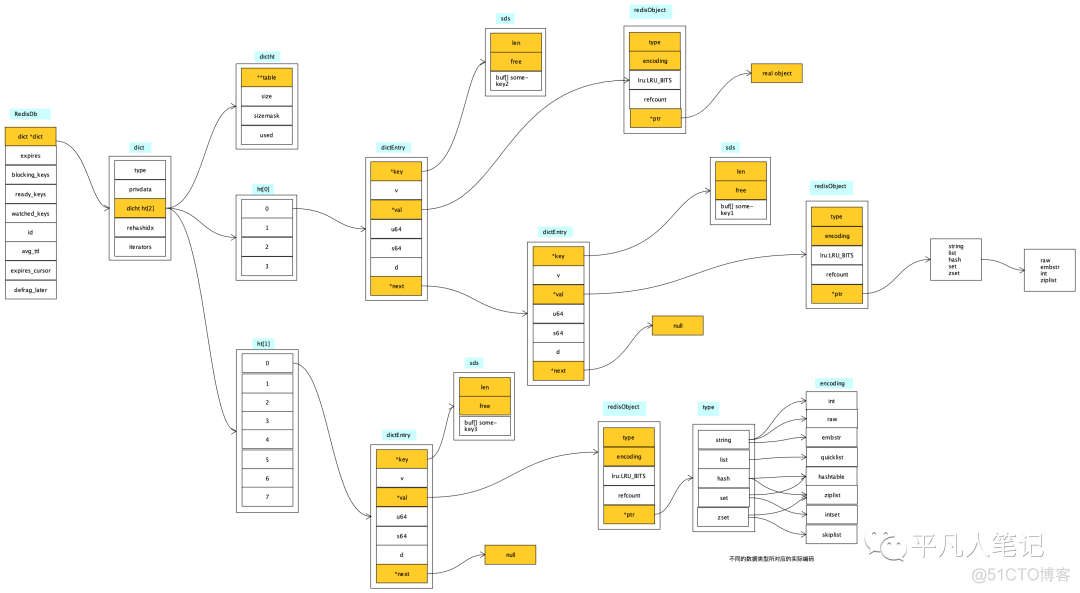 底层数据结构
底层数据结构 redisDb
redisDb
字典数据结构和hashmap是同一种数据类型,只是不同语言的不同实现。
•dict *expires过期时间处理
•dict *blocking_keys阻塞API,比如BLPOP是list中的阻塞api
•dict *ready_keys阻塞的key,在收到消息时,做对应的处理
•dict *watched_keys事务相关的命令
dict
ht 就是hashtable,因为需要rehash,所以数组长度是2,一个是老的hashtable,另外一个是新的hashtable,新的是老的hashtable大小的2倍。如果没有rehash的话,只会用到其中一个。
rehashidx 是rehash到每个hash槽的一个索引。
元素个数超过hashtable本身数组容量,就会触发rehash,首先申请大一倍的内存空间,渐进式的把数据从老的hashtable中搬到新的hashtable中,搬完之后,将老的hashtable释放掉,ht[0]指向新的数组,h[1]指向null,回到正常状态。
dictType
键key通过hashFunction这个hash函数计算并取模hashtable size,得到hash槽的位置。
如果2个key hashcode一样,如果2个key不一样,则是hash冲突,使用链表关联起来,如果2个key一样,则会覆盖。
dictht
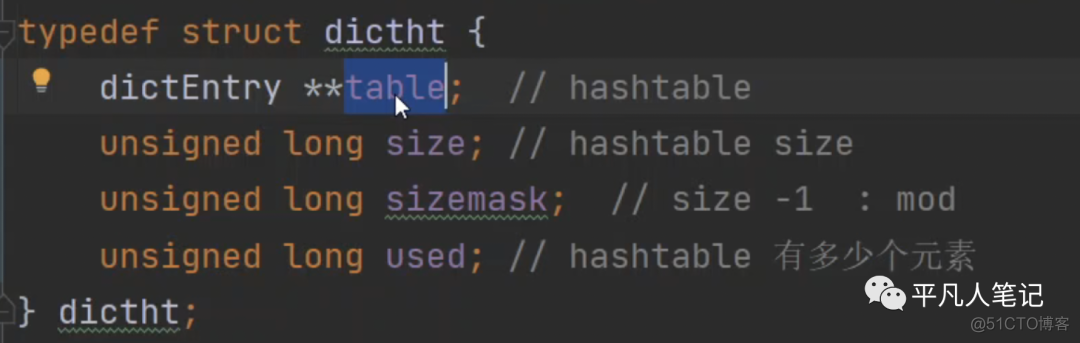
table指向了一个hash链表;sizemask是求模的一个优化;used是hashtable中有多少个元素。
dictEntry
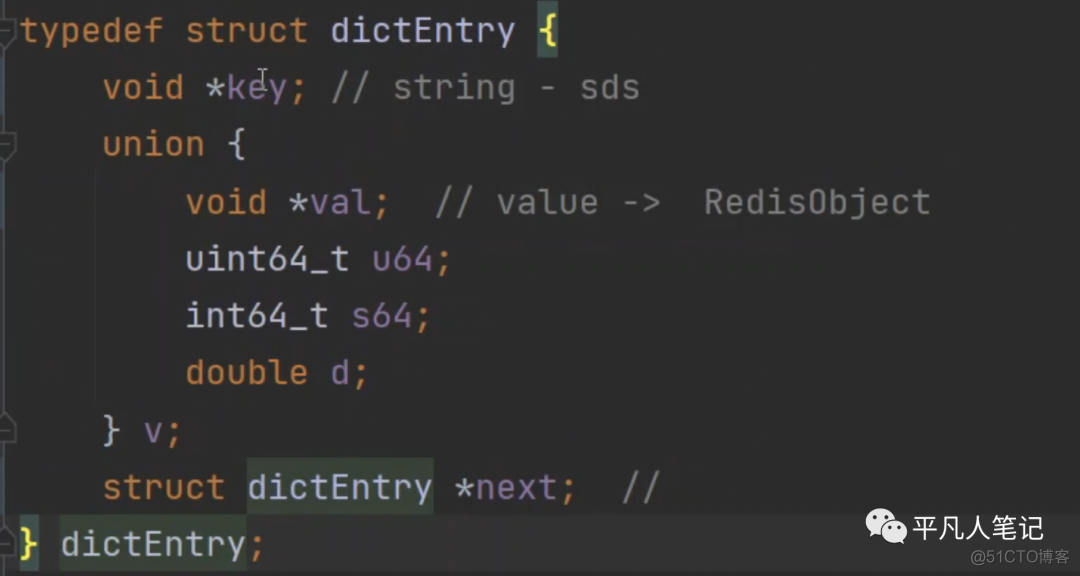
union中是value的类型,同一时间只能用一个;比如val就是key-value键值对类型,redis底层会进一步封装成redisObject对象;next指向链表中的下一个节点。
redisObject
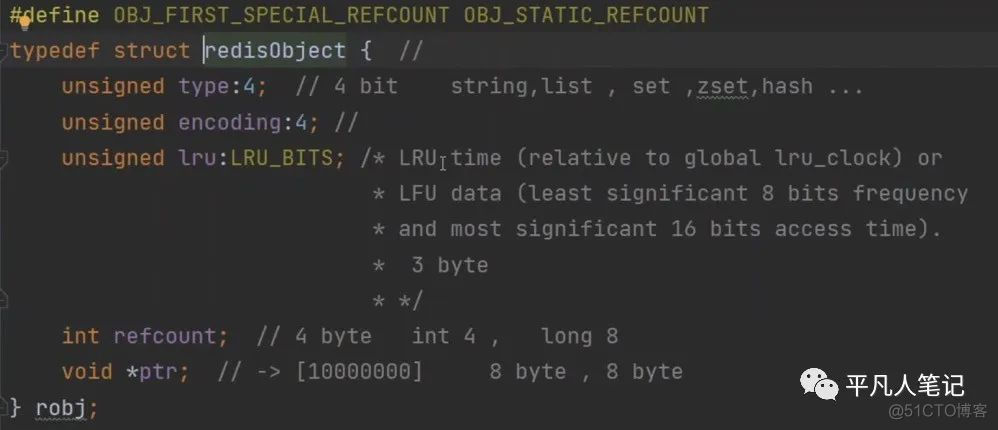
1、
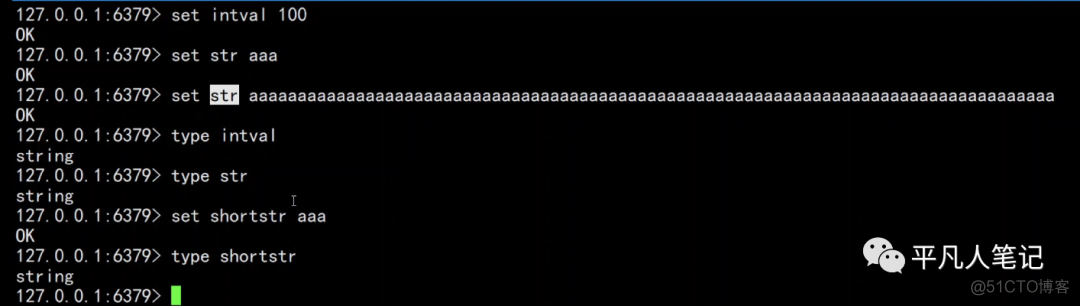
value是整数、短字符串、长字符串,底层都是string类型。
set操作,底层就会封装成一个string对象。
2、
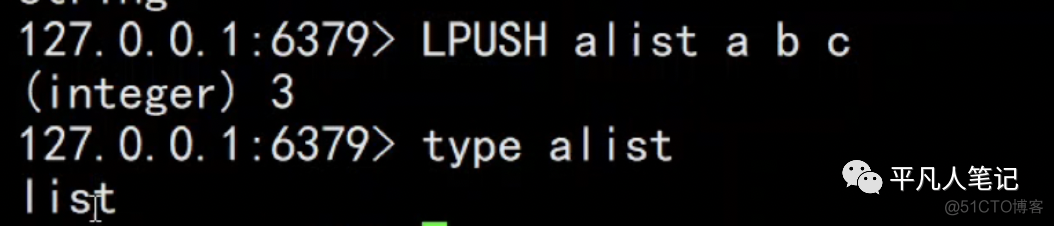
lpush操作,是list类型。list操作,底层会封装成一个list对象。
3、
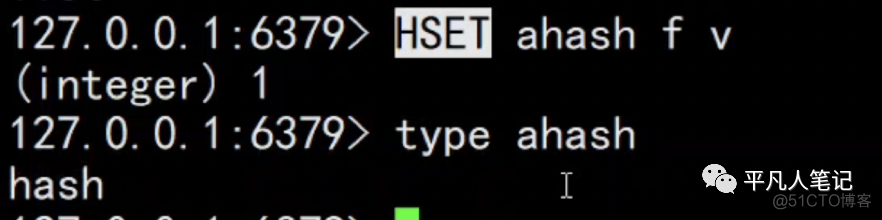
hset操作,是hash类型。set操作,底层会封住成一个hash对象。
•encoding每种类型底层有不同的编码。相同类型,底层编码也可能不相同即在内存中使用不同的方式去存储。
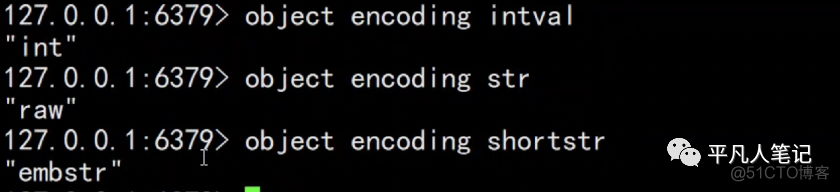
整数的编码是int,长字符串的编码是raw,短字符串的编码是embstr。


hash value短字符串底层编码是ziplist,hash value长字符串底层编码是hashtable。
•unsigned lru:LRU_BITS内存淘汰算法
#define LRU_BITS 24
在内存中占24个bit位
•int refcount引用计数法,判断对象是否存活的一种算法。
redis是c语言写的,需要自己的管理内存,该值为0,则可以把这个对象回收掉。
•void *ptr这是指向内存区域的指针
看redis底层把数据存储在哪里?
redis底层最终会把100这个值封装成redisObject,通过encoding知道编码是int,确定编码之后,通过ptr找到真实的数据。

整数一般不会超过8个字节,java中最长是long类型占8个字节。
ptr指针在64位操作系统中占8个字节空间。
假设这个数据能用整型去表示,那也能用指针去表示,不让指针去存储真实的位置信息,而是直接存整数,是否可以?
ptr指向一个额外的内存空间,用额外的内存空间去存储整数的话,会导致什么问题?
•需要一个内存空间来存储数据•先找到redisObject,通过ptr指针做一次io操作才能拿到真实的数据如果直接用指针存储数据,有什么好处呢?
•减少了额外的内存空间来存储数据•拿到redisObject中的ptr可以直接得到数据了,就不需要再通过ptr指针从内存中获取真实数据了,减少了一次io操作





.png)

.png)

